Uncertainty-Aware Non-Prehensile Manipulation with Mobile Manipulators under Object-Induced Occlusion
作者: Jiwoo Hwang, Taegeun Yang, Jeil Jeong, Minsung Yoon, Sung-Eui Yoon
分类: cs.RO
发布日期: 2026-02-02
备注: 8 pages, 7 figures, Accepted to ICRA 2026, Webpage: https://jiw0o.github.io/cura-ppo/
💡 一句话要点
提出CURA-PPO,解决移动机械臂非抓取操作中物体遮挡带来的不确定性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 非抓取操作 移动机械臂 强化学习 不确定性建模 物体遮挡
📋 核心要点
- 现有非抓取操作方法在物体遮挡传感器视野时,易发生碰撞,缺乏对不确定性的有效建模。
- CURA-PPO通过预测碰撞概率分布,显式建模不确定性,并鼓励主动感知以解决遮挡问题。
- 实验表明,CURA-PPO在不同场景下成功率提升高达3倍,有效应对了物体遮挡问题。
📝 摘要(中文)
本文提出了一种名为CURA-PPO的强化学习框架,旨在解决使用板载传感器的非抓取操作中,被操作物体遮挡传感器视野导致碰撞的问题。该框架通过将碰撞可能性预测为分布,显式地建模了部分可观测性下的不确定性。从该分布中提取风险和不确定性,以指导机器人的动作。不确定性项鼓励主动感知,从而实现同步操作和信息收集,以解决遮挡问题。结合捕捉观测可靠性的置信度图,该方法能够在严重的传感器遮挡下实现安全导航。在不同物体尺寸和障碍物配置下的广泛实验表明,CURA-PPO的成功率比基线方法高出3倍,并且学习到的行为能够处理遮挡。该方法为仅使用板载传感器的杂乱环境中的自主操作提供了一种实用的解决方案。
🔬 方法详解
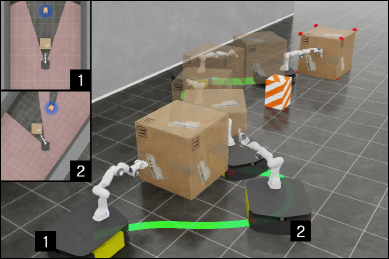
问题定义:论文旨在解决移动机械臂在进行非抓取操作时,由于被操作物体遮挡了板载传感器的视野,导致机器人无法准确感知环境,从而容易发生碰撞的问题。现有的方法通常忽略了这种由遮挡引起的不确定性,或者无法有效地利用有限的观测信息进行规划和控制,导致操作的鲁棒性和安全性不足。
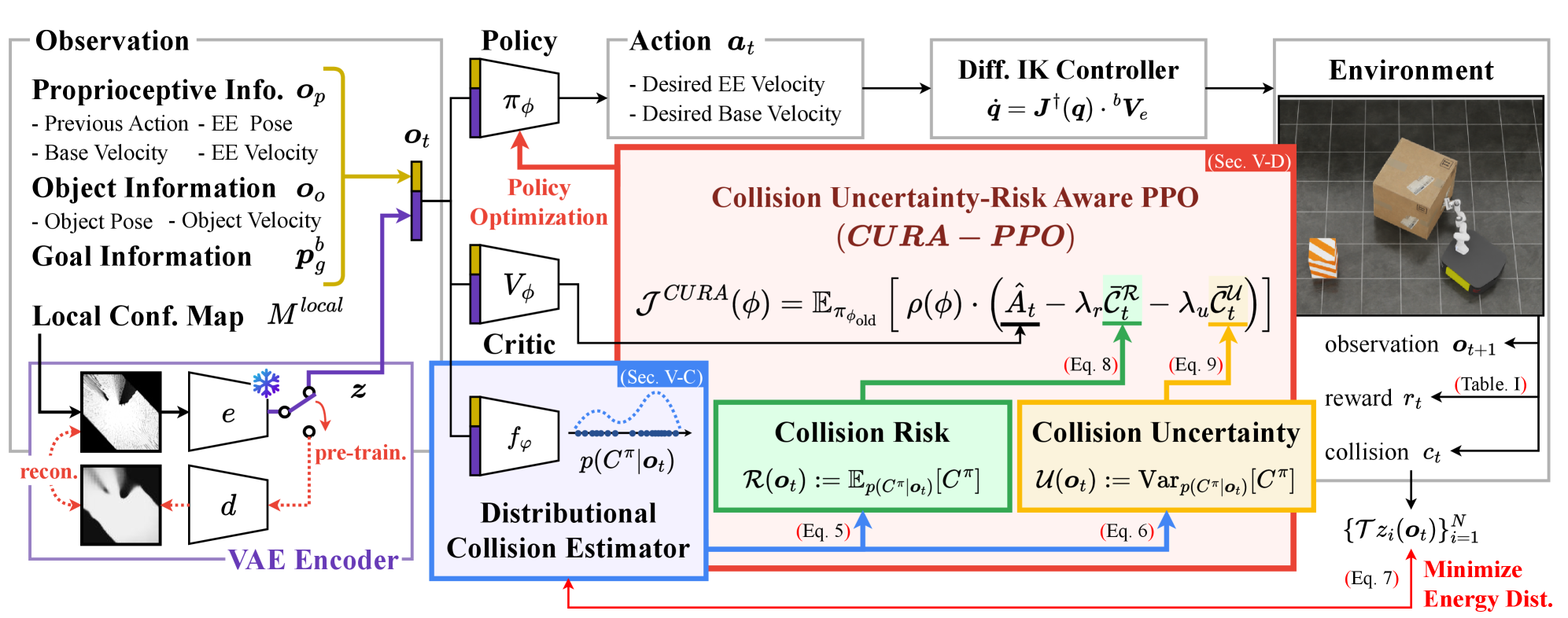
