Self-Imitated Diffusion Policy for Efficient and Robust Visual Navigation
作者: Runhua Zhang, Junyi Hou, Changxu Cheng, Qiyi Chen, Tao Wang, Wuyue Zhao
分类: cs.RO
发布日期: 2026-01-30
备注: Preprint
💡 一句话要点
提出自模仿扩散策略SIDP,提升视觉导航效率与鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉导航 扩散策略 模仿学习 自模仿学习 机器人 轨迹规划 课程学习
📋 核心要点
- 传统扩散策略视觉导航依赖模仿学习,易受专家数据次优性和冗余性影响,计算成本高。
- SIDP通过奖励引导的自模仿机制,选择性模仿自身采样的高质量轨迹,提升规划效率。
- 实验表明,SIDP在模拟和真实机器人平台上均优于现有方法,推理速度提升显著。
📝 摘要(中文)
扩散策略(DP)在视觉导航中展现出巨大潜力,能够捕捉多模态轨迹分布。然而,大多数DP方法依赖于模仿学习(IL)进行训练,这通常会继承专家演示中的次优性和冗余性,从而需要计算密集型的“生成-过滤”流程,并在推理过程中依赖辅助选择器。为了解决这些挑战,我们提出了一种新的框架——自模仿扩散策略(SIDP),它通过选择性地模仿自身采样的一组轨迹来学习改进的规划。具体来说,SIDP引入了一种奖励引导的自模仿机制,鼓励策略持续高效地产生高质量的轨迹,从而减少对大量采样和后过滤的依赖。在训练过程中,我们采用奖励驱动的课程学习范式来缓解低效的数据利用率,并采用目标无关的探索进行轨迹增强,以提高规划的鲁棒性。在全面的模拟基准测试中进行的大量评估表明,SIDP显著优于以前的方法,实际实验证实了其在多个机器人平台上的有效性。在Jetson Orin Nano上,SIDP的推理速度比基线NavDP快2.5倍,即110ms VS 273ms,从而实现了高效的实时部署。
🔬 方法详解
问题定义:现有基于扩散策略的视觉导航方法,通常依赖模仿学习从专家演示中学习。然而,专家演示数据可能包含次优或冗余的轨迹,导致策略学习效率低下,需要大量的采样和后处理(如轨迹选择)才能获得较好的性能,计算成本高昂。此外,模仿学习也可能限制策略探索新的、更优的解决方案。
核心思路:SIDP的核心思路是通过让策略“模仿自己”来提升性能。具体来说,策略首先生成一批轨迹,然后根据奖励函数筛选出高质量的轨迹,并利用这些轨迹重新训练策略。这种自模仿过程可以有效地去除次优轨迹的影响,并鼓励策略探索更优的解决方案。奖励引导的自模仿机制是关键,它确保策略学习模仿的是自身表现最好的行为。
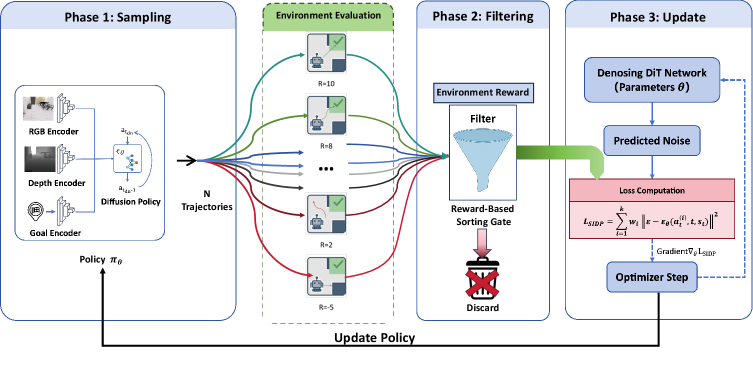
技术框架:SIDP的整体框架包含以下几个主要阶段:1) 扩散策略生成轨迹:使用扩散模型生成一组候选轨迹。2) 奖励评估:使用奖励函数评估每个轨迹的质量。3) 轨迹选择:选择奖励最高的轨迹子集。4) 自模仿学习:使用选择的轨迹重新训练扩散策略。5) 课程学习:逐渐增加任务难度,提升策略的泛化能力。6) 目标无关探索:通过探索未知区域,增加轨迹的多样性,提升鲁棒性。
关键创新:SIDP最关键的创新点在于其自模仿学习机制。与传统的模仿学习不同,SIDP不是模仿外部专家,而是模仿自身表现最好的行为。这种自模仿机制可以有效地去除次优轨迹的影响,并鼓励策略探索更优的解决方案。此外,奖励引导的轨迹选择和课程学习也对提升性能起到了重要作用。
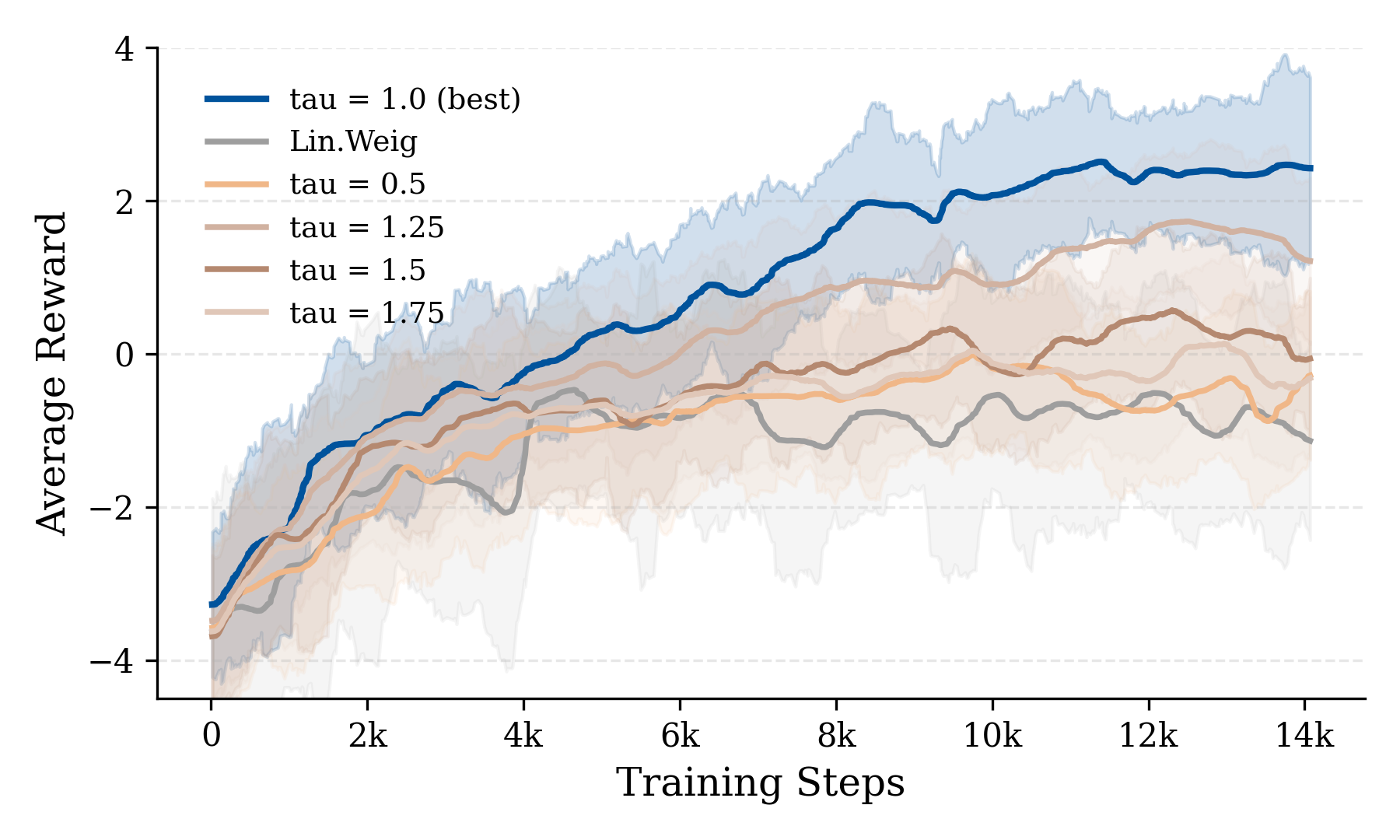
关键设计:SIDP的关键设计包括:1) 奖励函数的设计:奖励函数需要能够准确地评估轨迹的质量,例如,可以结合目标距离、碰撞惩罚等因素。2) 轨迹选择策略:选择策略需要能够有效地选择出高质量的轨迹,例如,可以选择奖励最高的top-k个轨迹。3) 课程学习策略:课程学习策略需要能够逐渐增加任务难度,例如,可以逐渐增加目标距离或环境复杂度。4) 扩散模型的网络结构和训练方式:扩散模型的选择会影响轨迹生成的多样性和质量,需要根据具体任务进行选择和调整。
