TIC-VLA: A Think-in-Control Vision-Language-Action Model for Robot Navigation in Dynamic Environments
作者: Zhiyu Huang, Yun Zhang, Johnson Liu, Rui Song, Chen Tang, Jiaqi Ma
分类: cs.RO
发布日期: 2026-02-02
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
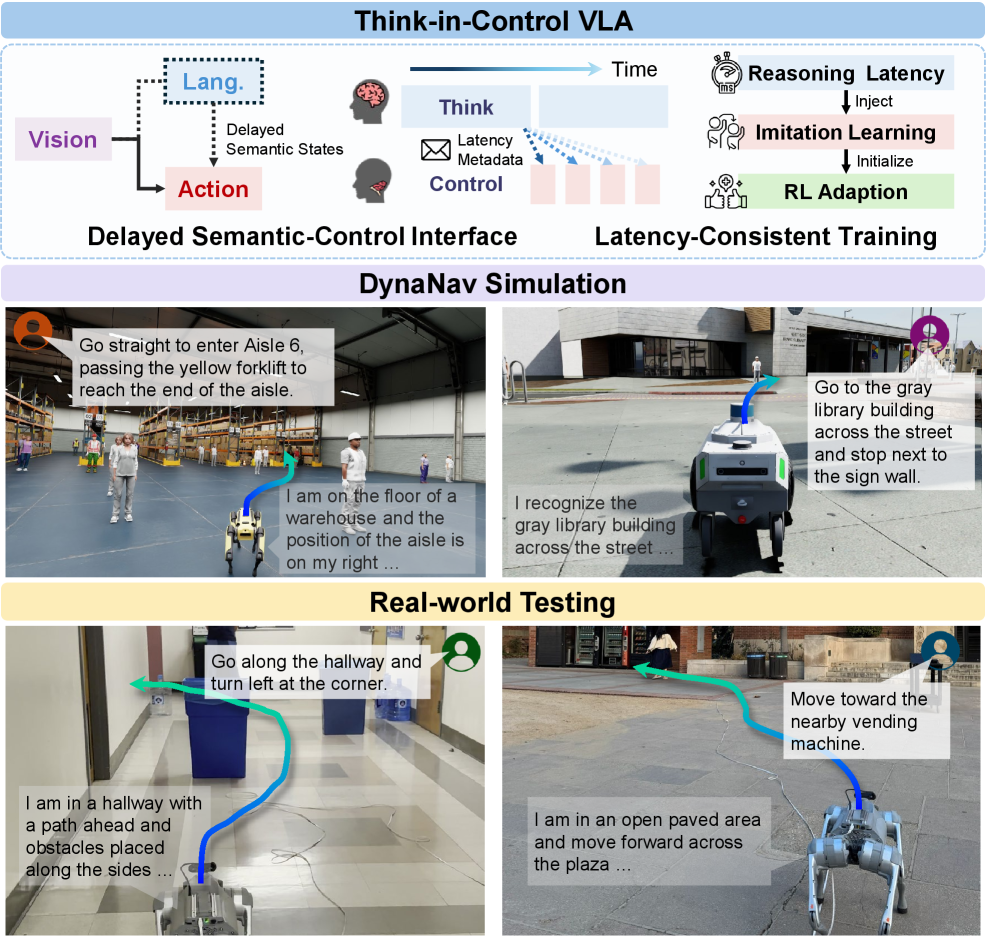
提出TIC-VLA模型,解决动态环境中机器人导航的语义推理延迟问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人导航 视觉语言动作模型 延迟感知 动态环境 模仿学习 强化学习 异步推理 DynaNav
📋 核心要点
- 现有VLA模型在动态环境中进行机器人导航时,忽略了语义推理相对于实时动作的固有延迟,导致性能下降。
- TIC-VLA通过引入延迟语义控制接口,并结合延迟元数据,使机器人能够感知并补偿推理延迟,从而实现更鲁棒的导航。
- DynaNav模拟环境和实验结果表明,TIC-VLA在推理延迟下优于现有VLA模型,并在真实机器人上验证了其有效性。
📝 摘要(中文)
本文提出了一种名为Think-in-Control (TIC)-VLA的延迟感知框架,用于解决动态、以人为中心的环境中机器人语言引导导航问题。该框架显式地对动作生成过程中延迟的语义推理进行建模。TIC-VLA定义了一个延迟的语义控制接口,该接口基于延迟的视觉-语言语义状态和显式延迟元数据以及当前观察来调节动作生成,从而使策略能够补偿异步推理。此外,本文还提出了一种延迟一致的训练流程,该流程在模仿学习和在线强化学习期间注入推理延迟,使训练与异步部署保持一致。为了支持真实的评估,本文提出了DynaNav,这是一个用于动态环境中语言引导导航的物理精确、照片逼真的模拟套件。大量的模拟和真实机器人实验表明,TIC-VLA始终优于先前的VLA模型,同时在多秒推理延迟下保持了强大的实时控制。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在动态环境中进行机器人导航时,通常假设语义推理和动作控制是时间对齐的。然而,语义推理本质上存在延迟,这导致机器人无法及时响应环境变化,尤其是在高延迟情况下,严重影响导航性能。现有方法没有充分考虑这种延迟,导致其在实际应用中表现不佳。
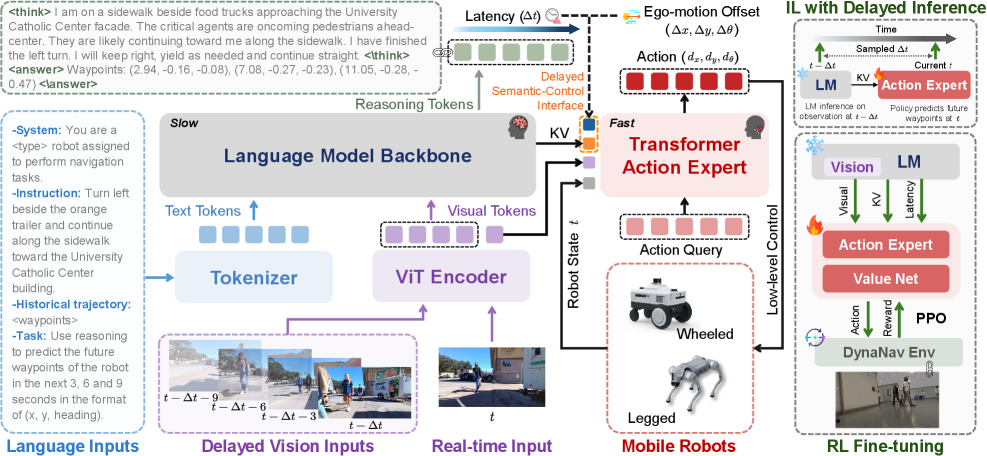
