RAPT: Model-Predictive Out-of-Distribution Detection and Failure Diagnosis for Sim-to-Real Humanoid Robots
作者: Humphrey Munn, Brendan Tidd, Peter Bohm, Marcus Gallagher, David Howard
分类: cs.RO, cs.LG
发布日期: 2026-02-02
💡 一句话要点
RAPT:基于模型预测的分布外检测与故障诊断,用于Sim-to-Real人形机器人
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 人形机器人 Sim-to-Real 分布外检测 故障诊断 模型预测 可解释性 自监督学习
📋 核心要点
- 现有方法难以在人形机器人Sim-to-Real部署中进行可靠的异常检测,尤其是在高控制频率和低误报率要求下。
- RAPT通过学习标称执行的概率时空流形,预测执行偏差,并结合LLM进行故障诊断,实现可靠的OOD检测和可解释性。
- 实验表明,RAPT在仿真和真实机器人上均优于现有方法,显著提高了真阳性率,并实现了较高的根本原因分类准确率。
📝 摘要(中文)
在人形机器人上部署学习到的控制策略充满挑战:在仿真中看似鲁棒的策略,经过Sim-to-Real迁移后,可能在分布外(OOD)状态下自信地执行,导致硬件损坏的潜在故障。虽然异常检测可以缓解这些故障,但现有方法通常与高频率控制不兼容,在实际部署所需的极低误报率下校准不佳,或者作为黑盒运行,提供二元停止信号而无法解释机器人偏离标称行为的原因。我们提出了RAPT,一个轻量级的、自监督的部署时监控器,用于50Hz的人形机器人控制。RAPT从仿真中学习标称执行的概率时空流形,并将执行时的预测偏差评估为校准的、按维度的信号。这产生了(i)在严格的误报约束下可靠的在线OOD检测,以及(ii)一种连续的、可解释的Sim-to-Real不匹配度量,可以随时间跟踪,以量化部署偏离训练的程度。除了检测之外,我们还引入了一种自动的后验根本原因分析流程,该流程将源自RAPT重建目标的基于梯度的时序显著性与基于LLM的推理相结合,并以显著性和关节运动学为条件,以零样本方式生成语义故障诊断。我们在Unitree G1人形机器人上,通过仿真和物理硬件上的四个复杂任务评估了RAPT。在大规模仿真中,RAPT在0.5%的固定episode级别误报率下,比最强的基线提高了37%的真阳性率(TPR)。在真实世界的部署中,RAPT实现了12.5%的TPR改进,并提供了可操作的可解释性,仅使用本体感受数据,在16个真实世界的故障中达到了75%的根本原因分类准确率。
🔬 方法详解
问题定义:论文旨在解决人形机器人在Sim-to-Real部署中,由于控制策略在分布外(OOD)状态下的自信执行而导致的潜在硬件损坏问题。现有异常检测方法在高频率控制、低误报率要求以及提供可解释性方面存在不足,无法有效应对真实场景的挑战。
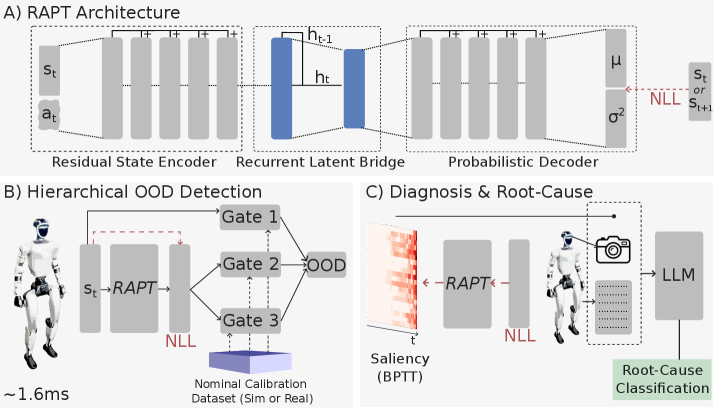
核心思路:RAPT的核心思路是学习一个标称执行的概率时空流形,通过预测执行偏差来检测OOD状态。这种方法能够提供校准的、按维度的信号,从而实现可靠的在线OOD检测。此外,RAPT还结合LLM进行故障诊断,提供可解释的根本原因分析。
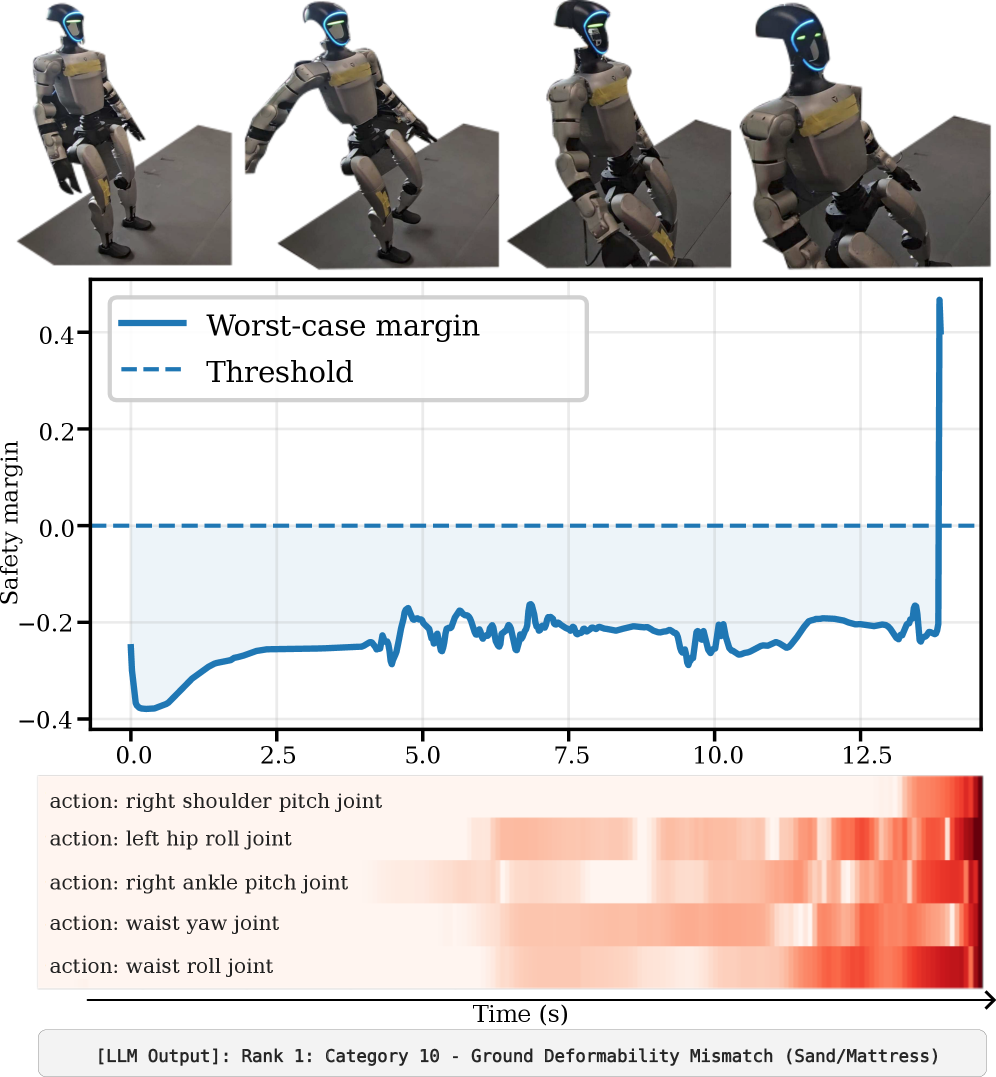
技术框架:RAPT的整体框架包含以下几个主要模块:1) 数据收集:从仿真环境中收集标称执行数据。2) 模型训练:使用收集到的数据训练一个概率时空模型,学习标称执行的流形。3) 在线OOD检测:在部署时,使用训练好的模型预测执行偏差,并将其作为OOD信号。4) 故障诊断:如果检测到OOD状态,则使用基于梯度的时序显著性分析和LLM进行根本原因分析。
关键创新:RAPT的关键创新在于:1) 概率时空建模:通过学习标称执行的概率时空流形,能够更准确地检测OOD状态。2) 可解释性:结合LLM进行故障诊断,提供可解释的根本原因分析,而不仅仅是二元停止信号。3) 轻量级设计:适用于高频率控制,能够在资源有限的机器人平台上运行。
关键设计:RAPT使用自监督学习方法训练概率时空模型。模型的具体结构未知,但可以推测使用了循环神经网络或Transformer等时序模型。损失函数可能包括重建损失和正则化项,以保证模型的泛化能力。梯度显著性分析用于确定对预测偏差贡献最大的时间步和关节。LLM的使用方式未知,但推测是根据显著性和关节运动学信息生成自然语言的故障诊断报告。
🖼️ 关键图片
📊 实验亮点
RAPT在Unitree G1人形机器人上的实验结果表明,其性能优于现有方法。在大规模仿真中,RAPT在0.5%的固定episode级别误报率下,比最强的基线提高了37%的真阳性率(TPR)。在真实世界的部署中,RAPT实现了12.5%的TPR改进,并提供了可操作的可解释性,仅使用本体感受数据,在16个真实世界的故障中达到了75%的根本原因分类准确率。
