Adapting Reinforcement Learning for Path Planning in Constrained Parking Scenarios
作者: Feng Tao, Luca Paparusso, Chenyi Gu, Robin Koehler, Chenxu Wu, Xinyu Huang, Christian Juette, David Paz, Ren Liu
分类: cs.RO, cs.AI
发布日期: 2026-01-30
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于深度强化学习的路径规划框架,解决约束泊车场景下的实时规划问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 路径规划 自动泊车 约束优化 实时规划
📋 核心要点
- 传统路径规划器在感知受限和复杂环境下计算成本高,难以实时部署。
- 利用深度强化学习,直接学习车辆运动学约束下的导航策略,无需精确感知。
- 实验表明,该方法在约束泊车场景中显著优于传统规划器,成功率和效率均有提升。
📝 摘要(中文)
本文提出了一种基于深度强化学习(DRL)的框架,用于解决约束环境下实时路径规划问题,特别是在需要多次倒车和调整的狭窄泊车场景中。与传统的经典规划器不同,该方案不依赖于理想化的感知信息,原则上可以避免对定位和跟踪等额外模块的需求,从而简化了实现。在测试阶段,策略通过单次前向传播生成动作,计算量小,适合实时部署。该任务被建模为基于自行车模型动力学的序列决策问题,使智能体能够直接学习符合车辆运动学和环境约束的导航策略。论文还开发了一个新的基准测试,用于训练和评估,涵盖了各种具有挑战性的场景。实验结果表明,该方法在成功率和效率方面均达到了最先进的水平,成功率比经典规划器基线提高了96%,效率提高了52%。该基准测试已开源,旨在促进自动驾驶系统领域的未来研究。
🔬 方法详解
问题定义:论文旨在解决在具有约束的泊车场景中,传统路径规划方法由于依赖精确感知和计算复杂度高而难以实现实时路径规划的问题。现有方法对感知噪声敏感,并且在线搜索过程耗时,不适用于复杂环境下的实时应用。
核心思路:论文的核心思路是利用深度强化学习(DRL)直接学习在约束环境下车辆的导航策略。通过将路径规划问题建模为序列决策过程,智能体可以在与环境交互的过程中学习到最优的动作序列,从而实现高效的路径规划。这种方法避免了对精确感知的依赖,并且在测试阶段只需要进行一次前向传播,计算量小,适合实时部署。
技术框架:整体框架包括以下几个主要部分:1) 环境建模:使用自行车模型来模拟车辆的运动学特性,并考虑环境的约束条件。2) 强化学习智能体:使用深度神经网络作为策略网络,输入是车辆的状态信息(例如位置、方向等),输出是车辆的控制指令(例如转向角、加速度等)。3) 奖励函数设计:设计合适的奖励函数来引导智能体学习到期望的导航行为,例如到达目标位置、避免碰撞等。4) 训练过程:通过与环境的交互,使用强化学习算法(例如PPO)来更新策略网络的参数,使其能够更好地完成路径规划任务。
