MoE-ACT: Improving Surgical Imitation Learning Policies through Supervised Mixture-of-Experts
作者: Lorenzo Mazza, Ariel Rodriguez, Rayan Younis, Martin Lelis, Ortrun Hellig, Chenpan Li, Sebastian Bodenstedt, Martin Wagner, Stefanie Speidel
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出MoE-ACT,通过监督式混合专家模型提升手术模仿学习策略。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手术机器人 模仿学习 混合专家模型 动作分块Transformer 鲁棒性 泛化能力 立体视觉 内窥镜
📋 核心要点
- 手术机器人模仿学习面临数据稀缺、工作空间受限以及对安全性和可预测性要求极高的挑战。
- 提出监督式混合专家(MoE)架构,增强动作分块Transformer (ACT)等策略,提升手术操作的鲁棒性和泛化性。
- 实验表明,MoE-ACT在肠道抓取和回缩任务中,显著优于VLA模型和标准ACT,并具备良好的零样本迁移能力。
📝 摘要(中文)
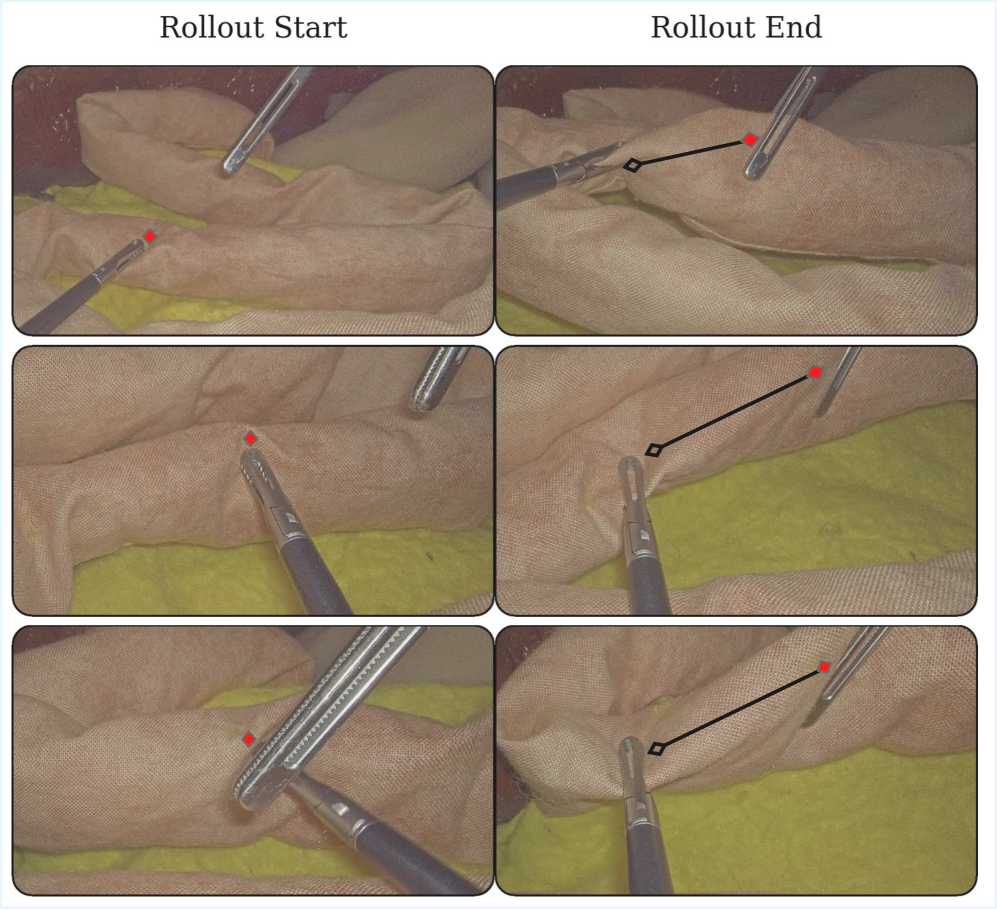
本文提出了一种监督式混合专家(MoE)架构,专为阶段性结构化手术操作任务设计,可作为任何自主策略的附加组件。与依赖多摄像头设置或数千次演示的手术机器人学习方法不同,本文证明了轻量级的动作解码器策略,如动作分块Transformer (ACT),在配备MoE架构后,仅使用立体内窥镜图像和少于150次的演示,即可学习复杂、长程的操作。本文在肠道抓取和回缩的协作手术任务中评估了该方法,其中机器人助手解释来自人类外科医生的视觉线索,对可变形组织执行有针对性的抓取,并执行持续的回缩。实验结果表明,通用视觉-语言-动作(VLA)模型即使在标准同分布条件下也无法完全掌握该任务。此外,虽然标准ACT在同分布情况下取得了一定的成功,但采用监督式MoE架构显著提高了其性能,在同分布情况下产生了更高的成功率,并在分布外场景中表现出卓越的鲁棒性,包括新的抓取位置、降低的光照和部分遮挡。值得注意的是,该方法可以推广到未见过的测试视角,并且无需额外训练即可零样本迁移到离体猪组织,为体内部署提供了有希望的途径。为此,本文展示了体内猪手术期间策略推出的初步定性结果。
🔬 方法详解
问题定义:手术机器人模仿学习旨在让机器人通过学习人类专家的操作来完成复杂的手术任务。然而,现有方法通常需要大量的训练数据,并且在面对新的环境或操作条件时,泛化能力较差。此外,手术环境的特殊性,如光照变化、组织变形和遮挡等,也给机器人感知和控制带来了挑战。
核心思路:本文的核心思路是利用混合专家模型(MoE)来提升模仿学习策略的性能和鲁棒性。MoE模型通过将任务分解为多个子任务,并为每个子任务分配一个专家模型,从而能够更好地适应不同的操作条件和环境变化。同时,通过监督学习的方式训练MoE模型,可以有效地利用有限的训练数据,并提高模型的泛化能力。
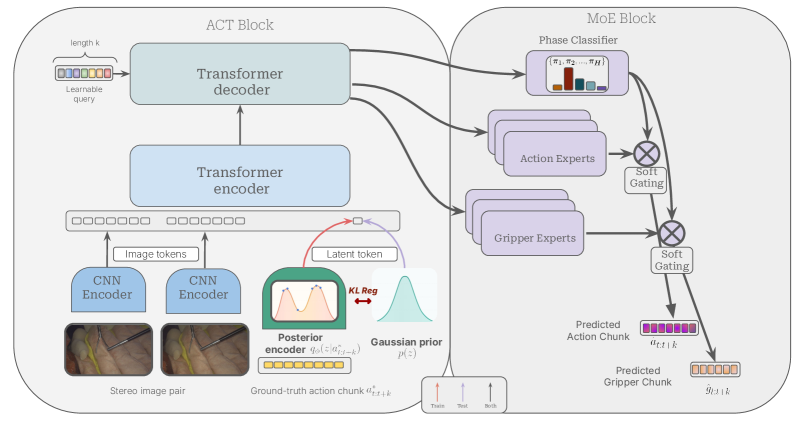
技术框架:MoE-ACT架构建立在动作分块Transformer (ACT)之上,ACT负责生成动作序列,MoE模块则负责根据当前状态选择合适的专家模型来执行动作。整体流程如下:首先,通过立体内窥镜获取手术场景的图像;然后,ACT根据图像生成动作序列;接着,MoE模块根据当前状态选择一个或多个专家模型;最后,选定的专家模型执行相应的动作。
关键创新:本文最重要的技术创新点是将监督式混合专家模型(MoE)引入到手术机器人模仿学习中。与传统的单一模型相比,MoE模型能够更好地适应不同的操作条件和环境变化,从而提高了策略的鲁棒性和泛化能力。此外,本文还提出了一种新的监督学习方法,用于训练MoE模型,该方法能够有效地利用有限的训练数据,并提高模型的性能。
关键设计:MoE模块的关键设计包括:专家模型的数量、专家模型的结构、门控网络的设计以及损失函数的设计。专家模型的数量决定了任务分解的粒度,专家模型的结构决定了每个专家模型的表达能力,门控网络的设计决定了如何选择合适的专家模型,损失函数的设计决定了如何训练MoE模型。具体而言,本文采用了具有少量参数的MLP作为专家模型,并使用softmax函数作为门控网络,损失函数包括模仿学习损失和正则化损失。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MoE-ACT在肠道抓取和回缩任务中取得了显著的性能提升。在同分布情况下,MoE-ACT的成功率明显高于标准ACT和VLA模型。更重要的是,MoE-ACT在分布外场景中表现出卓越的鲁棒性,例如在新的抓取位置、降低的光照和部分遮挡等情况下,仍然能够保持较高的成功率。此外,MoE-ACT还能够零样本迁移到离体猪组织,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于多种手术机器人辅助操作,例如缝合、切割、抓取等。通过提高手术机器人的自主性和智能化水平,可以减轻外科医生的负担,提高手术效率和安全性,并有望在远程手术和微创手术等领域发挥重要作用。此外,该方法还可以推广到其他机器人操作任务中,例如工业机器人和家庭服务机器人等。