🎯 应用场景
RAPT可应用于各种人形机器人的Sim-to-Real部署场景,例如工业巡检、灾难救援、家庭服务等。通过提供可靠的OOD检测和可解释的故障诊断,RAPT能够有效降低机器人硬件损坏的风险,提高机器人的安全性和可靠性,加速人形机器人在实际场景中的应用。
📄 摘要(原文)
Deploying learned control policies on humanoid robots is challenging: policies that appear robust in simulation can execute confidently in out-of-distribution (OOD) states after Sim-to-Real transfer, leading to silent failures that risk hardware damage. Although anomaly detection can mitigate these failures, prior methods are often incompatible with high-rate control, poorly calibrated at the extremely low false-positive rates required for practical deployment, or operate as black boxes that provide a binary stop signal without explaining why the robot drifted from nominal behavior. We present RAPT, a lightweight, self-supervised deployment-time monitor for 50Hz humanoid control. RAPT learns a probabilistic spatio-temporal manifold of nominal execution from simulation and evaluates execution-time predictive deviation as a calibrated, per-dimension signal. This yields (i) reliable online OOD detection under strict false-positive constraints and (ii) a continuous, interpretable measure of Sim-to-Real mismatch that can be tracked over time to quantify how far deployment has drifted from training. Beyond detection, we introduce an automated post-hoc root-cause analysis pipeline that combines gradient-based temporal saliency derived from RAPT's reconstruction objective with LLM-based reasoning conditioned on saliency and joint kinematics to produce semantic failure diagnoses in a zero-shot setting. We evaluate RAPT on a Unitree G1 humanoid across four complex tasks in simulation and on physical hardware. In large-scale simulation, RAPT improves True Positive Rate (TPR) by 37% over the strongest baseline at a fixed episode-level false positive rate of 0.5%. On real-world deployments, RAPT achieves a 12.5% TPR improvement and provides actionable interpretability, reaching 75% root-cause classification accuracy across 16 real-world failures using only proprioceptive data.