RoboStriker: Hierarchical Decision-Making for Autonomous Humanoid Boxing
作者: Kangning Yin, Zhe Cao, Wentao Dong, Weishuai Zeng, Tianyi Zhang, Qiang Zhang, Jingbo Wang, Jiangmiao Pang, Ming Zhou, Weinan Zhang
分类: cs.RO
发布日期: 2026-01-30
💡 一句话要点
RoboStriker:提出一种分层决策框架,实现自主人形机器人拳击
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人形机器人 强化学习 多智能体 运动控制 潜在空间 分层决策
📋 核心要点
- 人形机器人拳击面临高维动力学和缺乏运动先验的挑战,传统MARL方法难以直接应用。
- RoboStriker通过分层框架解耦战略推理和物理执行,利用潜在空间学习稳定多智能体训练。
- 实验表明,RoboStriker在模拟环境中表现出卓越的竞争性能,并具备一定的sim-to-real迁移能力。
📝 摘要(中文)
在人形机器人中实现人类水平的竞争智能和身体敏捷性仍然是一个重大挑战,尤其是在像拳击这样接触密集和高度动态的任务中。多智能体强化学习(MARL)为战略交互提供了一个原则性框架,但其直接应用于人形机器人控制受到高维接触动力学和缺乏强物理运动先验的阻碍。我们提出了RoboStriker,一个分层的三阶段框架,通过将高层战略推理与低层物理执行解耦,实现完全自主的人形机器人拳击。该框架首先通过在人类运动捕捉数据上训练单智能体运动跟踪器来学习全面的拳击技能库。然后,这些技能被提炼成一个结构化的潜在流形,通过将高斯参数化分布投影到单位超球面上进行正则化。这种拓扑约束有效地将探索限制在物理上合理的运动子空间。最后,我们引入了潜在空间神经虚拟自我博弈(LS-NFSP),其中竞争智能体通过在潜在动作空间而不是原始运动空间中交互来学习竞争策略,从而显著稳定多智能体训练。实验结果表明,RoboStriker在模拟中实现了卓越的竞争性能,并表现出从模拟到真实的迁移能力。我们的网站可在RoboStriker上找到。
🔬 方法详解
问题定义:论文旨在解决人形机器人自主拳击的问题,现有方法直接应用多智能体强化学习(MARL)到高维运动控制,由于接触动力学复杂和缺乏物理运动先验,训练过程不稳定且难以获得理想的控制策略。
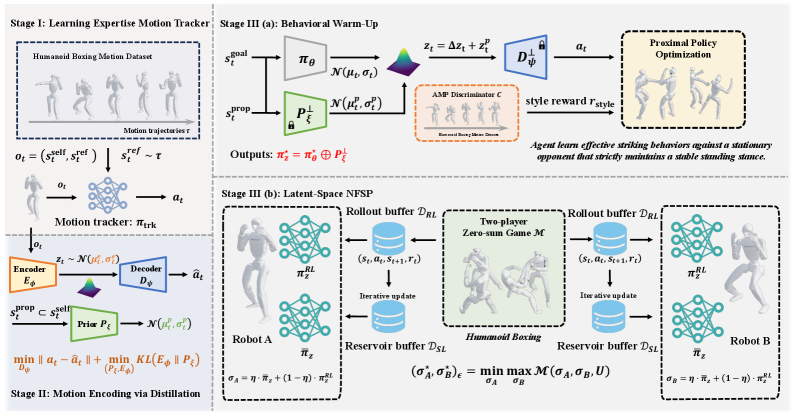
核心思路:论文的核心思路是将复杂的拳击任务分解为三个阶段:首先学习单智能体的运动技能库,然后将这些技能提炼到低维潜在空间,最后在潜在空间中进行多智能体策略学习。通过这种分层解耦的方式,降低了学习难度,并提高了训练的稳定性。
技术框架:RoboStriker框架包含三个阶段:1) 运动技能学习:利用人类运动捕捉数据训练单智能体运动跟踪器,学习全面的拳击技能。2) 潜在空间构建:将学习到的技能提炼到结构化的潜在流形中,通过将高斯参数化分布投影到单位超球面上进行正则化,约束探索空间。3) 多智能体策略学习:在潜在空间中,使用Latent-Space Neural Fictitious Self-Play (LS-NFSP)算法进行多智能体策略学习,学习竞争策略。
关键创新:论文的关键创新在于将高维运动控制问题转化为低维潜在空间中的策略学习问题。通过学习运动技能库并构建潜在空间,有效降低了多智能体强化学习的难度,并提高了训练的稳定性。此外,使用LS-NFSP算法在潜在空间中进行策略学习,进一步提升了训练效率。
关键设计:在潜在空间构建阶段,使用高斯参数化分布来表示技能,并通过将其投影到单位超球面上进行正则化,保证潜在空间的连续性和物理可行性。在多智能体策略学习阶段,使用LS-NFSP算法,该算法结合了神经虚拟自我博弈(NFSP)和潜在空间表示,能够有效地学习竞争策略。
🖼️ 关键图片

📊 实验亮点
RoboStriker在模拟环境中取得了显著的成果,证明了其在人形机器人拳击任务中的有效性。通过与基线方法对比,RoboStriker展现出更强的竞争力和更高的胜率。此外,该方法还表现出一定的sim-to-real迁移能力,表明其具有实际应用潜力。具体性能数据在论文中给出,但摘要未提供量化指标。
🎯 应用场景
RoboStriker的研究成果可应用于人形机器人的运动控制、人机交互、以及其他需要复杂运动技能的任务中。该方法能够提升机器人在动态环境中的适应性和智能水平,为机器人进入体育竞技、灾难救援等领域奠定基础。未来,该技术有望扩展到其他类型的机器人和更复杂的任务中。
📄 摘要(原文)
Achieving human-level competitive intelligence and physical agility in humanoid robots remains a major challenge, particularly in contact-rich and highly dynamic tasks such as boxing. While Multi-Agent Reinforcement Learning (MARL) offers a principled framework for strategic interaction, its direct application to humanoid control is hindered by high-dimensional contact dynamics and the absence of strong physical motion priors. We propose RoboStriker, a hierarchical three-stage framework that enables fully autonomous humanoid boxing by decoupling high-level strategic reasoning from low-level physical execution. The framework first learns a comprehensive repertoire of boxing skills by training a single-agent motion tracker on human motion capture data. These skills are subsequently distilled into a structured latent manifold, regularized by projecting the Gaussian-parameterized distribution onto a unit hypersphere. This topological constraint effectively confines exploration to the subspace of physically plausible motions. In the final stage, we introduce Latent-Space Neural Fictitious Self-Play (LS-NFSP), where competing agents learn competitive tactics by interacting within the latent action space rather than the raw motor space, significantly stabilizing multi-agent training. Experimental results demonstrate that RoboStriker achieves superior competitive performance in simulation and exhibits sim-to-real transfer. Our website is available at RoboStriker.