End-to-end Optimization of Belief and Policy Learning in Shared Autonomy Paradigms
作者: MH Farhadi, Ali Rabiee, Sima Ghafoori, Anna Cetera, Andrew Fisher, Reza Abiri
分类: cs.RO, cs.AI, cs.HC, cs.LG
发布日期: 2026-01-30
💡 一句话要点
BRACE:端到端优化信念与策略学习,提升共享自主系统人机协作性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 共享自主 人机交互 意图推断 强化学习 端到端优化
📋 核心要点
- 现有共享自主系统在复杂环境中表现不佳,原因在于其静态辅助策略和分离的意图推断与辅助决策。
- BRACE框架通过端到端优化贝叶斯意图推断和上下文自适应辅助,实现了意图推断与辅助仲裁的梯度信息共享。
- 实验表明,BRACE在人机交互、机器人控制和复杂操作任务中均优于现有方法,显著提升成功率和路径效率。
📝 摘要(中文)
共享自主系统需要合理的方法来推断用户意图并确定适当的辅助水平。这是人机交互中的一个核心挑战,系统必须在成功的同时关注用户的自主性。以往的方法依赖于静态混合比例或将目标推断与辅助仲裁分离,导致在非结构化环境中性能欠佳。我们引入了BRACE(Bayesian Reinforcement Assistance with Context Encoding),这是一个新颖的框架,通过一种架构,实现了意图推断和辅助仲裁之间的端到端梯度流动,从而微调贝叶斯意图推断和上下文自适应辅助。我们的流程将协作控制策略建立在环境上下文和完整的目标概率分布之上。我们提供的分析表明:(1)最佳辅助水平应随着目标不确定性的降低而降低,并随着环境约束的严重性增加而增加;(2)将信念信息集成到策略学习中,与顺序方法相比,预期遗憾呈二次方优势。我们使用一个三部分评估,逐步隔离末端执行器控制的不同挑战,针对SOTA方法(IDA、DQN)验证了我们的算法:(1)2D人机环路光标任务中的核心人机交互动力学,(2)机器人手臂的非线性动力学,以及(3)目标模糊和环境约束下的集成操作。我们证明了相对于SOTA的改进,实现了6.3%的更高成功率和41%的路径效率提升,以及相对于无辅助控制的36.3%的成功率和87%的路径效率提升。我们的结果证实,集成优化在复杂、目标模糊的场景中最有益,并且可以推广到需要目标导向辅助的机器人领域,从而推进了自适应共享自主的SOTA。
