World-Gymnast: Training Robots with Reinforcement Learning in a World Model
作者: Ansh Kumar Sharma, Yixiang Sun, Ninghao Lu, Yunzhe Zhang, Jiarao Liu, Sherry Yang
分类: cs.RO, cs.AI
发布日期: 2026-02-02
备注: https://world-gymnast.github.io/
💡 一句话要点
World-Gymnast:利用世界模型中的强化学习训练机器人,提升泛化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 强化学习 世界模型 视觉-语言模型 sim-to-real 策略学习 机器人控制
📋 核心要点
- 现有机器人学习方法受限于物理交互成本、专家数据量和sim-to-real差距,难以实现泛化。
- World-Gymnast利用动作条件视频世界模型进行策略rollout,并用视觉-语言模型奖励,实现高效的RL微调。
- 实验表明,World-Gymnast显著优于有监督微调和软件模拟器,并展现了在新场景下的训练能力。
📝 摘要(中文)
与物理世界交互的机器人学习受到物理交互成本的限制。有监督微调(SFT)和基于软件模拟器的强化学习(RL)分别受限于专家数据量和操作任务的sim-to-real差距。本文提出World-Gymnast,通过在动作条件视频世界模型中进行策略rollout,并使用视觉-语言模型(VLM)奖励rollout,对视觉-语言-动作(VLA)策略进行RL微调。在Bridge机器人平台上,World-Gymnast的性能优于SFT高达18倍,优于软件模拟器高达2倍。更重要的是,World-Gymnast展示了RL与世界模型结合的强大能力,包括在来自世界模型的多样化语言指令和新场景上进行训练,在新场景中进行测试时训练,以及在线迭代世界模型和策略改进。结果表明,学习世界模型并在云端训练机器人策略可能是弥合演示机器人与能够服务于家庭的机器人之间差距的关键。
🔬 方法详解
问题定义:现有机器人学习方法,如模仿学习和强化学习,在真实机器人上的应用面临诸多挑战。模仿学习依赖大量专家数据,且泛化能力有限;强化学习在真实环境中训练成本高昂。软件模拟器虽然降低了训练成本,但sim-to-real差距导致策略难以迁移到真实世界。因此,如何高效地训练具有良好泛化能力的机器人策略是一个关键问题。
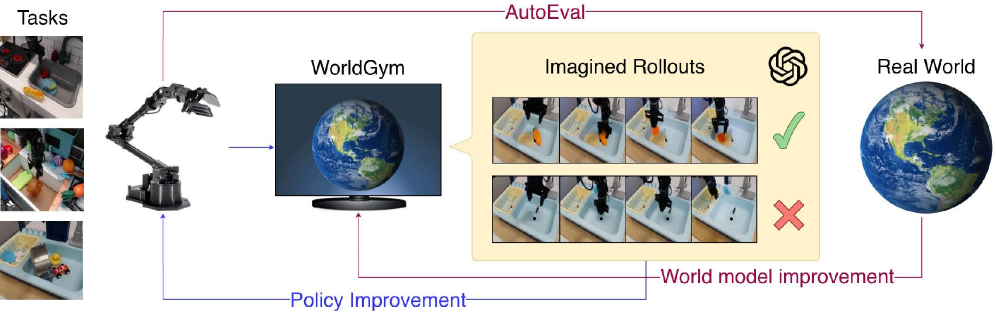
核心思路:World-Gymnast的核心思路是利用世界模型来模拟真实环境,并在该模型中进行强化学习。通过学习真实世界的视频-动作数据,世界模型能够预测机器人在不同动作下的未来状态。然后,利用强化学习算法在世界模型中训练机器人策略,从而避免了与真实环境的直接交互,降低了训练成本。同时,利用视觉-语言模型(VLM)作为奖励函数,可以引导机器人完成复杂的视觉-语言任务。
技术框架:World-Gymnast包含三个主要模块:1) 动作条件视频世界模型:用于模拟真实环境,预测机器人在给定动作下的未来状态。2) 视觉-语言-动作(VLA)策略:用于控制机器人的动作,根据视觉输入和语言指令生成相应的动作。3) 视觉-语言模型(VLM):用于评估机器人的行为,根据视觉输入和语言指令给出奖励信号。整体流程是:首先,VLA策略在世界模型中执行动作,世界模型预测下一个状态。然后,VLM根据当前状态和语言指令给出奖励信号。最后,利用强化学习算法,根据奖励信号更新VLA策略。
关键创新:World-Gymnast的关键创新在于将世界模型与强化学习相结合,实现高效的机器人策略训练。与传统的强化学习方法相比,World-Gymnast不需要与真实环境进行交互,降低了训练成本。与模仿学习方法相比,World-Gymnast可以通过强化学习算法探索更优的策略,提高泛化能力。此外,利用视觉-语言模型作为奖励函数,可以引导机器人完成复杂的视觉-语言任务。
关键设计:动作条件视频世界模型采用Transformer架构,用于预测未来视频帧。VLA策略采用Transformer架构,将视觉输入和语言指令编码为向量,然后解码为动作。VLM采用预训练的视觉-语言模型,例如CLIP,用于评估机器人的行为。强化学习算法采用PPO算法,用于更新VLA策略。奖励函数的设计至关重要,需要平衡任务完成的准确性和效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,World-Gymnast在Bridge机器人平台上显著优于有监督微调(SFT)和软件模拟器。World-Gymnast的性能比SFT高出18倍,比软件模拟器高出2倍。此外,World-Gymnast还展示了在新场景中进行训练的能力,以及在线迭代世界模型和策略改进的能力。这些结果表明,World-Gymnast是一种有效的机器人策略训练方法。
🎯 应用场景
World-Gymnast具有广泛的应用前景,例如家庭服务机器人、工业自动化机器人、医疗机器人等。它可以帮助机器人更好地理解人类指令,并在复杂环境中完成各种任务。通过不断学习和改进世界模型,机器人可以适应新的环境和任务,提高其智能化水平。该研究有望推动机器人技术的发展,使机器人能够更好地服务于人类。
📄 摘要(原文)
Robot learning from interacting with the physical world is fundamentally bottlenecked by the cost of physical interaction. The two alternatives, supervised finetuning (SFT) from expert demonstrations and reinforcement learning (RL) in a software-based simulator, are limited by the amount of expert data available and the sim-to-real gap for manipulation. With the recent emergence of world models learned from real-world video-action data, we ask the question of whether training a policy in a world model can be more effective than supervised learning or software simulation in achieving better real-robot performance. We propose World-Gymnast, which performs RL finetuning of a vision-language-action (VLA) policy by rolling out the policy in an action-conditioned video world model and rewarding the rollouts with a vision-language model (VLM). On the Bridge robot setup, World-Gymnast outperforms SFT by as much as 18x and outperforms software simulator by as much as 2x. More importantly, World-Gymnast demonstrates intriguing capabilities of RL with a world model, including training on diverse language instructions and novel scenes from the world model, test-time training in a novel scene, and online iterative world model and policy improvement. Our results suggest learning a world model and training robot policies in the cloud could be the key to bridging the gap between robots that work in demonstrations and robots that can work in anyone's household.