TTT-Parkour: Rapid Test-Time Training for Perceptive Robot Parkour
作者: Shaoting Zhu, Baijun Ye, Jiaxuan Wang, Jiakang Chen, Ziwen Zhuang, Linzhan Mou, Runhan Huang, Hang Zhao
分类: cs.RO, cs.AI
发布日期: 2026-02-02
备注: Project Page: https://ttt-parkour.github.io/
💡 一句话要点
提出TTT-Parkour以解决机器人在复杂地形上动态运动问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人技术 动态运动 测试时训练 复杂地形 几何重建 人形机器人 模拟到真实转移
📋 核心要点
- 现有的运动策略在面对复杂和未知的地形时,表现出较大的局限性,难以适应高度动态的环境。
- 本文提出了一种真实-模拟-真实的框架,通过快速测试时训练,提升机器人在新颖地形上的运动能力。
- 实验结果显示,经过测试时训练的策略在零-shot的模拟到真实转移能力上表现出色,能够有效应对复杂障碍物。
📝 摘要(中文)
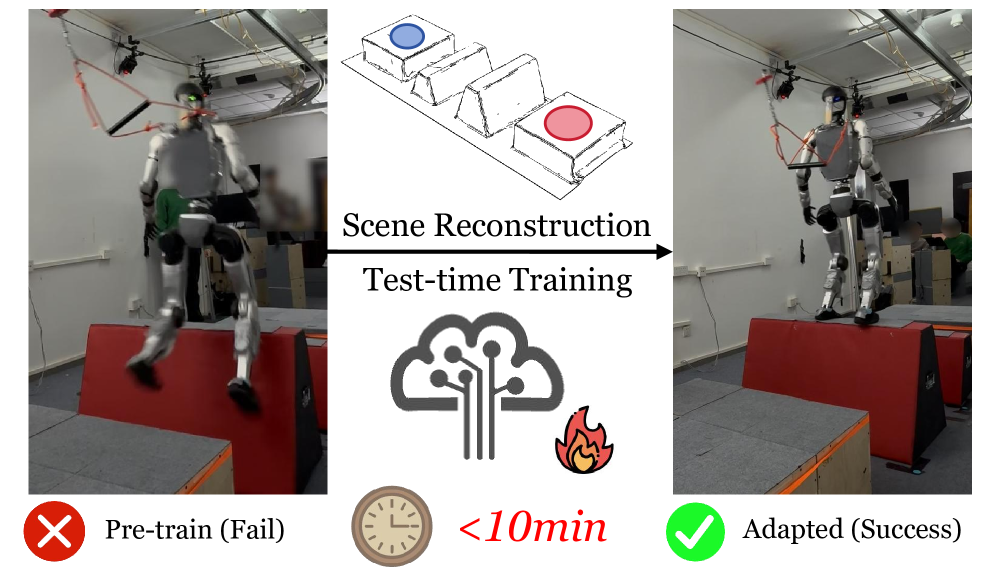
在机器人技术中,实现高度动态的人形机器人在未知复杂地形上的跑酷仍然是一个挑战。尽管现有的通用运动策略在广泛的地形分布上表现出一定能力,但在任意且极具挑战性的环境中往往难以应对。为了解决这一限制,本文提出了一种真实-模拟-真实的框架,利用快速测试时训练(TTT)在新颖地形上显著增强机器人的穿越能力。我们采用了一个两阶段的端到端学习范式:首先在多样化的程序生成地形上进行预训练,然后在从真实世界捕获的高保真网格上进行快速微调。我们开发了一种高效的几何重建管道,确保在测试时训练过程中的速度和质量。实验表明,TTT-Parkour使人形机器人能够掌握复杂障碍物的穿越能力。
🔬 方法详解
问题定义:本文旨在解决人形机器人在未知复杂地形上进行动态运动的挑战。现有方法在高度动态和复杂环境中表现不佳,难以适应多样化的地形。
核心思路:提出一种真实-模拟-真实的框架,通过快速测试时训练(TTT)在新颖地形上进行微调,以增强机器人的运动能力。该方法结合了预训练和快速微调,确保机器人能够适应复杂的几何形状。
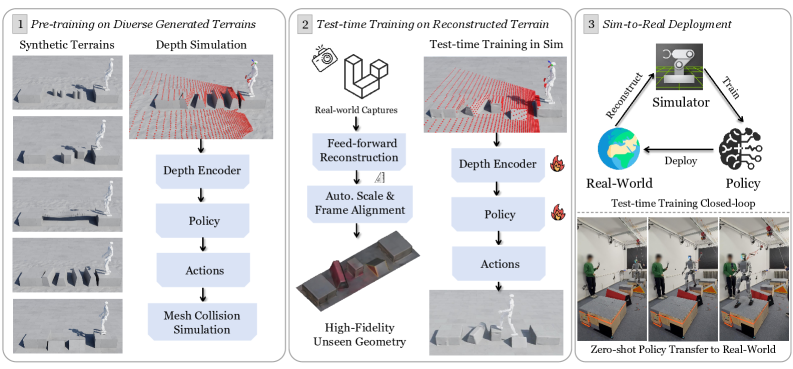
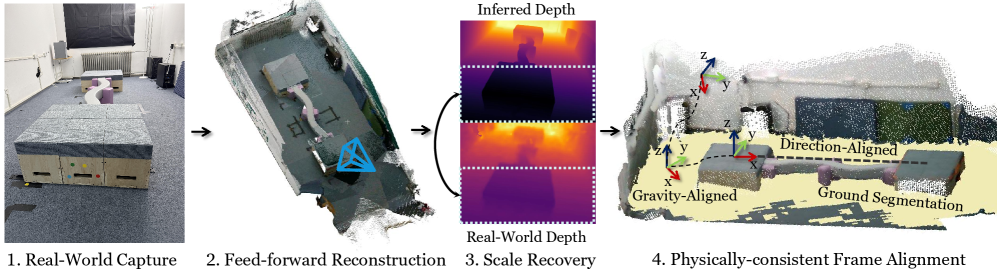
技术框架:整体架构分为两个主要阶段:首先在多样化的程序生成地形上进行预训练,然后在从真实世界捕获的高保真网格上进行快速微调。整个流程包括捕获、重建和训练三个模块。
关键创新:最重要的技术创新在于快速测试时训练的实现,使得机器人能够在短时间内适应新的复杂地形。这一方法与传统的训练方法相比,显著提高了适应性和效率。
关键设计:采用了基于RGB-D输入的高效几何重建管道,确保在测试时训练过程中的速度和质量。此外,设计了特定的损失函数和网络结构,以优化训练效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,经过测试时训练的策略在零-shot的模拟到真实转移能力上表现出色,能够有效应对复杂障碍物。整个捕获、重建和训练的流程在大多数测试地形上耗时不足10分钟,显示出极高的效率。
