MTDrive: Multi-turn Interactive Reinforcement Learning for Autonomous Driving
作者: Xidong Li, Mingyu Guo, Chenchao Xu, Bailin Li, Wenjing Zhu, Yangang Zou, Rui Chen, Zehuan Wang
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-01-30
💡 一句话要点
MTDrive:用于自动驾驶的多轮交互式强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 强化学习 多模态大语言模型 轨迹规划 多轮交互
📋 核心要点
- 现有自动驾驶轨迹规划方法在处理复杂场景时,由于单轮推理的限制,难以进行迭代优化。
- MTDrive提出多轮交互框架,利用MLLM根据环境反馈迭代优化轨迹,并设计mtGRPO缓解奖励稀疏性问题。
- 实验表明,MTDrive在NAVSIM基准测试中表现优于现有方法,并且通过系统优化提升了训练吞吐量。
📝 摘要(中文)
轨迹规划是自动驾驶的核心任务,需要在各种场景中预测安全舒适的路径。将多模态大型语言模型(MLLM)与强化学习(RL)相结合,在解决“长尾”场景方面显示出前景。然而,现有方法仅限于单轮推理,限制了它们处理需要迭代改进的复杂任务的能力。为了克服这个限制,我们提出了MTDrive,一个多轮框架,使MLLM能够根据环境反馈迭代地改进轨迹。MTDrive引入了多轮组相对策略优化(mtGRPO),通过计算跨轮次的相对优势来缓解奖励稀疏性。我们进一步构建了一个来自闭环仿真的交互式轨迹理解数据集,以支持多轮训练。在NAVSIM基准上的实验表明,与现有方法相比,性能更优,验证了我们的多轮推理范式的有效性。此外,我们实现了系统级优化,以减少由高分辨率图像和多轮序列引起的数据传输开销,实现了2.5倍的训练吞吐量。我们的数据、模型和代码将很快发布。
🔬 方法详解
问题定义:现有基于MLLM的自动驾驶轨迹规划方法通常采用单轮推理,即模型一次性生成轨迹,无法根据环境反馈进行迭代优化。这导致在复杂或“长尾”场景下,模型难以生成高质量的轨迹。奖励稀疏性也是一个挑战,因为只有最终成功才能获得奖励,中间步骤难以评估。
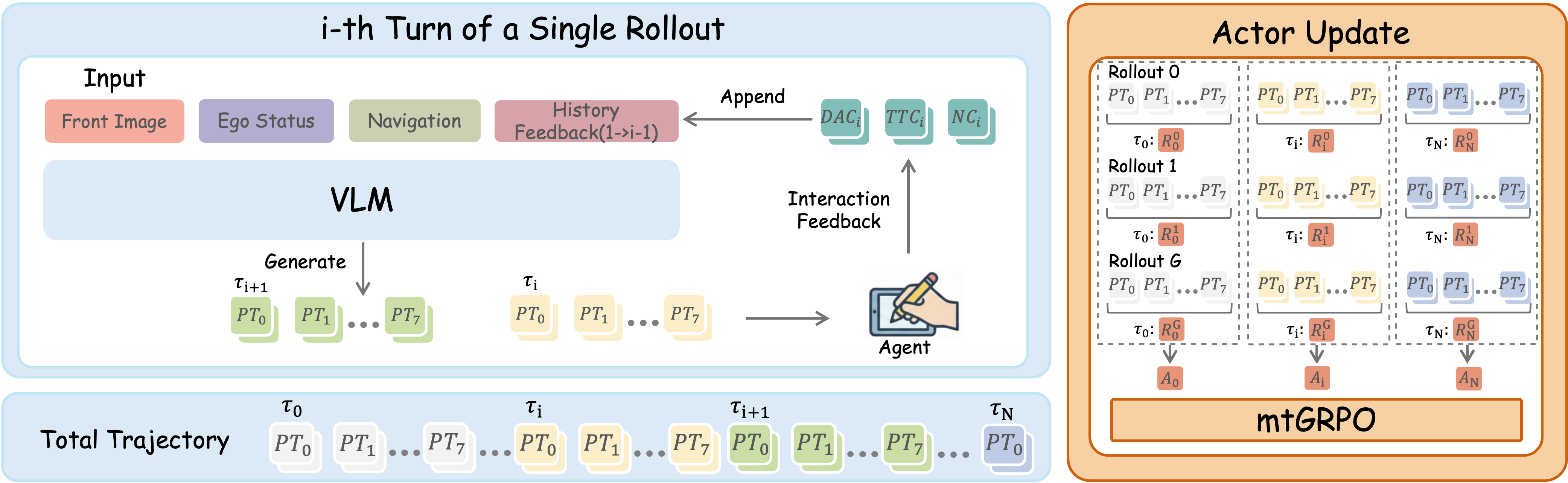
核心思路:MTDrive的核心思路是将轨迹规划过程分解为多个交互轮次,允许MLLM在每一轮根据环境反馈(例如,车辆状态、周围环境信息)调整轨迹。通过多轮迭代,模型可以逐步优化轨迹,从而更好地适应复杂场景。同时,引入相对策略优化,缓解奖励稀疏性问题。
技术框架:MTDrive框架包含以下主要模块:1) MLLM作为策略网络,负责根据环境信息生成轨迹;2) 仿真环境,用于模拟车辆行驶过程并提供反馈;3) 多轮组相对策略优化(mtGRPO)算法,用于训练策略网络。整个流程是:MLLM根据当前环境状态生成轨迹,仿真环境执行该轨迹并返回新的环境状态,MLLM根据新的状态和历史信息再次生成轨迹,如此迭代多轮,最终完成轨迹规划。
关键创新:MTDrive的关键创新在于引入了多轮交互式强化学习框架,打破了单轮推理的限制,使模型能够根据环境反馈进行迭代优化。此外,mtGRPO算法通过计算跨轮次的相对优势,有效地缓解了奖励稀疏性问题。交互式轨迹理解数据集的构建也为多轮训练提供了数据支持。
关键设计:mtGRPO算法的关键在于计算相对优势。具体来说,它将多个轮次的轨迹视为一个组,并计算每个轮次相对于该组内其他轮次的优势。这种相对优势可以更准确地评估每个轮次的贡献,从而更有效地训练策略网络。此外,系统级优化,例如减少高分辨率图像的数据传输,也是提高训练效率的关键。
