From Knowing to Doing Precisely: A General Self-Correction and Termination Framework for VLA models
作者: Wentao Zhang, Aolan Sun, Wentao Mo, Xiaoyang Qu, Yuxin Zheng, Jianzong Wang
分类: cs.RO
发布日期: 2026-02-02
备注: Accepted to 2026 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2026)
💡 一句话要点
VLA-SCT:面向VLA模型的自校正与终止通用框架,提升操作精度与任务完成度
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 具身智能体 自校正 动作优化 任务终止 精细操作 机器人操作
📋 核心要点
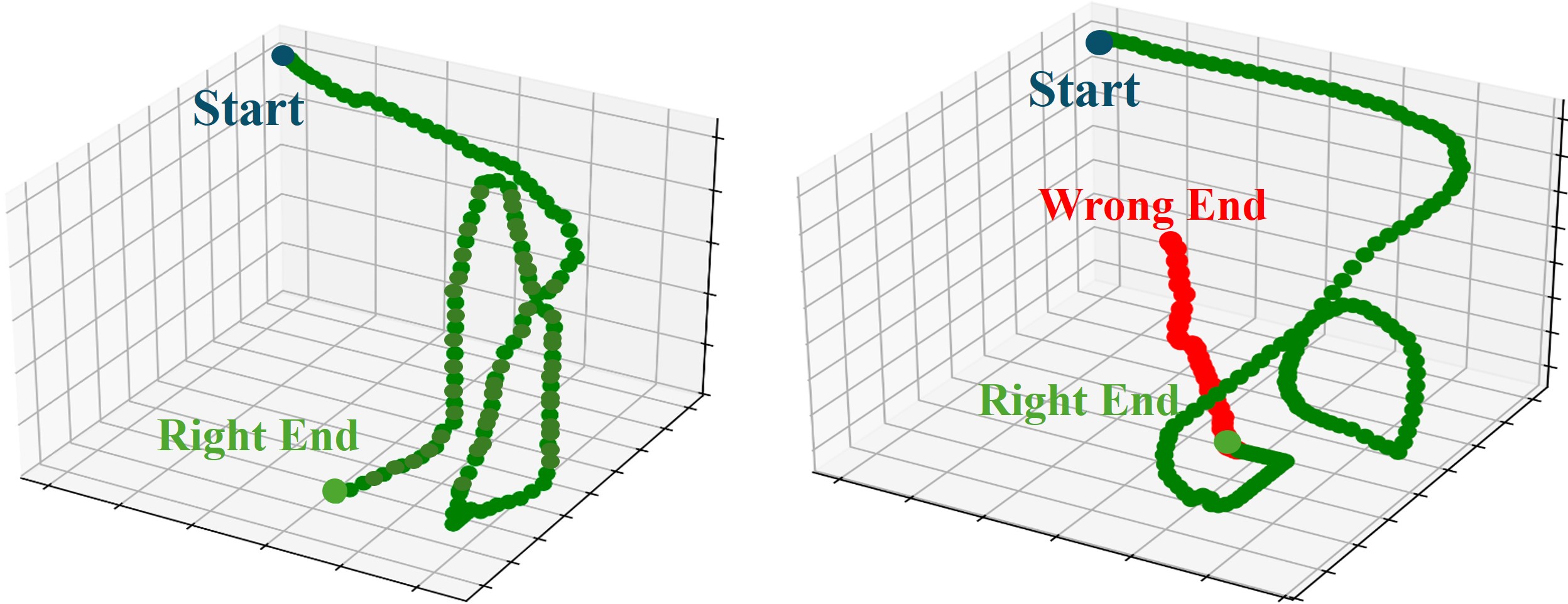
- VLA模型在抓取等任务中,动作生成存在空间偏差,导致操作失败,且缺乏任务完成的判断能力,易产生冗余动作。
- VLA-SCT框架通过自校正控制循环,结合数据驱动的动作优化和条件逻辑终止机制,提升动作精度和任务完成判断。
- 实验表明,VLA-SCT在LIBERO基准测试中显著提高了精细操作任务的成功率,并确保了任务的准确完成。
📝 摘要(中文)
本文提出了一种轻量级的、无需训练的框架VLA-SCT,旨在解决视觉-语言-动作(VLA)模型在具身智能体应用中的两个关键问题:一是抓取任务中,语言模型生成的动作token与目标物体存在细微的空间偏差,导致抓取失败;二是缺乏可靠的任务完成识别能力,导致冗余动作和频繁的超时错误。VLA-SCT作为一个自校正控制循环运行,结合了数据驱动的动作优化和用于终止的条件逻辑。实验结果表明,与基线方法相比,该方法在LIBERO基准测试的所有数据集上都取得了持续的改进,显著提高了精细操作任务的成功率,并确保了准确的任务完成,从而促进了更可靠的VLA智能体在复杂、非结构化环境中的部署。
🔬 方法详解
问题定义:VLA模型在具身智能体任务中,尤其是在抓取等精细操作任务中,存在两个主要问题。一是动作生成不够精确,生成的动作token与目标物体存在细微的空间偏差,导致抓取失败。二是缺乏可靠的任务完成识别能力,无法准确判断任务是否完成,导致智能体执行冗余动作,甚至因超时而失败。现有方法通常依赖于大量的训练数据或复杂的模型设计,但泛化能力和效率仍有待提高。