核心思路:TIC-VLA的核心思路是显式地建模和补偿语义推理的延迟。通过引入一个延迟语义控制接口,将延迟的视觉-语言语义状态和延迟元数据作为动作生成的条件,使机器人能够感知并预测延迟的影响。这样,机器人就可以根据过去的语义信息和当前的观察,做出更明智的决策,从而提高导航的鲁棒性和效率。
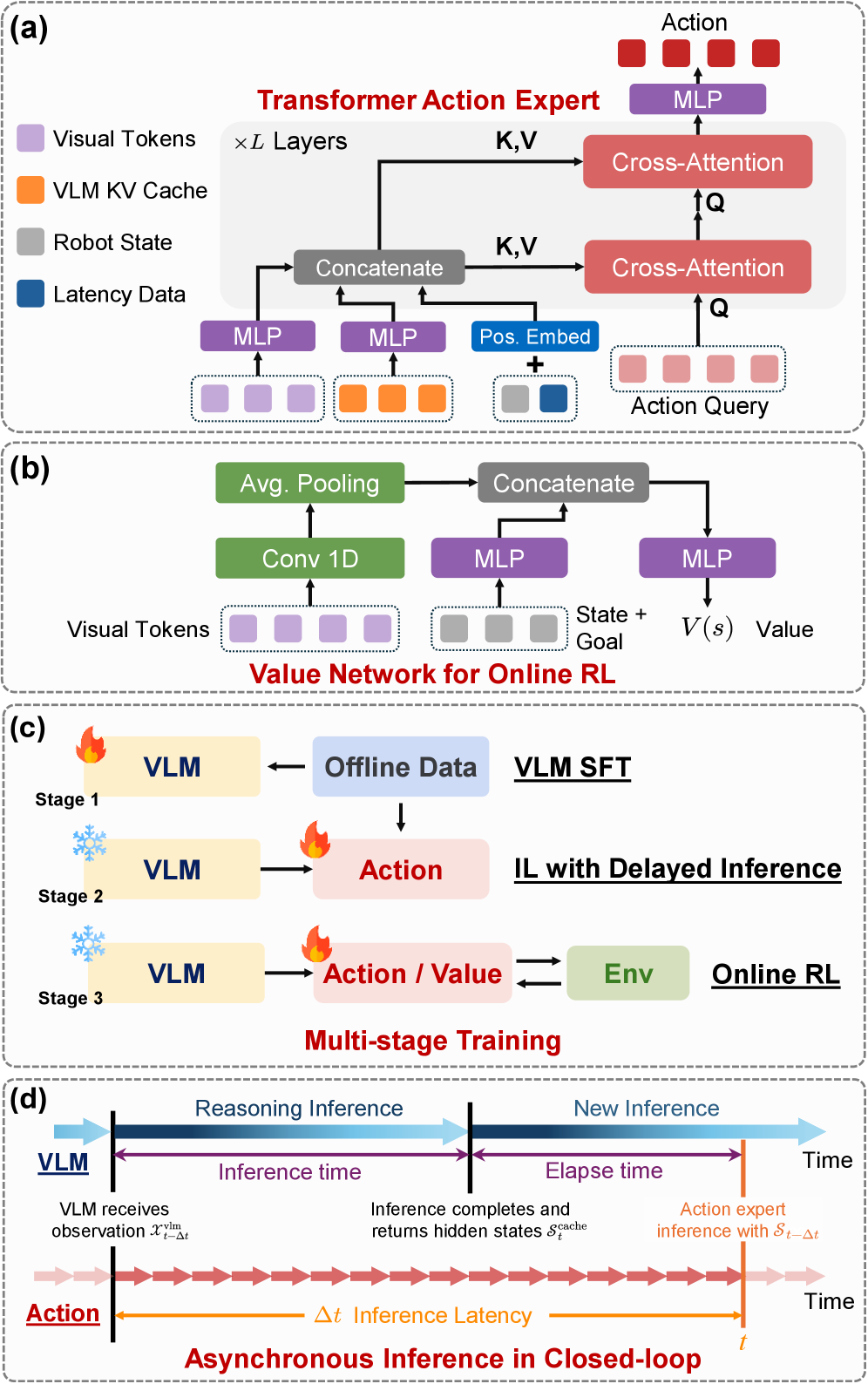
技术框架:TIC-VLA框架主要包含三个部分:视觉-语言语义编码器、延迟语义控制接口和动作生成器。视觉-语言语义编码器负责将视觉输入和语言指令编码成语义状态。延迟语义控制接口接收编码后的语义状态和延迟元数据,并将其传递给动作生成器。动作生成器根据当前的观察和延迟的语义信息,生成机器人的动作指令。此外,该框架还包含一个延迟一致的训练流程,通过在训练过程中注入推理延迟,使模型能够更好地适应实际部署中的异步推理。
关键创新:TIC-VLA的关键创新在于其延迟感知的语义控制接口和延迟一致的训练流程。传统的VLA模型忽略了语义推理的延迟,而TIC-VLA通过显式地建模延迟,使机器人能够更好地理解和响应环境变化。延迟一致的训练流程确保了模型在训练和部署之间的一致性,从而提高了模型的泛化能力和鲁棒性。
关键设计:延迟语义控制接口的关键设计在于如何有效地表示和利用延迟信息。论文中使用了延迟元数据,包括延迟的时间戳和延迟的置信度,来表示延迟的程度和可靠性。动作生成器使用一个循环神经网络(RNN)来处理时间序列数据,并根据当前的观察和延迟的语义信息,生成机器人的动作指令。损失函数包括模仿学习损失和强化学习损失,用于优化模型的性能。延迟一致的训练流程通过随机注入不同程度的延迟,使模型能够适应不同的延迟情况。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TIC-VLA在DynaNav模拟环境中显著优于现有的VLA模型,尤其是在高延迟情况下。例如,在3秒延迟下,TIC-VLA的成功率比基线模型提高了20%以上。此外,在真实机器人实验中,TIC-VLA也表现出更强的鲁棒性和适应性,能够成功完成复杂的导航任务。
🎯 应用场景
TIC-VLA模型在动态环境中具有广泛的应用前景,例如服务型机器人、自动驾驶汽车和智能家居等。该模型可以使机器人在复杂和不确定的环境中更好地理解人类指令并做出相应的动作,从而提高机器人的自主性和安全性。此外,该模型还可以应用于其他需要实时控制和语义理解的领域,例如工业自动化和医疗机器人。
📄 摘要(原文)
Robots in dynamic, human-centric environments must follow language instructions while maintaining real-time reactive control. Vision-language-action (VLA) models offer a promising framework, but they assume temporally aligned reasoning and control, despite semantic inference being inherently delayed relative to real-time action. We introduce Think-in-Control (TIC)-VLA, a latency-aware framework that explicitly models delayed semantic reasoning during action generation. TIC-VLA defines a delayed semantic-control interface that conditions action generation on delayed vision-language semantic states and explicit latency metadata, in addition to current observations, enabling policies to compensate for asynchronous reasoning. We further propose a latency-consistent training pipeline that injects reasoning inference delays during imitation learning and online reinforcement learning, aligning training with asynchronous deployment. To support realistic evaluation, we present DynaNav, a physics-accurate, photo-realistic simulation suite for language-guided navigation in dynamic environments. Extensive experiments in simulation and on a real robot show that TIC-VLA consistently outperforms prior VLA models while maintaining robust real-time control under multi-second reasoning latency. Project website: https://ucla-mobility.github.io/TIC-VLA/