PocketDP3: Efficient Pocket-Scale 3D Visuomotor Policy
作者: Jinhao Zhang, Zhexuan Zhou, Huizhe Li, Yichen Lai, Wenlong Xia, Haoming Song, Youmin Gong, Jie Me
分类: cs.RO
发布日期: 2026-01-29
💡 一句话要点
PocketDP3:高效的口袋级3D视觉运动策略,显著降低模型参数量
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D视觉 扩散策略 机器人操作 MLP-Mixer 轻量化模型
📋 核心要点
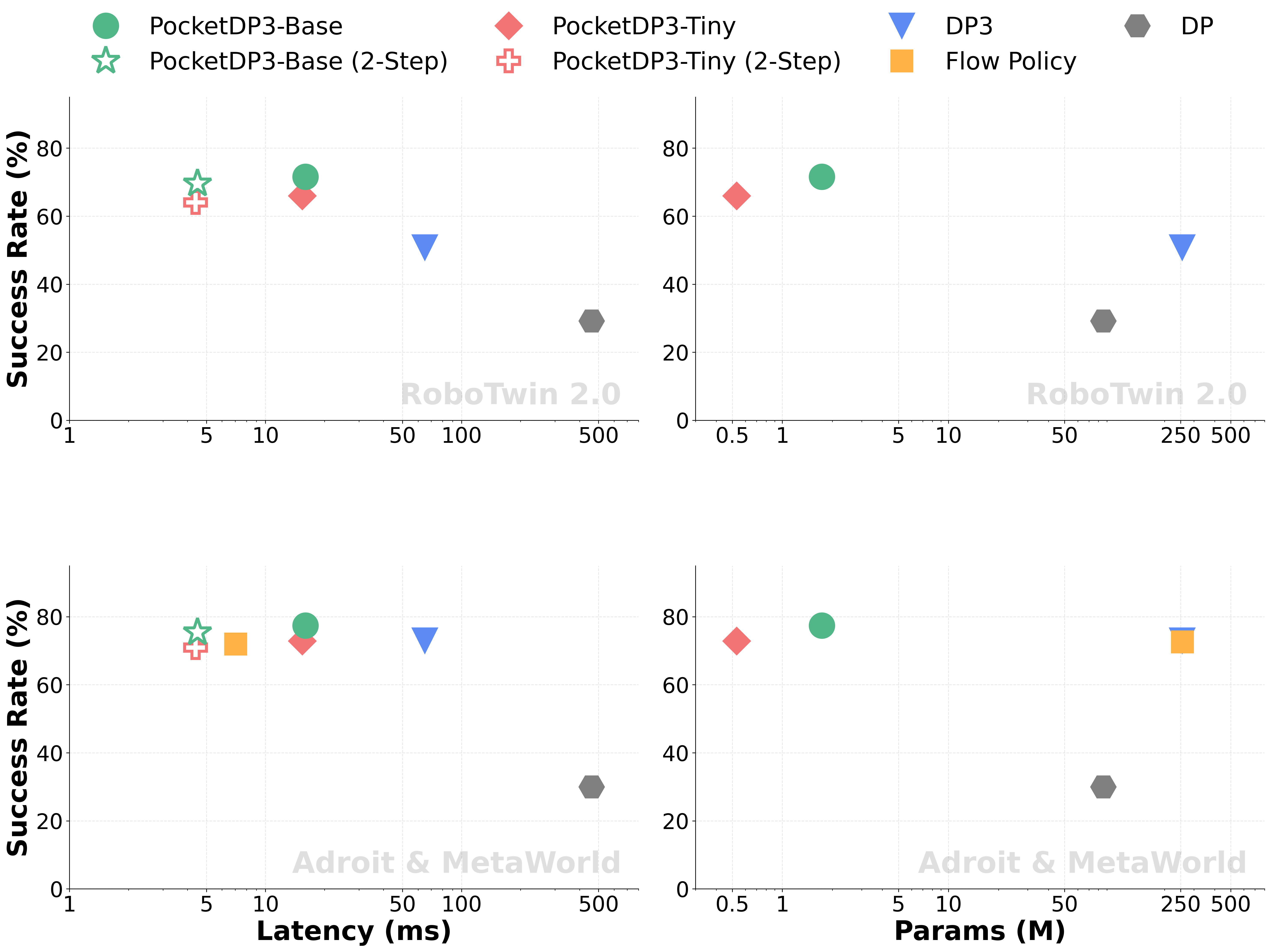
- 现有3D视觉扩散策略模型解码器参数量巨大,存在参数浪费问题,限制了其在资源受限设备上的部署。
- PocketDP3采用轻量级Diffusion Mixer (DiM)替换传统U-Net解码器,实现高效的时空和通道融合,大幅减少模型参数。
- 实验表明,PocketDP3在多个基准测试中以极少的参数量达到SOTA性能,并加速推理,同时具备良好的真实世界迁移性。
📝 摘要(中文)
本文提出了一种名为PocketDP3的口袋级3D扩散策略,旨在解决现有基于3D视觉的扩散策略中存在的架构不匹配问题,即小型高效的点云编码器与大型解码器配对,导致解码器中存在大量参数浪费。PocketDP3使用基于MLP-Mixer块构建的轻量级Diffusion Mixer (DiM)取代了传统的条件U-Net解码器,实现了跨时间和通道维度的高效融合,从而显著减少了模型尺寸。该方法无需额外的知识蒸馏技术,即可支持两步推理且不损失性能,提高了实时部署的实用性。在RoboTwin2.0、Adroit和MetaWorld三个模拟基准测试中,PocketDP3以不到现有方法1%的参数量实现了最先进的性能,并加速了推理。真实世界的实验进一步证明了该方法在实际环境中的实用性和可迁移性。
🔬 方法详解
问题定义:现有基于3D视觉的扩散策略通常采用点云编码器和条件U-Net解码器。由于点云编码器输出的场景表示较为紧凑,庞大的U-Net解码器存在显著的参数冗余,导致模型体积过大,难以在计算资源有限的设备上部署,同时也增加了推理延迟。
核心思路:论文的核心思路是用一个轻量级的Diffusion Mixer (DiM) 替代传统的U-Net解码器。DiM基于MLP-Mixer架构,能够有效地融合时间和通道维度上的信息,从而在保证性能的同时,显著减少模型参数量。这种设计思路旨在解决现有方法中解码器参数冗余的问题,提高模型的效率和实用性。
技术框架:PocketDP3的整体框架包括一个点云编码器和一个Diffusion Mixer (DiM) 解码器。点云编码器负责将3D场景信息编码成紧凑的特征表示。DiM解码器接收该特征表示,并逐步生成动作序列。在训练过程中,模型学习从噪声中恢复动作序列。在推理过程中,模型通过迭代去噪过程生成最终的动作序列。
关键创新:PocketDP3的关键创新在于使用Diffusion Mixer (DiM) 替代了传统的U-Net解码器。DiM基于MLP-Mixer架构,具有参数量小、计算效率高的优点。与U-Net相比,DiM能够更有效地融合时间和通道维度上的信息,从而在保证性能的同时,显著减少模型参数量。此外,该方法无需额外的知识蒸馏技术,即可支持两步推理,进一步提高了推理效率。
关键设计:DiM解码器由多个MLP-Mixer块组成,每个MLP-Mixer块包含两个MLP层和一个残差连接。MLP层用于学习特征之间的非线性关系,残差连接用于缓解梯度消失问题。论文还探索了不同的MLP-Mixer块的配置,并选择了在实验中表现最佳的配置。此外,论文还采用了标准的扩散模型训练方法,包括高斯噪声添加和去噪过程。