核心思路:论文的核心思路是通过强化学习显式地建模这种不确定性,并利用不确定性信息来指导机器人的动作。具体来说,就是将碰撞的可能性预测为一个概率分布,并从这个分布中提取风险(碰撞的概率)和不确定性(概率分布的方差)。风险用于避免碰撞,而不确定性则用于鼓励机器人进行主动感知,即通过调整自身的姿态来获取更多的信息,从而降低不确定性。
技术框架:CURA-PPO的整体框架是一个基于Actor-Critic的强化学习算法。主要包含以下几个模块:1) 状态表示:使用板载传感器获取的局部环境信息,包括深度图像和置信度图。置信度图用于表示观测的可靠性,例如,被遮挡区域的置信度较低。2) Actor网络:根据当前的状态,输出机器人的动作,例如,移动机械臂的关节角度。3) Critic网络:评估当前状态的价值,即在当前状态下执行某个动作后,能够获得的期望回报。4) 碰撞预测模块:预测碰撞的概率分布,并从中提取风险和不确定性。5) 奖励函数:设计一个奖励函数,鼓励机器人完成操作任务,同时避免碰撞,并降低不确定性。
关键创新:论文的关键创新在于显式地建模了由物体遮挡引起的不确定性,并将这种不确定性信息融入到强化学习的框架中。通过预测碰撞概率分布,可以同时获取风险和不确定性,从而指导机器人进行安全和高效的操作。此外,论文还提出了使用置信度图来表示观测的可靠性,进一步提高了算法的鲁棒性。
关键设计:论文的关键设计包括:1) 碰撞预测模块:使用一个卷积神经网络来预测碰撞的概率分布。该网络的输入是深度图像和置信度图,输出是一个离散的概率分布,表示碰撞的可能性。2) 奖励函数:奖励函数包含三个部分:操作奖励、碰撞惩罚和不确定性惩罚。操作奖励鼓励机器人完成操作任务,碰撞惩罚避免碰撞,不确定性惩罚鼓励机器人降低不确定性。3) Actor-Critic网络结构:使用了PPO算法进行训练,并对Actor和Critic网络进行了精细的设计,以提高学习效率和稳定性。
🖼️ 关键图片
📊 实验亮点
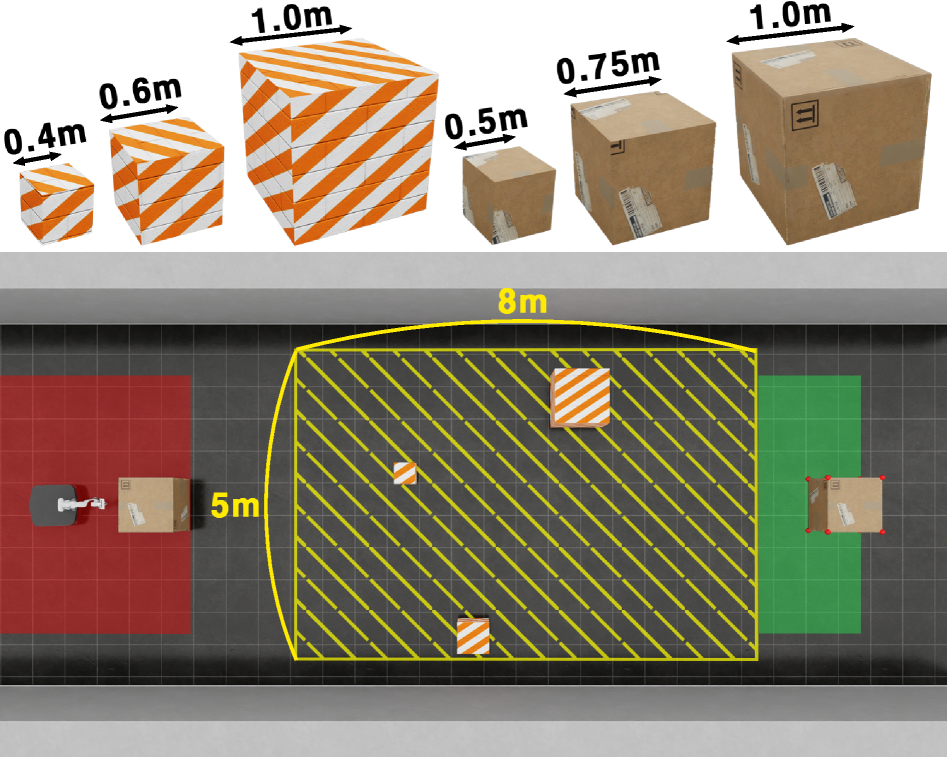
实验结果表明,CURA-PPO在不同物体尺寸和障碍物配置下,成功率比基线方法高出3倍。这表明CURA-PPO能够有效地处理物体遮挡带来的不确定性,并学习到安全和高效的操作策略。此外,实验还验证了置信度图的有效性,它可以提高算法在观测不确定情况下的鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要自主操作的场景,例如:仓库物流、家庭服务机器人、灾难救援等。在这些场景中,机器人需要在复杂的环境中进行操作,并且经常会遇到物体遮挡等问题。CURA-PPO能够提高机器人在这些场景中的操作效率和安全性,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Non-prehensile manipulation using onboard sensing presents a fundamental challenge: the manipulated object occludes the sensor's field of view, creating occluded regions that can lead to collisions. We propose CURA-PPO, a reinforcement learning framework that addresses this challenge by explicitly modeling uncertainty under partial observability. By predicting collision possibility as a distribution, we extract both risk and uncertainty to guide the robot's actions. The uncertainty term encourages active perception, enabling simultaneous manipulation and information gathering to resolve occlusions. When combined with confidence maps that capture observation reliability, our approach enables safe navigation despite severe sensor occlusion. Extensive experiments across varying object sizes and obstacle configurations demonstrate that CURA-PPO achieves up to 3X higher success rates than the baselines, with learned behaviors that handle occlusions. Our method provides a practical solution for autonomous manipulation in cluttered environments using only onboard sensing.