UniDWM: Towards a Unified Driving World Model via Multifaceted Representation Learning
作者: Shuai Liu, Siheng Ren, Xiaoyao Zhu, Quanmin Liang, Zefeng Li, Qiang Li, Xin Hu, Kai Huang
分类: cs.RO, cs.CV
发布日期: 2026-02-02
🔗 代码/项目: GITHUB
💡 一句话要点
UniDWM:通过多方面表征学习构建统一的驾驶世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶 世界模型 多方面表征学习 条件扩散模型 轨迹规划
📋 核心要点
- 现有自动驾驶模型难以有效处理复杂驾驶环境中的几何、外观和动态信息,导致规划的可靠性和效率降低。
- UniDWM通过学习场景的结构和动态信息,构建一个统一的、物理基础的潜在世界表征,实现跨感知、预测和规划的一致性推理。
- 实验结果表明,UniDWM在轨迹规划、4D重建和生成任务中表现出色,验证了多方面世界表征在自动驾驶领域的潜力。
📝 摘要(中文)
本文提出UniDWM,一个统一的驾驶世界模型,通过多方面表征学习来推进自动驾驶技术。UniDWM构建了一个结构和动态感知的潜在世界表征,作为物理基础的状态空间,从而实现跨感知、预测和规划的一致推理。具体而言,联合重建通路学习恢复场景的结构,包括几何和视觉纹理,而协作生成框架利用条件扩散Transformer来预测潜在空间中未来的世界演变。此外,本文证明UniDWM可以被视为VAE的一种变体,为多方面表征学习提供理论指导。大量实验表明UniDWM在轨迹规划、4D重建和生成方面的有效性,突出了多方面世界表征作为统一驾驶智能基础的潜力。
🔬 方法详解
问题定义:自动驾驶需要在复杂环境中进行可靠和高效的规划,这要求模型能够理解和推理场景的几何结构、视觉外观以及动态变化。现有的方法通常难以将这些信息有效地整合到一个统一的框架中,导致感知、预测和规划之间存在gap,影响了自动驾驶系统的性能。
核心思路:UniDWM的核心思路是通过多方面表征学习,将场景的几何结构、视觉外观和动态信息编码到一个统一的潜在空间中。这个潜在空间既能反映场景的物理结构,又能预测未来的演变,从而为自动驾驶系统提供一个一致的、可推理的状态空间。这样设计可以使得感知、预测和规划模块能够共享同一个世界模型,减少信息传递过程中的损失。
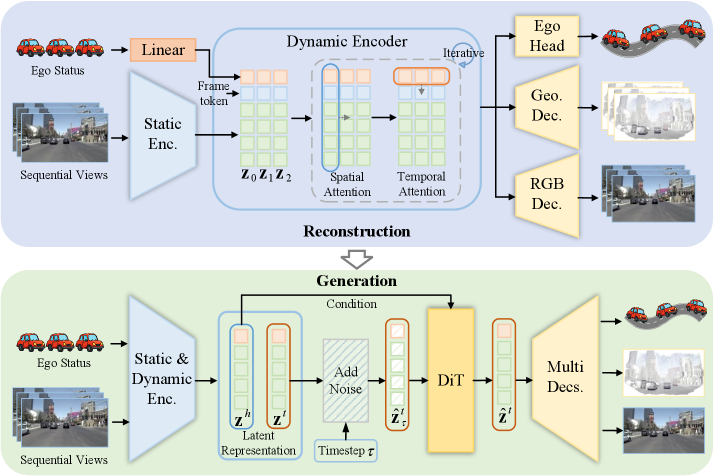
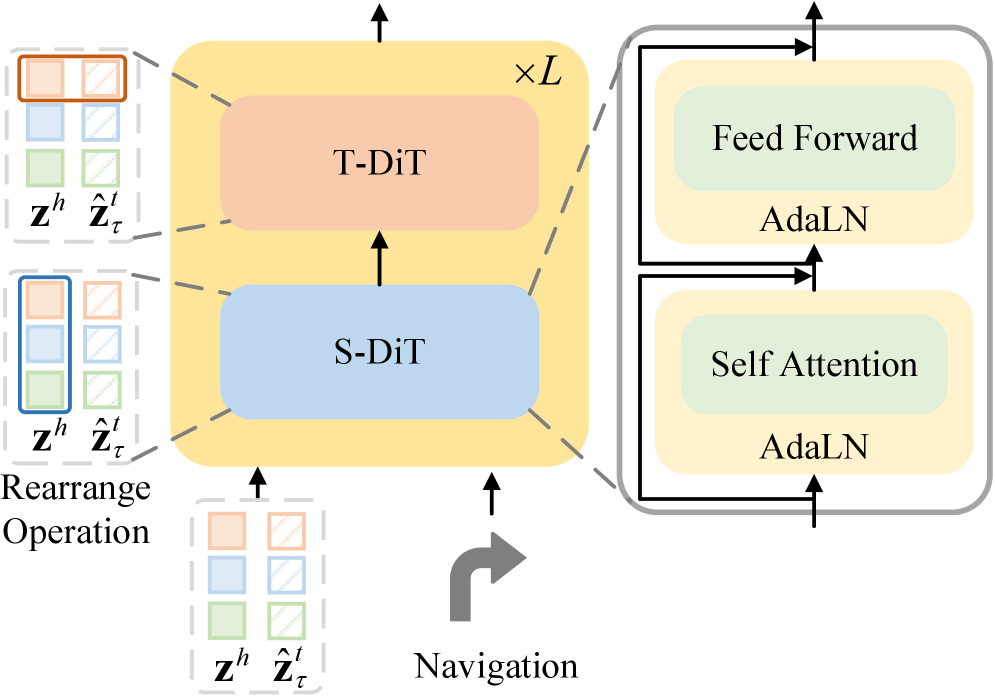
技术框架:UniDWM的整体架构包含两个主要通路:联合重建通路和协作生成框架。联合重建通路负责从输入图像中恢复场景的结构信息,包括几何形状和视觉纹理。这个通路通常使用编码器-解码器结构,编码器将图像映射到潜在空间,解码器从潜在空间重建图像。协作生成框架则利用条件扩散Transformer来预测潜在空间中未来的世界演变。这个框架以当前的状态作为条件,生成未来的状态,从而实现对场景动态的建模。
关键创新:UniDWM的关键创新在于它将场景的结构和动态信息整合到一个统一的潜在空间中,并使用条件扩散Transformer来预测未来的世界演变。这种方法不仅能够有效地建模场景的复杂性,还能够实现跨感知、预测和规划的一致性推理。此外,论文还从理论上证明了UniDWM可以被视为VAE的一种变体,为多方面表征学习提供了理论指导。