关键创新:该论文的关键创新在于将深度强化学习应用于约束泊车场景下的实时路径规划问题,并设计了一个端到端的学习框架。与传统的基于搜索的规划方法相比,该方法不需要进行在线搜索,计算效率更高。此外,该方法对感知噪声具有一定的鲁棒性,可以在不依赖精确感知的情况下实现有效的路径规划。
关键设计:论文中使用了Proximal Policy Optimization (PPO)算法进行训练。奖励函数的设计至关重要,包括引导智能体到达目标位置的奖励、避免碰撞的惩罚以及控制动作的平滑性奖励。网络结构方面,使用了多层感知机(MLP)作为策略网络,输入是车辆的状态信息,输出是车辆的控制指令。状态信息包括车辆的位置、方向、速度等。控制指令包括转向角和加速度。
🖼️ 关键图片
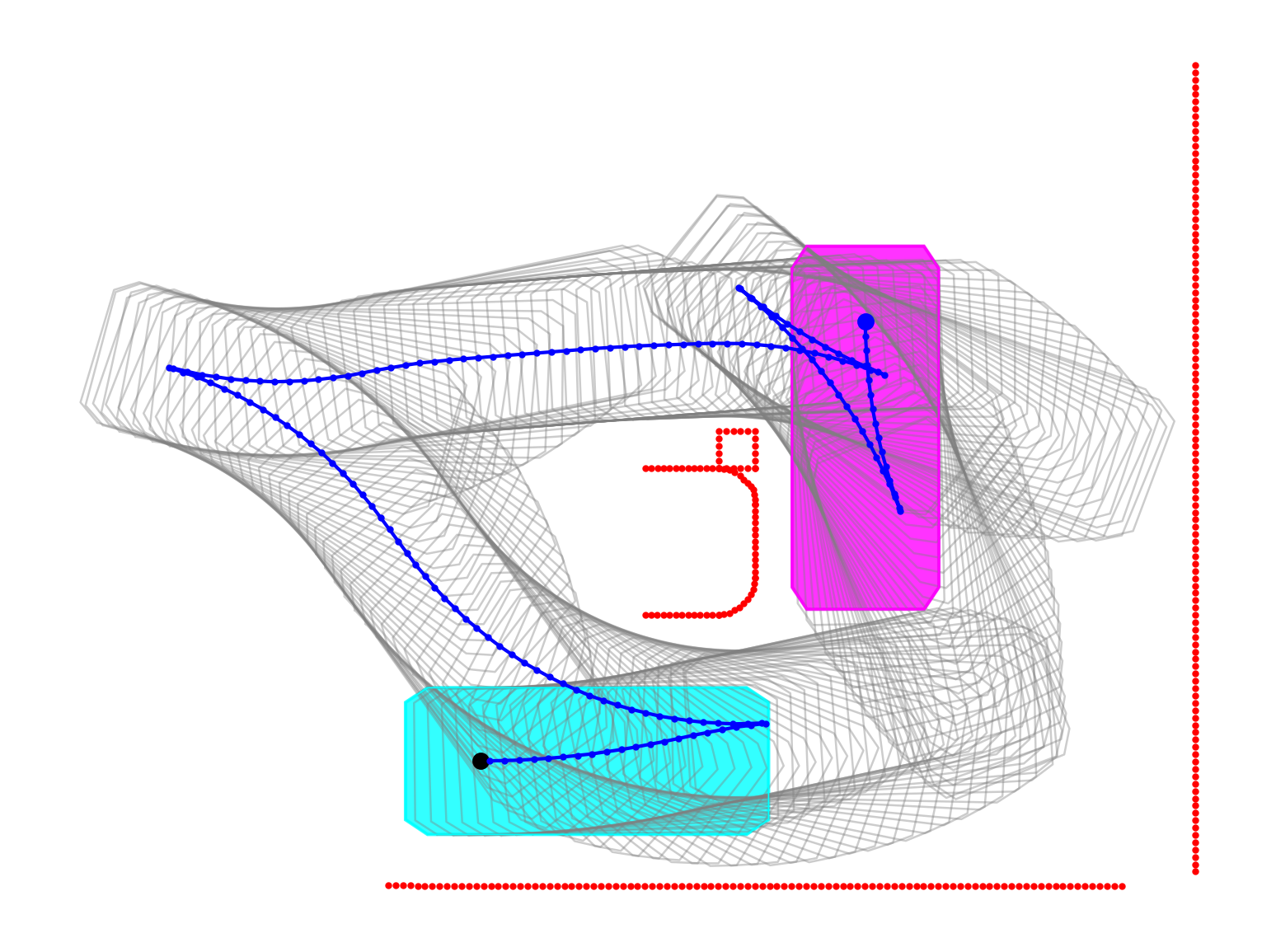

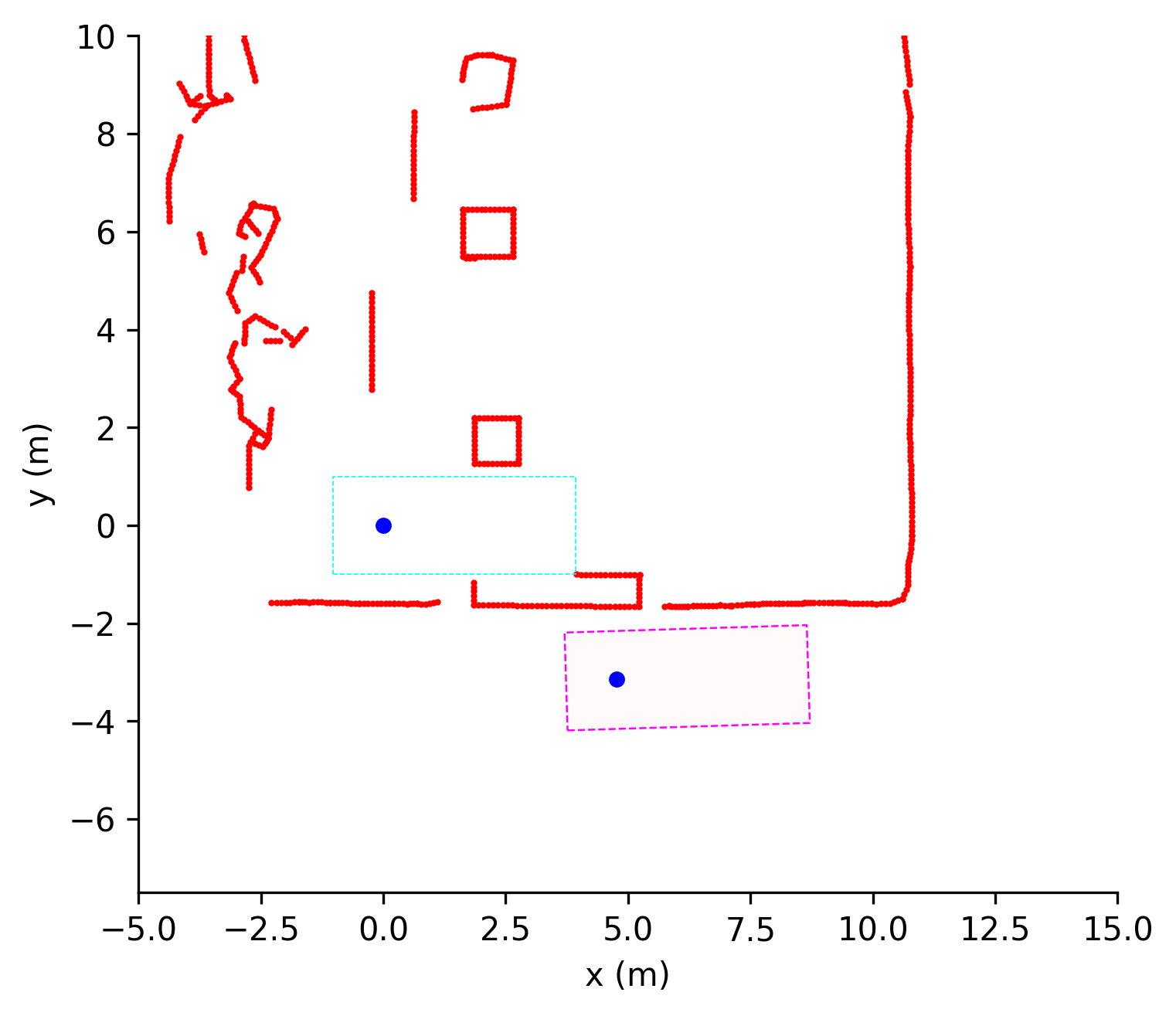
📊 实验亮点
实验结果表明,该方法在约束泊车场景中取得了显著的性能提升。与传统的经典规划器相比,该方法在成功率方面提高了96%,在效率方面提高了52%。这些结果表明,基于深度强化学习的路径规划方法在解决复杂环境下的实时路径规划问题方面具有很大的潜力。
🎯 应用场景
该研究成果可应用于自动泊车系统、自动驾驶车辆以及其他需要在约束环境下进行路径规划的机器人应用。通过深度强化学习,可以实现更高效、更鲁棒的路径规划,提高自动驾驶系统的安全性和可靠性。未来,该方法可以扩展到更复杂的环境和任务中,例如城市道路的自动驾驶。
📄 摘要(原文)
Real-time path planning in constrained environments remains a fundamental challenge for autonomous systems. Traditional classical planners, while effective under perfect perception assumptions, are often sensitive to real-world perception constraints and rely on online search procedures that incur high computational costs. In complex surroundings, this renders real-time deployment prohibitive. To overcome these limitations, we introduce a Deep Reinforcement Learning (DRL) framework for real-time path planning in parking scenarios. In particular, we focus on challenging scenes with tight spaces that require a high number of reversal maneuvers and adjustments. Unlike classical planners, our solution does not require ideal and structured perception, and in principle, could avoid the need for additional modules such as localization and tracking, resulting in a simpler and more practical implementation. Also, at test time, the policy generates actions through a single forward pass at each step, which is lightweight enough for real-time deployment. The task is formulated as a sequential decision-making problem grounded in a bicycle model dynamics, enabling the agent to directly learn navigation policies that respect vehicle kinematics and environmental constraints in the closed-loop setting. A new benchmark is developed to support both training and evaluation, capturing diverse and challenging scenarios. Our approach achieves state-of-the-art success rates and efficiency, surpassing classical planner baselines by +96% in success rate and +52% in efficiency. Furthermore, we release our benchmark as an open-source resource for the community to foster future research in autonomous systems. The benchmark and accompanying tools are available at https://github.com/dqm5rtfg9b-collab/Constrained_Parking_Scenarios.