🖼️ 关键图片


📊 实验亮点
PocketDP3在RoboTwin2.0、Adroit和MetaWorld三个模拟基准测试中取得了显著成果,参数量仅为现有方法的1%,但性能却达到了SOTA水平。此外,PocketDP3还支持两步推理,进一步提高了推理效率。真实世界的实验也验证了该方法在实际环境中的有效性和可迁移性。
🎯 应用场景
PocketDP3具有广泛的应用前景,尤其适用于需要在计算资源受限的设备上部署的机器人操作任务,例如移动机器人、无人机和可穿戴设备。该方法可以用于各种操作任务,包括物体抓取、放置、装配等。此外,PocketDP3还可以应用于虚拟现实和增强现实等领域,为用户提供更自然、更流畅的交互体验。
📄 摘要(原文)
Recently, 3D vision-based diffusion policies have shown strong capability in learning complex robotic manipulation skills. However, a common architectural mismatch exists in these models: a tiny yet efficient point-cloud encoder is often paired with a massive decoder. Given a compact scene representation, we argue that this may lead to substantial parameter waste in the decoder. Motivated by this observation, we propose PocketDP3, a pocket-scale 3D diffusion policy that replaces the heavy conditional U-Net decoder used in prior methods with a lightweight Diffusion Mixer (DiM) built on MLP-Mixer blocks. This architecture enables efficient fusion across temporal and channel dimensions, significantly reducing model size. Notably, without any additional consistency distillation techniques, our method supports two-step inference without sacrificing performance, improving practicality for real-time deployment. Across three simulation benchmarks--RoboTwin2.0, Adroit, and MetaWorld--PocketDP3 achieves state-of-the-art performance with fewer than 1% of the parameters of prior methods, while also accelerating inference. Real-world experiments further demonstrate the practicality and transferability of our method in real-world settings. Code will be released.