🎯 应用场景
该研究的潜在应用领域包括机器人运动控制、自动化物流、救援机器人等。通过提升机器人在复杂环境中的适应能力,能够在实际场景中实现更高效的任务执行,具有重要的实际价值和未来影响。
📄 摘要(原文)
Achieving highly dynamic humanoid parkour on unseen, complex terrains remains a challenge in robotics. Although general locomotion policies demonstrate capabilities across broad terrain distributions, they often struggle with arbitrary and highly challenging environments. To overcome this limitation, we propose a real-to-sim-to-real framework that leverages rapid test-time training (TTT) on novel terrains, significantly enhancing the robot's capability to traverse extremely difficult geometries. We adopt a two-stage end-to-end learning paradigm: a policy is first pre-trained on diverse procedurally generated terrains, followed by rapid fine-tuning on high-fidelity meshes reconstructed from real-world captures. Specifically, we develop a feed-forward, efficient, and high-fidelity geometry reconstruction pipeline using RGB-D inputs, ensuring both speed and quality during test-time training. We demonstrate that TTT-Parkour empowers humanoid robots to master complex obstacles, including wedges, stakes, boxes, trapezoids, and narrow beams. The whole pipeline of capturing, reconstructing, and test-time training requires less than 10 minutes on most tested terrains. Extensive experiments show that the policy after test-time training exhibits robust zero-shot sim-to-real transfer capability.