🖼️ 关键图片

📊 实验亮点
SIDP在模拟环境中取得了显著的性能提升,超越了现有的视觉导航方法。在真实机器人平台上的实验表明,SIDP能够有效地进行自主导航。特别是在Jetson Orin Nano上的实验中,SIDP的推理速度比基线NavDP快2.5倍,从273ms降低到110ms,证明了其高效性,使其能够满足实时部署的需求。
🎯 应用场景
SIDP可应用于各种视觉导航任务,例如机器人自主导航、无人机路径规划、自动驾驶等。其高效性和鲁棒性使其特别适用于计算资源有限的平台,如小型机器人和无人机。该方法能够提升机器人在复杂环境中的自主导航能力,降低对人工干预的依赖,具有重要的实际应用价值。
📄 摘要(原文)
Diffusion policies (DP) have demonstrated significant potential in visual navigation by capturing diverse multi-modal trajectory distributions. However, standard imitation learning (IL), which most DP methods rely on for training, often inherits sub-optimality and redundancy from expert demonstrations, thereby necessitating a computationally intensive "generate-then-filter" pipeline that relies on auxiliary selectors during inference. To address these challenges, we propose Self-Imitated Diffusion Policy (SIDP), a novel framework that learns improved planning by selectively imitating a set of trajectories sampled from itself. Specifically, SIDP introduces a reward-guided self-imitation mechanism that encourages the policy to consistently produce high-quality trajectories efficiently, rather than outputs of inconsistent quality, thereby reducing reliance on extensive sampling and post-filtering. During training, we employ a reward-driven curriculum learning paradigm to mitigate inefficient data utility, and goal-agnostic exploration for trajectory augmentation to improve planning robustness. Extensive evaluations on a comprehensive simulation benchmark show that SIDP significantly outperforms previous methods, with real-world experiments confirming its effectiveness across multiple robotic platforms. On Jetson Orin Nano, SIDP delivers a 2.5$\times$ faster inference than the baseline NavDP, i.e., 110ms VS 273ms, enabling efficient real-time deployment.