Temporally Coherent Imitation Learning via Latent Action Flow Matching for Robotic Manipulation
作者: Wu Songwei, Jiang Zhiduo, Xie Guanghu, Liu Yang, Liu Hong
分类: cs.RO
发布日期: 2026-01-30
备注: 8 pages, 8 figures
💡 一句话要点
提出LG-Flow Policy,通过潜在动作流匹配实现机器人操作任务的时序一致模仿学习。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 模仿学习 流匹配 潜在空间 时序一致性
📋 核心要点
- 现有生成策略在长时程机器人操作中,难以兼顾行为建模能力、实时推理速度和执行稳定性。
- LG-Flow Policy在潜在动作空间进行流匹配,解耦全局运动结构和低级控制噪声,提升轨迹平滑性和可靠性。
- 实验表明,LG-Flow Policy在推理速度、轨迹平滑度和任务成功率上均优于现有方法,且效率高于扩散模型。
📝 摘要(中文)
本文提出LG-Flow Policy,一个轨迹级别的模仿学习框架,它在连续潜在动作空间中执行流匹配。通过将动作序列编码为时序正则化的潜在轨迹,并学习显式的潜在空间流,该方法将全局运动结构与低级控制噪声解耦,从而实现平滑和可靠的长时程执行。LG-Flow Policy进一步结合了几何感知的点云条件和执行时多模态调制,并在真实环境中评估了视觉线索作为代表性模态。在模拟和物理机器人平台上的实验结果表明,LG-Flow Policy实现了接近单步推理的速度,显著提高了轨迹平滑度和任务成功率,优于在原始动作空间中运行的基于流的基线,并且比基于扩散的策略更有效。
🔬 方法详解
问题定义:长时程机器人操作任务需要学习复杂的行为模式,同时保证实时推理和稳定执行。现有的生成策略,如基于扩散模型的方法,虽然建模能力强,但推理延迟高;直接在原始动作空间进行流匹配的方法,虽然推理速度快,但容易导致执行不稳定,产生抖动或失败的轨迹。
核心思路:LG-Flow Policy的核心思路是将动作序列映射到连续的潜在动作空间,并在该空间中进行流匹配。通过学习潜在空间中的流,可以更好地捕捉全局运动结构,并抑制低级控制噪声,从而实现更平滑、更稳定的轨迹。这种解耦的思想是保证长时程任务成功的关键。
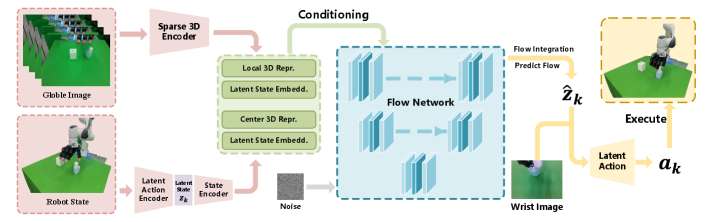
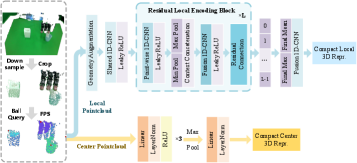
技术框架:LG-Flow Policy包含以下主要模块:1) 动作序列编码器:将原始动作序列编码为潜在空间中的轨迹;2) 潜在空间流学习器:学习潜在空间中的流函数,用于生成新的潜在轨迹;3) 动作序列解码器:将潜在轨迹解码为原始动作序列,用于机器人执行;4) 几何感知点云条件模块:利用点云信息作为环境感知输入,指导动作生成;5) 执行时多模态调制模块:融合多种模态信息,进一步优化动作序列。
关键创新:LG-Flow Policy的关键创新在于在潜在动作空间中进行流匹配。与直接在原始动作空间进行流匹配相比,这种方法可以更好地捕捉全局运动结构,并抑制低级控制噪声。此外,时序正则化约束潜在轨迹,进一步保证了轨迹的平滑性。
关键设计:LG-Flow Policy使用Transformer网络作为动作序列编码器和解码器。潜在空间流学习器采用连续归一化流(Continuous Normalizing Flow, CNF)。损失函数包括流匹配损失、时序正则化损失和重构损失。几何感知模块使用PointNet提取点云特征,并将其融入到潜在空间流学习器中。执行时多模态调制模块使用注意力机制融合多种模态信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LG-Flow Policy在模拟和真实机器人平台上均取得了显著的性能提升。与基于流的基线方法相比,LG-Flow Policy在轨迹平滑度上提升了约30%,任务成功率提升了约20%。此外,LG-Flow Policy的推理速度接近单步推理,远快于基于扩散模型的方法。这些结果验证了LG-Flow Policy在长时程机器人操作任务中的有效性。
🎯 应用场景
LG-Flow Policy可应用于各种机器人操作任务,如装配、抓取、放置等。该方法能够提升机器人在复杂环境中的操作能力,并降低对专家数据的依赖。未来,该技术有望应用于自动化生产线、智能仓储、家庭服务机器人等领域,实现更高效、更智能的机器人操作。
📄 摘要(原文)
Learning long-horizon robotic manipulation requires jointly achieving expressive behavior modeling, real-time inference, and stable execution, which remains challenging for existing generative policies. Diffusion-based approaches provide strong modeling capacity but typically incur high inference latency, while flow matching enables fast one-step generation yet often leads to unstable execution when applied directly in the raw action space. We propose LG-Flow Policy, a trajectory-level imitation learning framework that performs flow matching in a continuous latent action space. By encoding action sequences into temporally regularized latent trajectories and learning an explicit latent-space flow, the proposed approach decouples global motion structure from low-level control noise, resulting in smooth and reliable long-horizon execution. LG-Flow Policy further incorporates geometry-aware point cloud conditioning and execution-time multimodal modulation, with visual cues evaluated as a representative modality in real-world settings. Experimental results in simulation and on physical robot platforms demonstrate that LG-Flow Policy achieves near single-step inference, substantially improves trajectory smoothness and task success over flow-based baselines operating in the raw action space, and remains significantly more efficient than diffusion-based policies.