Robust and Generalized Humanoid Motion Tracking
作者: Yubiao Ma, Han Yu, Jiayin Xie, Changtai Lv, Qiang Luo, Chi Zhang, Yunpeng Yin, Boyang Xing, Xuemei Ren, Dongdong Zheng
分类: cs.RO
发布日期: 2026-01-30
💡 一句话要点
提出基于动态条件命令聚合的人形机器人运动跟踪方法,实现零样本迁移和鲁棒的sim2real迁移。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人形机器人 运动控制 强化学习 动态条件聚合 零样本迁移
📋 核心要点
- 现有方法难以处理参考运动中的噪声和不一致性,以及闭环执行中局部缺陷的放大问题,导致机器人运动控制的漂移或失败。
- 论文提出一种动态条件命令聚合框架,利用因果时间编码器和多头交叉注意力机制,选择性地聚合上下文信息,从而提高运动控制的鲁棒性。
- 实验结果表明,该方法仅需少量运动数据即可实现零样本迁移到未见运动,并在物理人形机器人上实现了鲁棒的sim2real迁移。
📝 摘要(中文)
学习通用的人形机器人全身控制器极具挑战,因为实际参考运动在转移到机器人领域后可能表现出噪声和不一致性,并且局部缺陷可能被闭环执行放大,导致高度动态和富含接触行为中的漂移或失败。我们提出了一种动态条件命令聚合框架,该框架使用因果时间编码器来总结最近的本体感受,并使用多头交叉注意力命令编码器来基于当前动态选择性地聚合上下文窗口。我们进一步整合了具有随机不稳定初始化和退火向上辅助力的跌倒恢复课程,以提高鲁棒性和抗干扰能力。由此产生的策略仅需要大约3.5小时的运动数据,并支持单阶段端到端训练,无需蒸馏。所提出的方法在不同的参考输入和具有挑战性的运动状态下进行了评估,证明了对未见运动的零样本迁移以及在物理人形机器人上的鲁棒sim2real迁移。
🔬 方法详解
问题定义:现有的人形机器人全身运动控制方法在处理实际应用中获得的参考运动时,容易受到噪声和不一致性的影响。此外,闭环控制系统容易放大局部误差,导致在动态运动和复杂接触场景中出现漂移甚至失败。因此,如何设计一个鲁棒且泛化的运动控制器,使其能够适应各种参考运动并克服环境干扰,是一个关键问题。
核心思路:论文的核心思路是利用动态条件命令聚合,通过分析机器人的当前状态(动力学信息)来选择性地聚合参考运动的上下文信息。这种方法能够有效地过滤掉噪声和不相关的运动信息,并关注与当前状态最相关的部分,从而提高控制器的鲁棒性和泛化能力。
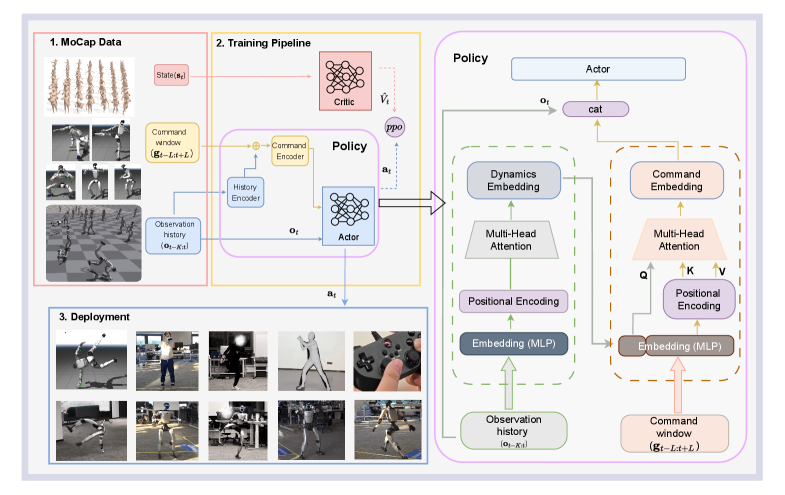
技术框架:整体框架包含以下几个主要模块:1) 因果时间编码器:用于编码机器人的本体感受信息,捕捉其动态状态。2) 多头交叉注意力命令编码器:用于编码参考运动,并根据当前动态状态选择性地聚合上下文窗口。3) 策略网络:基于编码后的状态和运动信息,输出控制指令。4) 跌倒恢复课程:通过随机初始化和辅助力,提高机器人的抗干扰能力和恢复能力。
关键创新:该方法最重要的创新点在于动态条件命令聚合机制。传统的运动控制方法通常直接使用参考运动作为输入,而忽略了机器人自身的动态状态。该方法通过引入动态条件,使得控制器能够根据当前状态自适应地选择参考运动的相关部分,从而提高了控制器的鲁棒性和泛化能力。此外,单阶段端到端训练避免了复杂的蒸馏过程,简化了训练流程。
关键设计:1) 多头交叉注意力机制:用于选择性地聚合参考运动的上下文信息,每个头关注不同的动态特征。2) 跌倒恢复课程:通过退火向上辅助力,逐步提高机器人的抗干扰能力。3) 损失函数:综合考虑了运动跟踪误差、控制力矩和平衡约束等因素,以保证机器人的运动稳定性和自然性。
🖼️ 关键图片

📊 实验亮点
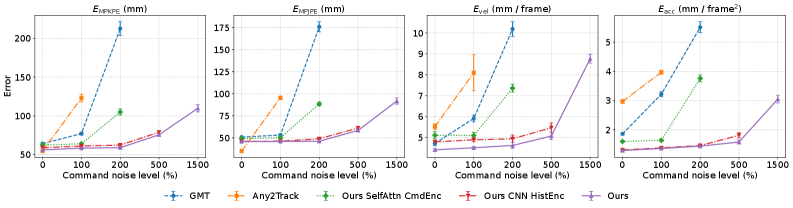
该方法仅使用3.5小时的运动数据进行训练,即可实现对未见运动的零样本迁移。在物理人形机器人上的实验表明,该方法能够有效地克服sim2real gap,实现鲁棒的运动控制。相较于传统方法,该方法在运动跟踪精度和抗干扰能力方面均有显著提升。具体性能数据未知。
🎯 应用场景
该研究成果可应用于各种人形机器人应用场景,例如:家庭服务机器人、工业机器人、搜救机器人等。通过提高机器人的运动控制鲁棒性和泛化能力,使其能够在复杂环境中执行各种任务,例如:行走、跑步、跳跃、攀爬等。此外,该方法还可以应用于虚拟现实和游戏领域,生成更加逼真和自然的机器人运动。
📄 摘要(原文)
Learning a general humanoid whole-body controller is challenging because practical reference motions can exhibit noise and inconsistencies after being transferred to the robot domain, and local defects may be amplified by closed-loop execution, causing drift or failure in highly dynamic and contact-rich behaviors. We propose a dynamics-conditioned command aggregation framework that uses a causal temporal encoder to summarize recent proprioception and a multi-head cross-attention command encoder to selectively aggregate a context window based on the current dynamics. We further integrate a fall recovery curriculum with random unstable initialization and an annealed upward assistance force to improve robustness and disturbance rejection. The resulting policy requires only about 3.5 hours of motion data and supports single-stage end-to-end training without distillation. The proposed method is evaluated under diverse reference inputs and challenging motion regimes, demonstrating zero-shot transfer to unseen motions as well as robust sim-to-real transfer on a physical humanoid robot.