PRISM: Performer RS-IMLE for Single-pass Multisensory Imitation Learning
作者: Amisha Bhaskar, Pratap Tokekar, Stefano Di Cairano, Alexander Schperberg
分类: cs.RO, cs.LG
发布日期: 2026-02-02
备注: 10 pages main text and 4 figures, and 11 pages appendix and 10 figures, total 21 pages and 14 figures
💡 一句话要点
PRISM:基于Performer RS-IMLE的单程多感官模仿学习策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模仿学习 多模态融合 机器人控制 隐式最大似然估计 Performer 拒绝采样 实时控制
📋 核心要点
- 现有模仿学习方法难以兼顾多模态输入、实时控制和多模态动作分布建模,限制了其在复杂机器人任务中的应用。
- PRISM提出了一种基于批量全局拒绝采样的IMLE变体,结合多感官编码器和Performer架构,实现高效的单程策略。
- 实验表明,PRISM在真实机器人和模拟环境中均优于现有扩散模型和流匹配方法,成功率提升显著,轨迹抖动降低。
📝 摘要(中文)
机器人模仿学习通常需要模型能够捕捉多模态动作分布,同时以实时控制速率运行并适应多种传感模态。尽管最近的生成方法,如扩散模型、流匹配和隐式最大似然估计(IMLE)已经取得了有希望的结果,但它们通常只满足这些要求的一部分。为了解决这个问题,我们引入了PRISM,一种基于IMLE的批量全局拒绝采样变体的单程策略。PRISM将时间多感官编码器(集成RGB、深度、触觉、音频和本体感觉)与使用Performer架构的线性注意力生成器相结合。我们在一套多样化的真实世界硬件套件上展示了PRISM的有效性,包括使用带有7自由度手臂D1的Unitree Go2进行loco-manipulation,以及使用UR5机械臂进行桌面操作。在诸如预操作停车、高精度插入和多对象拾取和放置等具有挑战性的物理任务中,PRISM的成功率比最先进的扩散策略高出10-25%,同时保持高频(30-50 Hz)闭环控制。我们进一步在包括CALVIN、MetaWorld和Robomimic在内的大规模模拟基准上验证了我们的方法。在CALVIN(10%数据分割)中,PRISM的成功率比扩散提高了约25%,比流匹配提高了约20%,同时将轨迹抖动降低了20x-50x。这些结果使PRISM成为一种快速、准确和多感官的模仿策略,它保留了多模态动作覆盖,而没有迭代采样的延迟。
🔬 方法详解
问题定义:现有模仿学习方法在处理多模态数据时,往往难以同时满足实时性、准确性和对多模态动作分布的建模能力。扩散模型等方法虽然在生成能力上表现出色,但计算复杂度高,难以满足实时控制的需求。此外,如何有效融合来自不同传感器的信息,并将其转化为高质量的动作指令,也是一个挑战。
核心思路:PRISM的核心思路是利用隐式最大似然估计(IMLE)的优势,通过批量全局拒绝采样的方式,实现高效的单程策略。这种方法避免了迭代采样带来的延迟,同时能够捕捉多模态动作分布。结合Performer架构的线性注意力机制,可以有效处理长时序依赖关系,并降低计算复杂度。
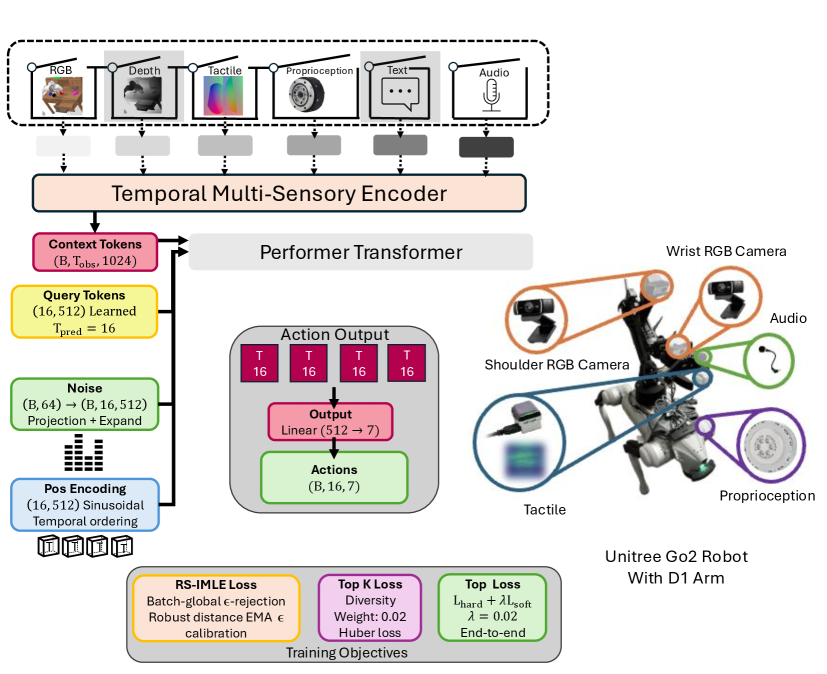
技术框架:PRISM的整体框架包括一个多感官编码器和一个线性注意力生成器。多感官编码器负责将来自RGB、深度、触觉、音频和本体感觉等多种传感器的信息进行融合,并提取出有效的特征表示。线性注意力生成器则基于这些特征表示,生成相应的动作指令。该生成器采用Performer架构,利用其高效的注意力机制,实现快速的动作生成。
关键创新:PRISM的关键创新在于其基于批量全局拒绝采样的IMLE变体。传统的IMLE方法需要进行多次迭代采样,才能得到高质量的动作指令。而PRISM通过批量全局拒绝采样,可以在单次采样中获得高质量的动作指令,从而大大提高了效率。此外,PRISM还采用了Performer架构的线性注意力机制,进一步降低了计算复杂度。
关键设计:PRISM的多感官编码器采用了时间卷积网络(TCN)来处理时序数据,并使用注意力机制来融合不同模态的信息。线性注意力生成器采用了Performer架构,其注意力机制的复杂度为O(n),其中n为序列长度。损失函数采用了IMLE损失,用于衡量生成动作与专家动作之间的差异。批量大小和拒绝采样的阈值是影响性能的关键参数,需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
