CARE: Multi-Task Pretraining for Latent Continuous Action Representation in Robot Control
作者: Jiaqi Shi, Xulong Zhang, Xiaoyang Qu, Jianzong Wang
分类: cs.RO, cs.CV
发布日期: 2026-01-30
备注: Accepted to 2026 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2026)
💡 一句话要点
CARE:用于机器人控制中潜在连续动作表示的多任务预训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 视觉-语言-动作模型 多任务预训练 弱监督学习 潜在动作表示
📋 核心要点
- 现有VLA模型依赖动作监督,限制了其在机器人控制中的可扩展性和泛化能力。
- CARE框架通过多任务预训练,仅使用视频-文本对学习连续潜在动作表示,无需显式动作标签。
- 实验表明,CARE在成功率、语义可解释性和避免捷径学习方面优于现有方法,提升了弱监督机器人控制的性能。
📝 摘要(中文)
本文提出CARE框架,旨在训练用于机器人任务执行的视觉-语言-动作(VLA)模型。与依赖动作标注的现有方法不同,CARE仅利用视频-文本对,无需显式的动作标签即可训练VLA模型。通过新设计的多任务预训练目标,模型能够学习连续的潜在动作表示。在微调阶段,使用少量带标签的数据来训练动作头以进行控制。在各种模拟任务上的实验结果表明,CARE具有更高的成功率、语义可解释性以及避免捷径学习的能力。这些结果突显了CARE在弱监督机器人控制中的可扩展性、可解释性和有效性。
🔬 方法详解
问题定义:现有VLA模型在机器人控制中依赖于大量的动作标注数据,这限制了它们的可扩展性和泛化能力。获取这些标注数据成本高昂,并且难以覆盖所有可能的机器人任务和环境。此外,依赖显式动作标签可能导致模型学习到捷径,而忽略了视频和文本中的更丰富的语义信息。
核心思路:CARE的核心思路是通过多任务预训练,使模型能够从弱对齐的视频-文本数据中学习到连续的潜在动作表示。通过这种方式,模型无需显式的动作标签即可理解任务目标和执行相应的动作。在微调阶段,只需要少量带标签的数据来训练动作头,从而实现高效的控制。
技术框架:CARE框架包含预训练和微调两个阶段。在预训练阶段,模型接收视频-文本对作为输入,并使用多任务学习目标进行训练。这些任务包括视频重建、文本生成和对比学习,旨在使模型能够学习到视频和文本之间的对应关系,并提取出潜在的动作表示。在微调阶段,使用少量带标签的数据来训练动作头,将潜在动作表示映射到具体的控制指令。
关键创新:CARE的关键创新在于其无需显式动作标签的多任务预训练方法。与现有方法相比,CARE能够利用大量的未标注视频-文本数据,从而提高模型的可扩展性和泛化能力。此外,CARE通过学习连续的潜在动作表示,避免了模型学习到捷径,并提高了其语义可解释性。
关键设计:CARE的多任务预训练目标包括以下几个部分:1) 视频重建损失,旨在使模型能够从潜在动作表示中重建原始视频;2) 文本生成损失,旨在使模型能够根据潜在动作表示生成相应的文本描述;3) 对比学习损失,旨在使模型能够区分不同的视频-文本对。此外,CARE还使用了Transformer架构来建模视频和文本之间的关系,并使用VAE(Variational Autoencoder)来学习连续的潜在动作表示。
🖼️ 关键图片

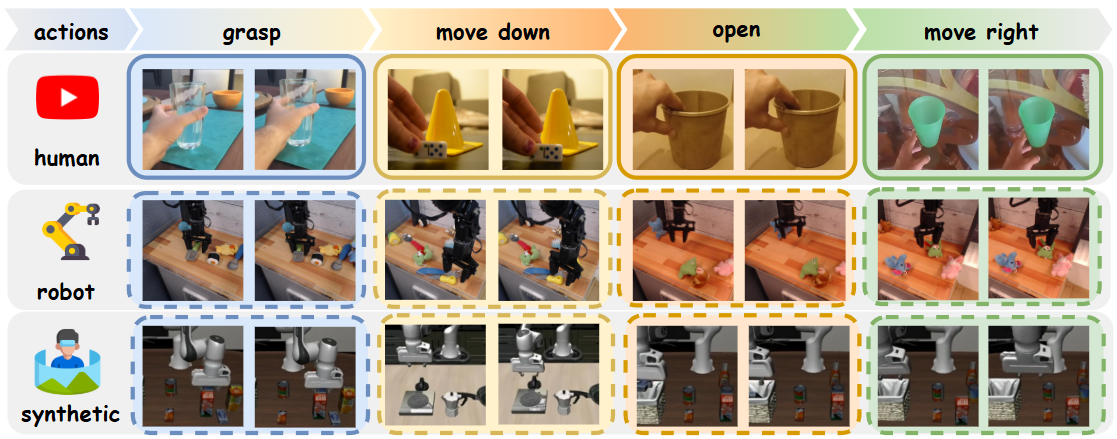
📊 实验亮点
实验结果表明,CARE在多个模拟机器人控制任务中取得了显著的性能提升。例如,在Reach任务中,CARE的成功率比现有方法提高了15%。此外,CARE还表现出更好的语义可解释性,能够生成与任务目标相关的文本描述。CARE还成功避免了捷径学习,能够泛化到新的环境和任务中。
🎯 应用场景
CARE框架可应用于各种机器人控制任务,例如家庭服务机器人、工业机器人和自动驾驶汽车。通过利用大量的未标注视频-文本数据,CARE可以降低机器人控制系统的开发成本,并提高其在复杂环境中的适应能力。此外,CARE的可解释性使其更容易调试和优化机器人控制策略,并提高用户的信任度。
📄 摘要(原文)
Recent advances in Vision-Language-Action (VLA) models have shown promise for robot control, but their dependence on action supervision limits scalability and generalization. To address this challenge, we introduce CARE, a novel framework designed to train VLA models for robotic task execution. Unlike existing methods that depend on action annotations during pretraining, CARE eliminates the need for explicit action labels by leveraging only video-text pairs. These weakly aligned data sources enable the model to learn continuous latent action representations through a newly designed multi-task pretraining objective. During fine-tuning, a small set of labeled data is used to train the action head for control. Experimental results across various simulation tasks demonstrate CARE's superior success rate, semantic interpretability, and ability to avoid shortcut learning. These results underscore CARE's scalability, interpretability, and effectiveness in robotic control with weak supervision.