Learning Geometrically-Grounded 3D Visual Representations for View-Generalizable Robotic Manipulation
作者: Di Zhang, Weicheng Duan, Dasen Gu, Hongye Lu, Hai Zhang, Hang Yu, Junqiao Zhao, Guang Chen
分类: cs.RO
发布日期: 2026-01-30
💡 一句话要点
提出基于几何感知的3D视觉表征学习框架,提升机器人操作的视角泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人操作 视角泛化 3D视觉表征 单视角学习 蒸馏训练
📋 核心要点
- 现有方法依赖多视角观测,场景建模不完整,缺乏有效策略训练,限制了机器人操作的视角泛化能力。
- MethodName通过单视角3D预训练学习整体几何表征,并利用多步蒸馏将几何知识迁移到操作策略中。
- 实验表明,MethodName在RLBench任务中优于现有方法,并在视角泛化方面表现出显著优势。
📝 摘要(中文)
本文提出了一种名为MethodName的统一表征-策略学习框架,用于提升机器人操作的视角泛化能力。该方法通过单视角3D预训练范式,利用点云重建和前馈高斯溅射,在多视角监督下学习整体几何表征。在策略学习阶段,MethodName执行多步蒸馏,以保留预训练的几何理解并将其有效地转移到操作技能中。在12个RLBench任务上的实验表明,该方法优于现有最佳方法,平均成功率提高了12.7%。在六个代表性任务上的进一步评估表明,该方法具有强大的零样本视角泛化能力,在中等和大的视角变化下,成功率分别仅下降22.0%和29.7%,而现有最佳方法的下降幅度分别为41.6%和51.5%。
🔬 方法详解
问题定义:现有的机器人操作方法在视角泛化能力上存在不足,主要痛点在于依赖多视角信息进行推理,这在单视角受限的场景中是不切实际的。此外,现有方法对场景的几何结构建模不完整,无法捕捉到精确操作所需的整体和精细的几何信息。最后,缺乏有效的策略训练方法来保留和利用学习到的3D知识。
核心思路:本文的核心思路是利用单视角3D预训练来学习场景的整体几何表征,并通过多步蒸馏将这些几何知识迁移到机器人操作策略中。这种方法旨在克服对多视角信息的依赖,并提高策略在不同视角下的泛化能力。通过预训练学习到的几何信息可以作为策略学习的先验知识,从而加速策略的收敛并提高其鲁棒性。
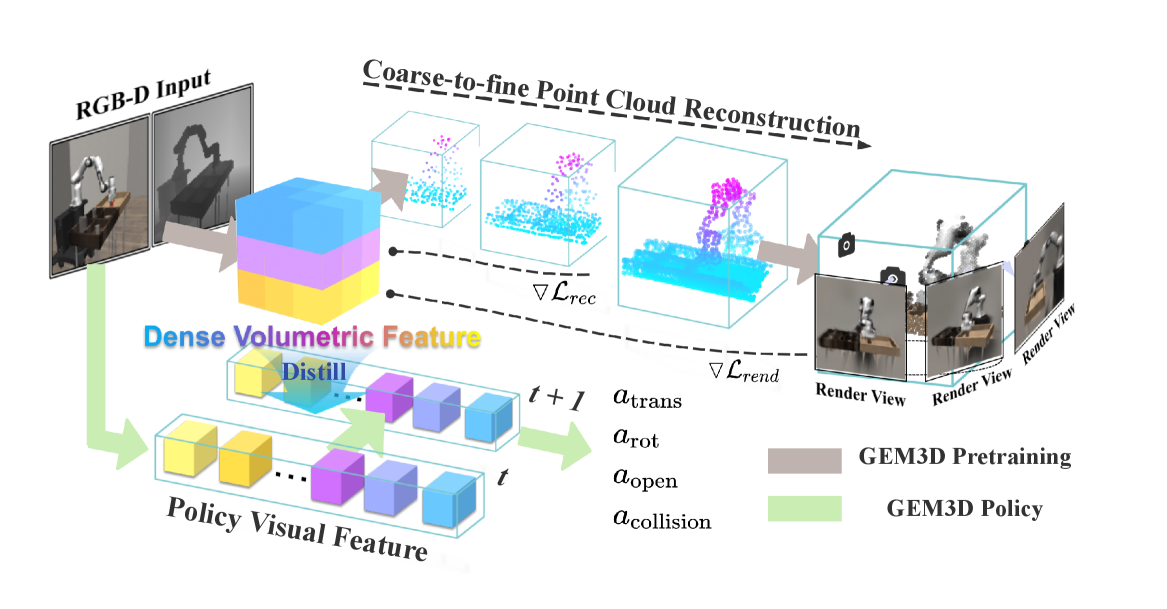
技术框架:MethodName框架包含两个主要阶段:3D表征预训练和策略学习。在3D表征预训练阶段,模型利用单视角图像重建场景的点云,并使用前馈高斯溅射技术在多视角监督下学习几何表征。在策略学习阶段,采用多步蒸馏方法,将预训练的几何知识迁移到操作策略中。整个框架旨在实现视角泛化能力强的机器人操作。
关键创新:该论文的关键创新在于提出了一种单视角3D预训练范式,用于学习机器人操作所需的几何表征。与现有方法相比,该方法不需要在推理阶段依赖多视角信息,从而更适用于实际的单视角场景。此外,多步蒸馏策略有效地将预训练的几何知识迁移到操作策略中,提高了策略的泛化能力。
关键设计:在3D预训练阶段,损失函数包括点云重建损失和高斯溅射渲染损失,用于约束模型学习准确的几何表征。多步蒸馏策略通过逐步减小策略网络和预训练模型之间的差异,从而实现知识迁移。具体的网络结构和参数设置需要参考论文的详细描述,但整体目标是平衡表征学习的准确性和策略学习的效率。
🖼️ 关键图片


📊 实验亮点
MethodName在12个RLBench任务上的平均成功率比现有最佳方法提高了12.7%。在六个代表性任务上的零样本视角泛化实验中,MethodName在中等和大的视角变化下,成功率分别仅下降22.0%和29.7%,而现有最佳方法的下降幅度分别为41.6%和51.5%。这些结果表明,MethodName在视角泛化方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要机器人操作的场景,例如家庭服务、工业自动化、医疗辅助等。通过提高机器人操作的视角泛化能力,可以使机器人在更复杂的环境中执行任务,并减少对环境的限制。未来的研究可以进一步探索如何将该方法应用于更广泛的机器人任务,并提高其在真实世界中的鲁棒性。
📄 摘要(原文)
Real-world robotic manipulation demands visuomotor policies capable of robust spatial scene understanding and strong generalization across diverse camera viewpoints. While recent advances in 3D-aware visual representations have shown promise, they still suffer from several key limitations, including reliance on multi-view observations during inference which is impractical in single-view restricted scenarios, incomplete scene modeling that fails to capture holistic and fine-grained geometric structures essential for precise manipulation, and lack of effective policy training strategies to retain and exploit the acquired 3D knowledge. To address these challenges, we present MethodName, a unified representation-policy learning framework for view-generalizable robotic manipulation. MethodName introduces a single-view 3D pretraining paradigm that leverages point cloud reconstruction and feed-forward gaussian splatting under multi-view supervision to learn holistic geometric representations. During policy learning, MethodName performs multi-step distillation to preserve the pretrained geometric understanding and effectively transfer it to manipulation skills. We conduct experiments on 12 RLBench tasks, where our approach outperforms the previous state-of-the-art method by 12.7% in average success rate. Further evaluation on six representative tasks demonstrates strong zero-shot view generalization, with success rate drops of only 22.0% and 29.7% under moderate and large viewpoint shifts respectively, whereas the state-of-the-art method suffers larger decreases of 41.6% and 51.5%.