关键设计:在联合重建通路中,可以使用各种编码器-解码器结构,例如卷积神经网络或Transformer。损失函数通常包括重建损失和正则化项,以保证潜在空间的平滑性和可解释性。在协作生成框架中,条件扩散Transformer的设计需要仔细考虑如何有效地利用条件信息,例如可以使用注意力机制将条件信息融入到Transformer的每一层。此外,扩散模型的训练也需要仔细调整参数,以保证生成样本的质量。
🖼️ 关键图片

📊 实验亮点
UniDWM在轨迹规划、4D重建和生成任务中表现出色。具体性能数据和对比基线在论文中给出,表明UniDWM能够有效地建模场景的结构和动态信息,并实现跨感知、预测和规划的一致性推理。实验结果验证了多方面世界表征作为统一驾驶智能基础的潜力。
🎯 应用场景
UniDWM在自动驾驶领域具有广泛的应用前景,可用于提高自动驾驶系统的感知、预测和规划能力。例如,它可以用于生成更准确的场景表示,预测车辆和行人的未来轨迹,以及规划更安全和高效的行驶路线。此外,UniDWM还可以应用于自动驾驶仿真和测试,帮助开发人员评估和改进自动驾驶算法。
📄 摘要(原文)
Achieving reliable and efficient planning in complex driving environments requires a model that can reason over the scene's geometry, appearance, and dynamics. We present UniDWM, a unified driving world model that advances autonomous driving through multifaceted representation learning. UniDWM constructs a structure- and dynamic-aware latent world representation that serves as a physically grounded state space, enabling consistent reasoning across perception, prediction, and planning. Specifically, a joint reconstruction pathway learns to recover the scene's structure, including geometry and visual texture, while a collaborative generation framework leverages a conditional diffusion transformer to forecast future world evolution within the latent space. Furthermore, we show that our UniDWM can be deemed as a variation of VAE, which provides theoretical guidance for the multifaceted representation learning. Extensive experiments demonstrate the effectiveness of UniDWM in trajectory planning, 4D reconstruction and generation, highlighting the potential of multifaceted world representations as a foundation for unified driving intelligence. The code will be publicly available at https://github.com/Say2L/UniDWM.