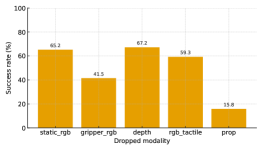
PRISM在真实机器人任务中,如预操作停车、高精度插入和多对象拾取和放置,成功率比最先进的扩散策略高出10-25%,同时保持30-50 Hz的闭环控制频率。在CALVIN数据集上,PRISM的成功率比扩散模型提高了约25%,比流匹配提高了约20%,同时将轨迹抖动降低了20x-50x。
🎯 应用场景
PRISM具有广泛的应用前景,可应用于各种需要多模态感知和实时控制的机器人任务中,例如自动驾驶、智能制造、医疗机器人等。该研究成果有助于提升机器人在复杂环境中的适应性和智能化水平,实现更安全、高效的人机协作。
📄 摘要(原文)
Robotic imitation learning typically requires models that capture multimodal action distributions while operating at real-time control rates and accommodating multiple sensing modalities. Although recent generative approaches such as diffusion models, flow matching, and Implicit Maximum Likelihood Estimation (IMLE) have achieved promising results, they often satisfy only a subset of these requirements. To address this, we introduce PRISM, a single-pass policy based on a batch-global rejection-sampling variant of IMLE. PRISM couples a temporal multisensory encoder (integrating RGB, depth, tactile, audio, and proprioception) with a linear-attention generator using a Performer architecture. We demonstrate the efficacy of PRISM on a diverse real-world hardware suite, including loco-manipulation using a Unitree Go2 with a 7-DoF arm D1 and tabletop manipulation with a UR5 manipulator. Across challenging physical tasks such as pre-manipulation parking, high-precision insertion, and multi-object pick-and-place, PRISM outperforms state-of-the-art diffusion policies by 10-25% in success rate while maintaining high-frequency (30-50 Hz) closed-loop control. We further validate our approach on large-scale simulation benchmarks, including CALVIN, MetaWorld, and Robomimic. In CALVIN (10% data split), PRISM improves success rates by approximately 25% over diffusion and approximately 20% over flow matching, while simultaneously reducing trajectory jerk by 20x-50x. These results position PRISM as a fast, accurate, and multisensory imitation policy that retains multimodal action coverage without the latency of iterative sampling.