🔬 方法详解
问题定义:共享自主系统旨在帮助人类完成任务,但如何准确理解人类意图并提供适当的辅助是一个关键问题。现有方法,如静态混合比例或分离的意图推断和辅助仲裁,无法有效应对复杂、目标模糊的环境,导致性能下降。这些方法无法充分利用环境信息和用户信念,难以实现最优的人机协作。
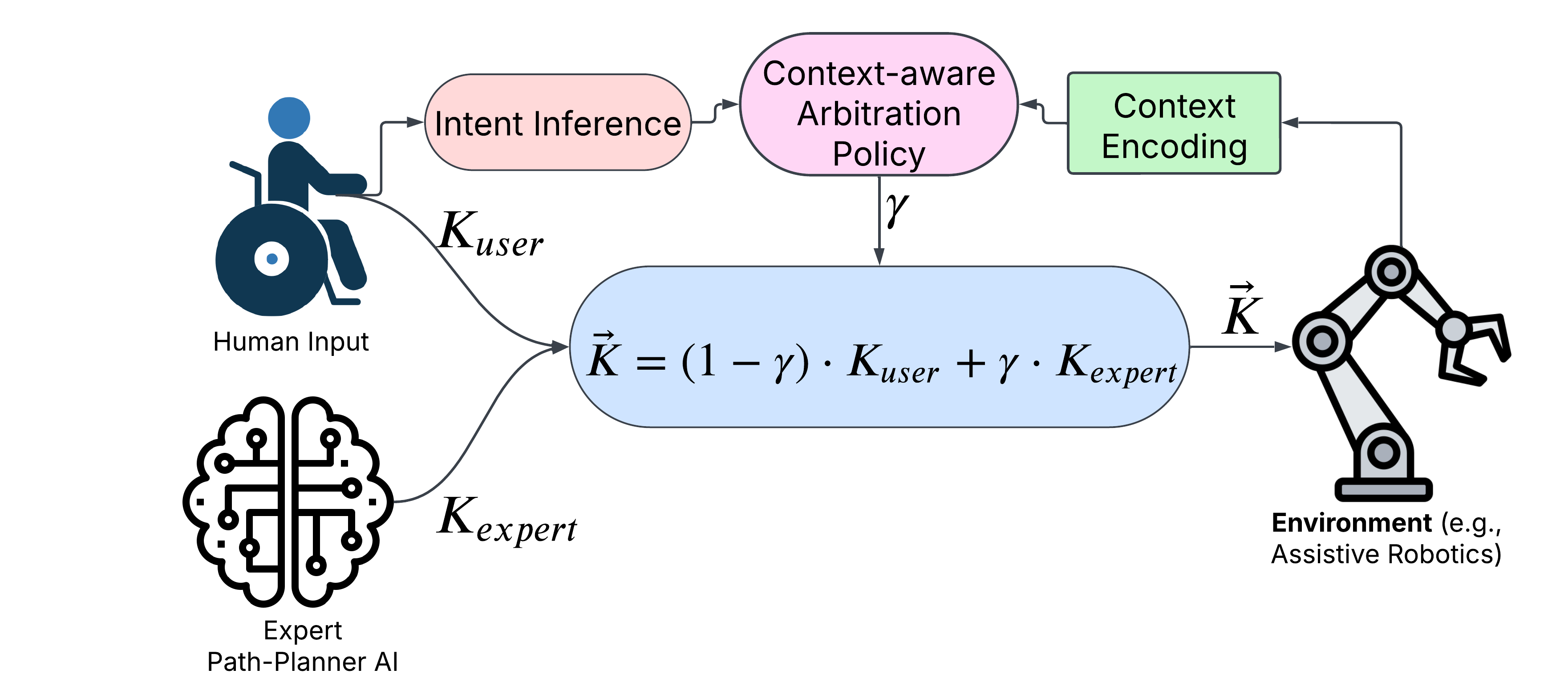
核心思路:BRACE的核心思路是通过端到端的方式,将意图推断和辅助策略学习整合到一个统一的框架中。该框架利用贝叶斯方法进行意图推断,并根据环境上下文动态调整辅助水平。通过允许意图推断模块和辅助策略模块之间进行梯度信息传递,BRACE能够实现更高效的协作控制。
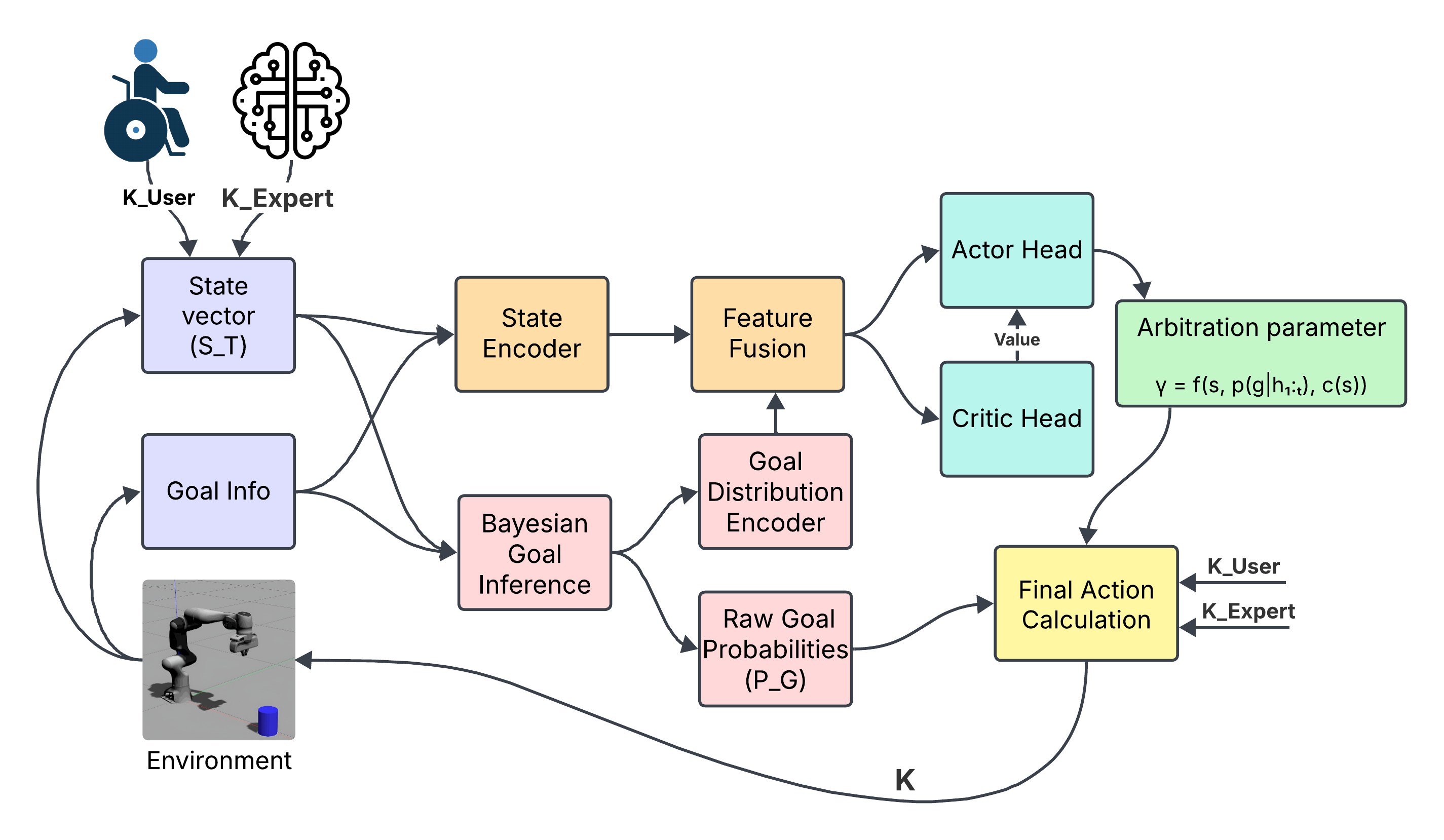
技术框架:BRACE框架包含以下主要模块:1) 环境上下文编码器:用于提取环境信息。2) 贝叶斯意图推断模块:根据用户行为和环境信息,推断用户目标概率分布。3) 上下文自适应辅助策略模块:根据环境上下文和目标概率分布,生成辅助控制策略。整个框架通过端到端的方式进行训练,允许梯度在各个模块之间流动,从而实现联合优化。
关键创新:BRACE的关键创新在于其端到端优化架构,它允许意图推断和辅助策略学习相互影响,从而实现更高效的协作控制。与以往分离的方法相比,BRACE能够更好地利用环境信息和用户信念,从而在复杂、目标模糊的环境中实现更好的性能。此外,BRACE还通过理论分析证明了将信念信息集成到策略学习中的优势。
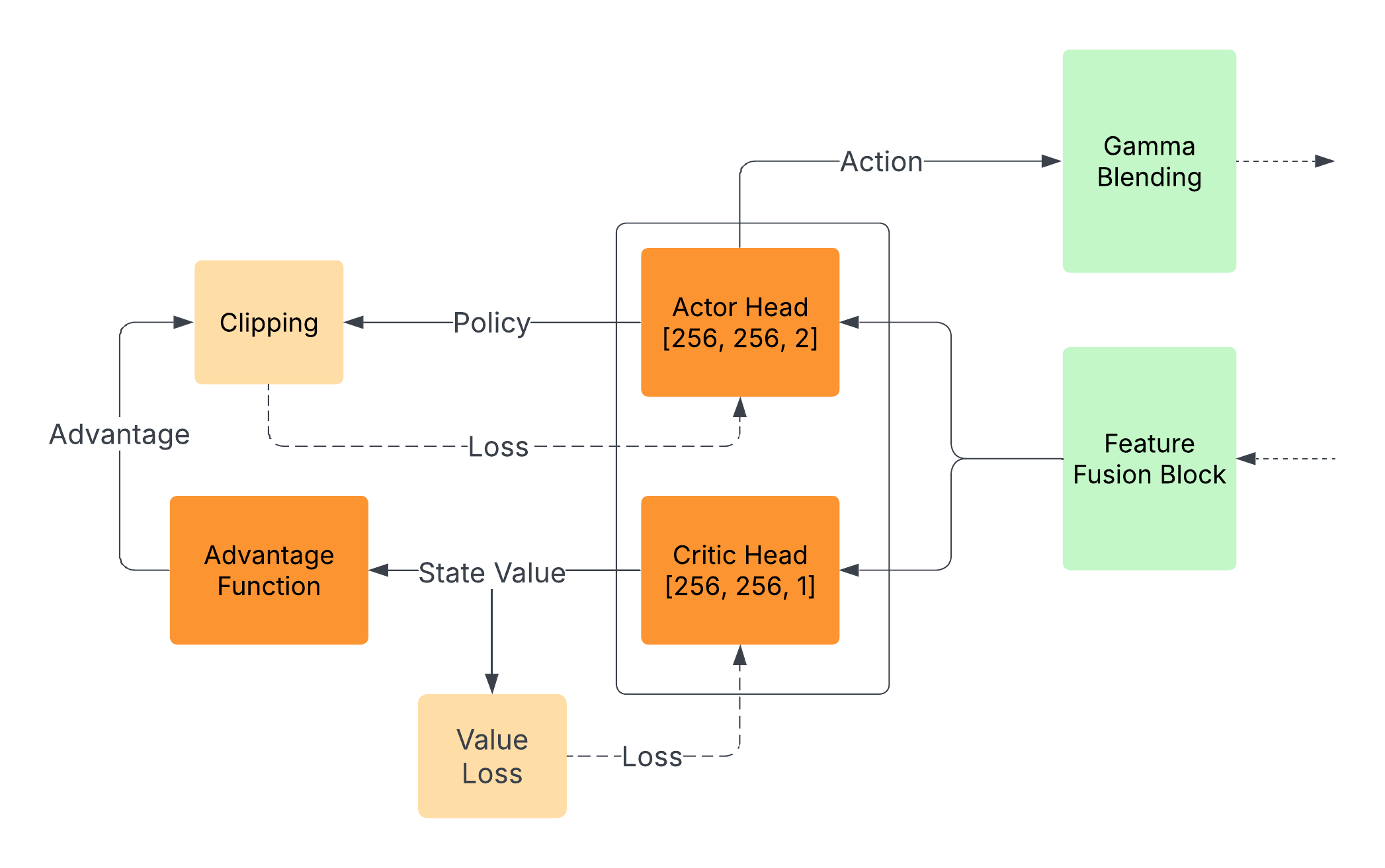
关键设计:BRACE使用贝叶斯方法进行意图推断,并采用深度神经网络来学习上下文自适应辅助策略。损失函数的设计旨在最大化任务成功率和路径效率,同时鼓励系统提供适当的辅助水平。网络结构的设计允许梯度在各个模块之间流动,从而实现端到端优化。具体参数设置和网络结构的选择需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BRACE在2D光标任务、机器人手臂控制和集成操作任务中均优于SOTA方法(IDA、DQN)。在集成操作任务中,BRACE实现了6.3%的更高成功率和41%的路径效率提升,以及相对于无辅助控制的36.3%的成功率和87%的路径效率提升。这些结果表明,BRACE能够有效提升共享自主系统的性能,尤其是在复杂、目标模糊的环境中。