📄 摘要(原文)
Imitation learning has achieved remarkable success in robotic manipulation, yet its application to surgical robotics remains challenging due to data scarcity, constrained workspaces, and the need for an exceptional level of safety and predictability. We present a supervised Mixture-of-Experts (MoE) architecture designed for phase-structured surgical manipulation tasks, which can be added on top of any autonomous policy. Unlike prior surgical robot learning approaches that rely on multi-camera setups or thousands of demonstrations, we show that a lightweight action decoder policy like Action Chunking Transformer (ACT) can learn complex, long-horizon manipulation from less than 150 demonstrations using solely stereo endoscopic images, when equipped with our architecture. We evaluate our approach on the collaborative surgical task of bowel grasping and retraction, where a robot assistant interprets visual cues from a human surgeon, executes targeted grasping on deformable tissue, and performs sustained retraction. We benchmark our method against state-of-the-art Vision-Language-Action (VLA) models and the standard ACT baseline. Our results show that generalist VLAs fail to acquire the task entirely, even under standard in-distribution conditions. Furthermore, while standard ACT achieves moderate success in-distribution, adopting a supervised MoE architecture significantly boosts its performance, yielding higher success rates in-distribution and demonstrating superior robustness in out-of-distribution scenarios, including novel grasp locations, reduced illumination, and partial occlusions. Notably, it generalizes to unseen testing viewpoints and also transfers zero-shot to ex vivo porcine tissue without additional training, offering a promising pathway toward in vivo deployment. To support this, we present qualitative preliminary results of policy roll-outs during in vivo porcine surgery.