Disentangling perception and reasoning for improving data efficiency in learning cloth manipulation without demonstrations
作者: Donatien Delehelle, Fei Chen, Darwin Caldwell
分类: cs.RO, cs.AI
发布日期: 2026-01-29
备注: 6 pages, 4 figures,
💡 一句话要点
解耦感知与推理,提升无示教cloth操作强化学习的数据效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: cloth操作 强化学习 解耦感知与推理 数据效率 sim-to-real迁移
📋 核心要点
- 现有cloth操作强化学习方法依赖于大型模型和长时间训练,计算成本高昂,阻碍了实际应用。
- 论文提出解耦感知和推理的模块化强化学习方法,旨在降低模型复杂度和训练时间,提高数据效率。
- 实验表明,该方法在SoftGym基准测试中,使用更小的模型实现了优于现有基线的性能,并成功迁移到真实世界。
📝 摘要(中文)
Cloth操作是日常生活中常见的任务,但对于机器人来说仍然是一个开放的挑战。开发cloth操作策略的难点在于高维状态空间、复杂的动力学以及织物易于自遮挡的特性。由于分析方法无法提供鲁棒和通用的操作策略,强化学习(RL)被认为是解决这些问题的一种有前途的方法。然而,为了解决大的状态空间和复杂的动力学问题,基于数据的方法通常依赖于大型模型和长时间的训练。由此产生的计算成本大大阻碍了这些方法的开发和应用。此外,由于鲁棒状态估计的挑战,服装操作策略通常采用以工作空间图像作为输入的端到端学习方法。虽然这种方法通过真实世界的微调,能够实现概念上直接的sim-to-real迁移,但它也通过在环境状态的高度有损表示上训练智能体而产生了巨大的计算成本。本文通过探索一种高效且模块化的cloth操作强化学习方法,对这种常见的设计选择提出了质疑。我们表明,通过仔细的设计选择,在模拟中学习时,可以显著减少模型大小和训练时间。此外,我们还展示了如何将由此产生的模拟训练模型迁移到现实世界。我们在SoftGym基准上评估了我们的方法,并在我们的任务上实现了相对于现有基线的显著性能改进,同时使用了明显更小的模型。
🔬 方法详解
问题定义:现有基于图像输入的端到端强化学习方法在cloth操作任务中,由于图像信息的高度冗余和噪声,导致学习效率低下,需要大量的训练数据和计算资源。此外,状态估计的挑战也使得模型难以泛化到真实世界。
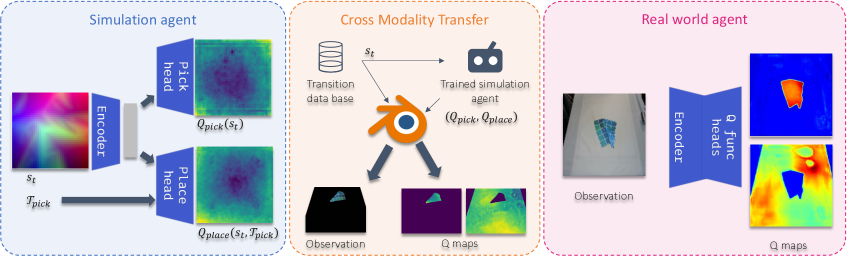
核心思路:论文的核心思路是将感知和推理过程解耦。感知模块负责从图像中提取关键的状态信息(例如关键点的坐标),推理模块则基于这些状态信息学习控制策略。通过这种解耦,可以减少输入数据的维度,降低模型的复杂度,并提高学习效率。
技术框架:整体框架包含两个主要模块:感知模块和推理模块。感知模块通常是一个卷积神经网络,用于从图像中提取cloth的关键点坐标。推理模块是一个强化学习智能体,它接收感知模块提取的关键点坐标作为输入,并输出控制指令。整个训练过程在模拟环境中进行,然后将训练好的模型迁移到真实世界。
关键创新:最重要的技术创新点在于解耦感知和推理过程,将复杂的图像输入转化为低维的关键点坐标输入,从而显著降低了强化学习智能体的学习难度和数据需求。这种解耦也使得模型更容易泛化到不同的cloth操作任务和真实世界环境。
关键设计:感知模块可以使用预训练的卷积神经网络,例如ResNet或VGG,并在cloth操作数据集上进行微调。推理模块可以使用各种强化学习算法,例如PPO或SAC。关键的设计在于如何选择合适的关键点以及如何设计感知模块的损失函数,以确保能够准确地提取关键点坐标。此外,奖励函数的设计也至关重要,需要引导智能体学习期望的cloth操作行为。
🖼️ 关键图片


📊 实验亮点
该方法在SoftGym基准测试中取得了显著的性能提升,超过了现有的基线方法。具体而言,在cloth平铺任务中,该方法使用更小的模型(参数量减少了约50%)实现了更高的成功率和更快的训练速度。此外,该方法还成功地将模拟环境中训练的模型迁移到了真实世界,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于服装制造、家政服务、医疗护理等领域,实现机器人对cloth的自动化操作,例如服装的整理、折叠、铺展,以及手术中纱布的定位和操作。通过降低数据需求和计算成本,该方法有望加速cloth操作机器人在实际场景中的部署和应用,提高生产效率和服务质量。
📄 摘要(原文)
Cloth manipulation is a ubiquitous task in everyday life, but it remains an open challenge for robotics. The difficulties in developing cloth manipulation policies are attributed to the high-dimensional state space, complex dynamics, and high propensity to self-occlusion exhibited by fabrics. As analytical methods have not been able to provide robust and general manipulation policies, reinforcement learning (RL) is considered a promising approach to these problems. However, to address the large state space and complex dynamics, data-based methods usually rely on large models and long training times. The resulting computational cost significantly hampers the development and adoption of these methods. Additionally, due to the challenge of robust state estimation, garment manipulation policies often adopt an end-to-end learning approach with workspace images as input. While this approach enables a conceptually straightforward sim-to-real transfer via real-world fine-tuning, it also incurs a significant computational cost by training agents on a highly lossy representation of the environment state. This paper questions this common design choice by exploring an efficient and modular approach to RL for cloth manipulation. We show that, through careful design choices, model size and training time can be significantly reduced when learning in simulation. Furthermore, we demonstrate how the resulting simulation-trained model can be transferred to the real world. We evaluate our approach on the SoftGym benchmark and achieve significant performance improvements over available baselines on our task, while using a substantially smaller model.