🎯 应用场景
BRACE框架可应用于各种共享自主系统,例如辅助驾驶、医疗机器人、人机协作制造等。该框架能够提升人机协作效率和安全性,降低用户操作负担,并提高任务完成质量。未来,BRACE有望在更多领域得到应用,例如智能家居、虚拟现实等,实现更智能、更自然的人机交互。
📄 摘要(原文)
Shared autonomy systems require principled methods for inferring user intent and determining appropriate assistance levels. This is a central challenge in human-robot interaction, where systems must be successful while being mindful of user agency. Previous approaches relied on static blending ratios or separated goal inference from assistance arbitration, leading to suboptimal performance in unstructured environments. We introduce BRACE (Bayesian Reinforcement Assistance with Context Encoding), a novel framework that fine-tunes Bayesian intent inference and context-adaptive assistance through an architecture enabling end-to-end gradient flow between intent inference and assistance arbitration. Our pipeline conditions collaborative control policies on environmental context and complete goal probability distributions. We provide analysis showing (1) optimal assistance levels should decrease with goal uncertainty and increase with environmental constraint severity, and (2) integrating belief information into policy learning yields a quadratic expected regret advantage over sequential approaches. We validated our algorithm against SOTA methods (IDA, DQN) using a three-part evaluation progressively isolating distinct challenges of end-effector control: (1) core human-interaction dynamics in a 2D human-in-the-loop cursor task, (2) non-linear dynamics of a robotic arm, and (3) integrated manipulation under goal ambiguity and environmental constraints. We demonstrate improvements over SOTA, achieving 6.3% higher success rates and 41% increased path efficiency, and 36.3% success rate and 87% path efficiency improvement over unassisted control. Our results confirmed that integrated optimization is most beneficial in complex, goal-ambiguous scenarios, and is generalizable across robotic domains requiring goal-directed assistance, advancing the SOTA for adaptive shared autonomy.