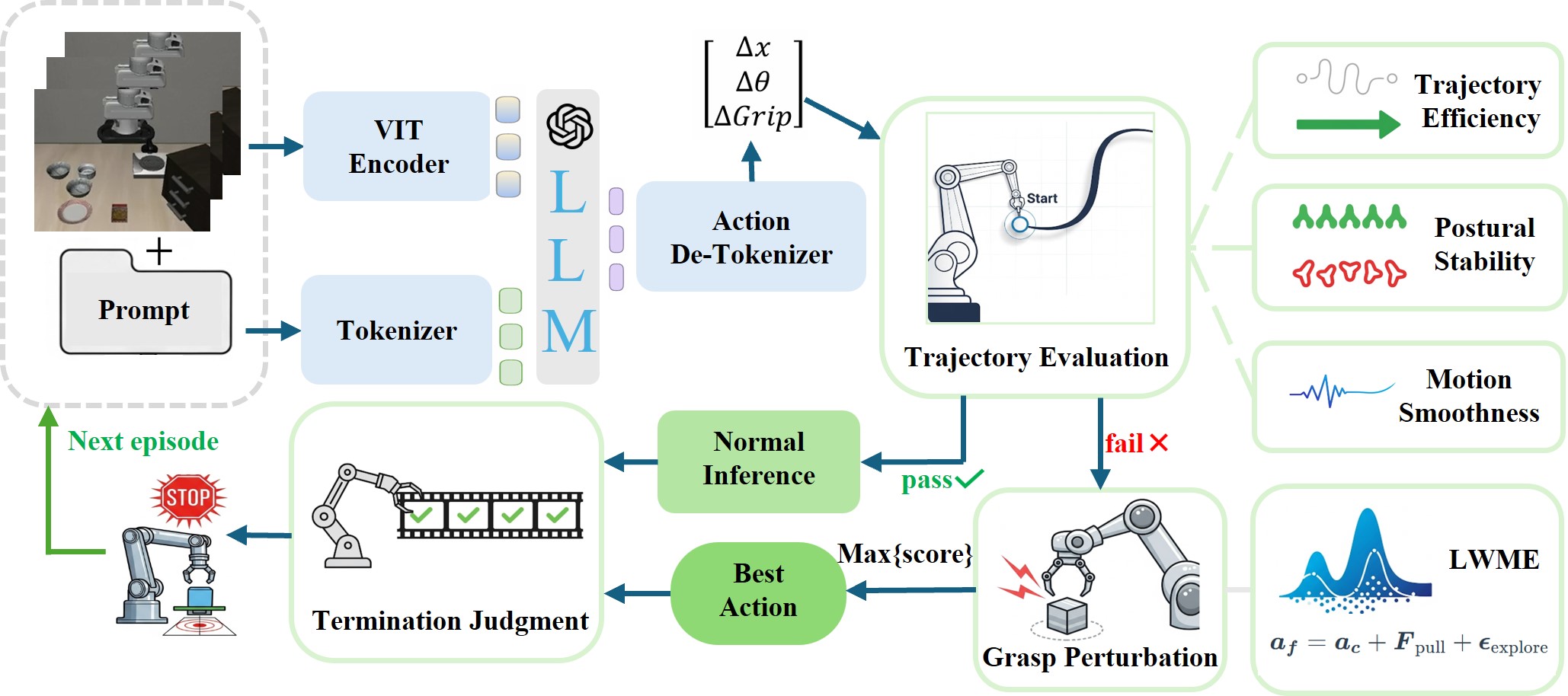
核心思路:VLA-SCT的核心思路是通过一个自校正控制循环,不断优化动作并判断任务是否完成。该框架结合了数据驱动的动作优化和条件逻辑终止机制。动作优化旨在减小动作token与目标物体之间的空间偏差,提高操作精度。条件逻辑终止机制则用于判断任务是否已经完成,避免冗余动作和超时错误。
技术框架:VLA-SCT框架主要包含两个阶段:动作优化阶段和任务终止判断阶段。在动作优化阶段,框架利用数据驱动的方法,例如通过分析历史成功案例,对当前动作进行微调,以减小空间偏差。在任务终止判断阶段,框架基于预定义的条件逻辑,例如目标物体是否被成功抓取,或者是否达到预期的状态,来判断任务是否已经完成。如果任务未完成,则返回动作优化阶段,继续优化动作。
关键创新:VLA-SCT的关键创新在于其轻量级和无需训练的设计。与需要大量训练数据的传统方法不同,VLA-SCT利用数据驱动的动作优化和条件逻辑终止机制,无需额外的训练数据。这使得VLA-SCT能够快速部署到新的环境中,并具有较强的泛化能力。此外,VLA-SCT的自校正控制循环能够不断优化动作,提高操作精度和任务完成度。
关键设计:VLA-SCT的关键设计包括:1) 数据驱动的动作优化策略,例如使用强化学习或模仿学习来学习动作优化策略;2) 条件逻辑终止机制,例如使用规则引擎或决策树来判断任务是否完成;3) 自校正控制循环的实现,例如使用PID控制器或模型预测控制来控制动作优化和任务终止判断的迭代过程。具体的参数设置和网络结构取决于具体的应用场景和任务需求。
🖼️ 关键图片

📊 实验亮点
VLA-SCT框架在LIBERO基准测试中取得了显著的性能提升。实验结果表明,与基线方法相比,VLA-SCT在所有数据集上都取得了持续的改进,显著提高了精细操作任务的成功率,并确保了准确的任务完成。具体的性能数据和提升幅度取决于具体的数据集和任务,但总体趋势是VLA-SCT能够显著提高VLA模型的性能。
🎯 应用场景
VLA-SCT框架具有广泛的应用前景,可应用于机器人操作、自动化装配、智能家居等领域。例如,在机器人操作中,VLA-SCT可以提高机器人抓取和操作物体的精度和效率,使其能够更好地完成各种任务。在智能家居中,VLA-SCT可以使智能家居设备更加智能化,能够更好地理解用户的指令并完成相应的操作。该研究的实际价值在于提高了VLA模型的可靠性和泛化能力,为VLA模型在实际场景中的应用奠定了基础。
📄 摘要(原文)
While vision-language-action (VLA) models for embodied agents integrate perception, reasoning, and control, they remain constrained by two critical weaknesses: first, during grasping tasks, the action tokens generated by the language model often exhibit subtle spatial deviations from the target object, resulting in grasp failures; second, they lack the ability to reliably recognize task completion, which leads to redundant actions and frequent timeout errors. To address these challenges and enhance robustness, we propose a lightweight, training-free framework, VLA-SCT. This framework operates as a self-correcting control loop, combining data-driven action refinement with conditional logic for termination. Consequently, compared to baseline approaches, our method achieves consistent improvements across all datasets in the LIBERO benchmark, significantly increasing the success rate of fine manipulation tasks and ensuring accurate task completion, thereby promoting the deployment of more reliable VLA agents in complex, unstructured environments.