🖼️ 关键图片


📊 实验亮点
MTDrive在NAVSIM基准测试中表现出优于现有方法的性能。通过引入多轮交互式强化学习框架和mtGRPO算法,MTDrive能够更好地处理复杂场景,并有效地缓解奖励稀疏性问题。此外,系统级优化使训练吞吐量提高了2.5倍,显著提升了训练效率。这些结果验证了MTDrive框架的有效性和实用性。
🎯 应用场景
MTDrive可应用于各种自动驾驶场景,尤其是在复杂、动态或未知的环境中。例如,城市道路的交通拥堵、恶劣天气条件下的驾驶、以及应对突发事件等。该研究有助于提高自动驾驶系统的安全性和可靠性,加速自动驾驶技术的商业化落地,并为未来的智能交通系统提供技术支持。
📄 摘要(原文)
Trajectory planning is a core task in autonomous driving, requiring the prediction of safe and comfortable paths across diverse scenarios. Integrating Multi-modal Large Language Models (MLLMs) with Reinforcement Learning (RL) has shown promise in addressing "long-tail" scenarios. However, existing methods are constrained to single-turn reasoning, limiting their ability to handle complex tasks requiring iterative refinement. To overcome this limitation, we present MTDrive, a multi-turn framework that enables MLLMs to iteratively refine trajectories based on environmental feedback. MTDrive introduces Multi-Turn Group Relative Policy Optimization (mtGRPO), which mitigates reward sparsity by computing relative advantages across turns. We further construct an interactive trajectory understanding dataset from closed-loop simulation to support multi-turn training. Experiments on the NAVSIM benchmark demonstrate superior performance compared to existing methods, validating the effectiveness of our multi-turn reasoning paradigm. Additionally, we implement system-level optimizations to reduce data transfer overhead caused by high-resolution images and multi-turn sequences, achieving 2.5x training throughput. Our data, models, and code will be made available soon.