Training slow silicon neurons to control extremely fast robots with spiking reinforcement learning
作者: Irene Ambrosini, Ingo Blakowski, Dmitrii Zendrikov, Cristiano Capone, Luna Gava, Giacomo Indiveri, Chiara De Luca, Chiara Bartolozzi
分类: cs.RO, cs.AI, cs.ET
发布日期: 2026-01-29
💡 一句话要点
利用脉冲强化学习训练硅神经元,控制极高速机器人进行气垫球博弈
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 脉冲神经网络 神经形态计算 强化学习 机器人控制 实时系统
📋 核心要点
- 现有机器人控制方法难以在高速、动态变化的环境中进行实时决策,尤其是在计算资源受限的情况下。
- 论文提出一种基于脉冲神经网络的强化学习方法,利用神经形态硬件的并行性和低功耗特性,实现快速决策。
- 实验表明,该方法在气垫球博弈任务中,能够以极少的训练次数实现有效的冰球交互,验证了其在实时控制中的潜力。
📝 摘要(中文)
本文提出了一种基于混合信号模拟/数字神经形态处理器的紧凑型脉冲神经元网络,用于解决高速气垫球博弈中需要快速决策的挑战。通过硬件和学习算法的协同设计,该系统通过强化学习在极少的试验次数内成功地实现了与冰球的交互。该网络利用固定的随机连接来捕获任务的时间结构,并在读出层采用局部e-prop学习规则,以利用事件驱动的活动进行快速高效的学习。最终实现了一个包含计算机和神经形态芯片在环的实时学习系统,从而能够对用于机器人自主系统的脉冲神经网络进行实际训练。这项工作将受神经科学启发的硬件与现实世界的机器人控制联系起来,表明受大脑启发的方案可以应对快节奏的交互任务,同时支持智能机器中的持续学习。
🔬 方法详解
问题定义:论文旨在解决高速气垫球博弈中机器人实时控制的问题。现有方法通常依赖于复杂的计算模型和大量的训练数据,难以在资源受限的机器人平台上实现快速、高效的决策。此外,传统方法难以适应环境的快速变化和不确定性。
核心思路:论文的核心思路是利用脉冲神经网络(SNN)的事件驱动特性和神经形态硬件的并行计算能力,实现快速、低功耗的实时控制。通过强化学习训练SNN,使其能够根据当前状态快速做出决策,从而控制机器人与冰球进行交互。
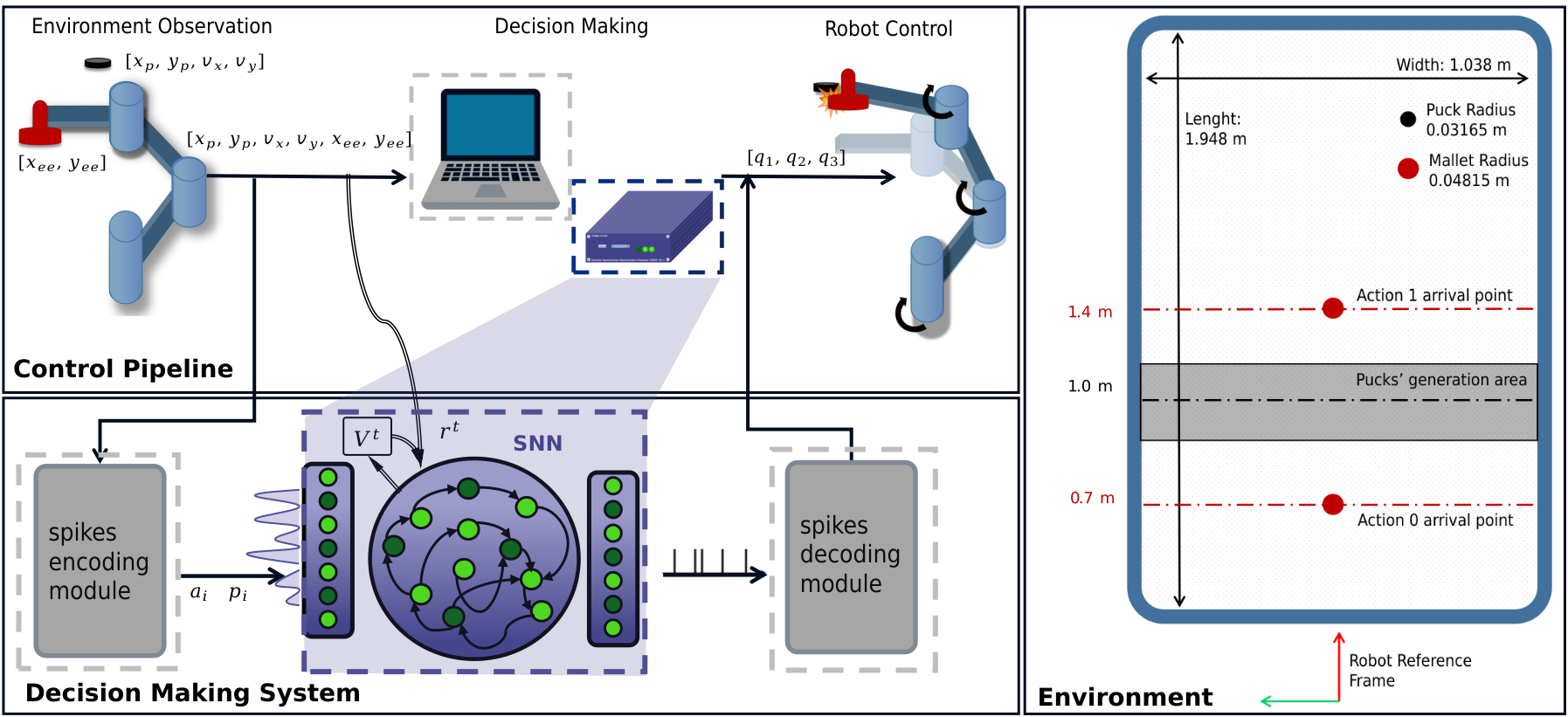
技术框架:整体框架包括:1) 神经形态处理器,用于运行SNN;2) 机器人平台,用于执行控制指令;3) 视觉系统,用于感知环境状态;4) 强化学习算法,用于训练SNN。SNN接收来自视觉系统的输入,并输出控制指令,控制机器人运动。强化学习算法根据机器人的表现,调整SNN的参数,使其能够更好地完成任务。
关键创新:论文的关键创新在于:1) 将SNN应用于高速机器人控制,利用其事件驱动特性实现快速决策;2) 采用局部e-prop学习规则,实现高效的在线学习;3) 通过硬件和学习算法的协同设计,充分发挥了神经形态硬件的优势。
关键设计:SNN采用固定的随机连接来捕获任务的时间结构。读出层采用局部e-prop学习规则,该规则基于事件驱动的活动进行快速有效的学习。强化学习算法使用奖励信号来指导SNN的训练。具体的参数设置和网络结构细节在论文中有详细描述,但具体数值未知。
🖼️ 关键图片
📊 实验亮点
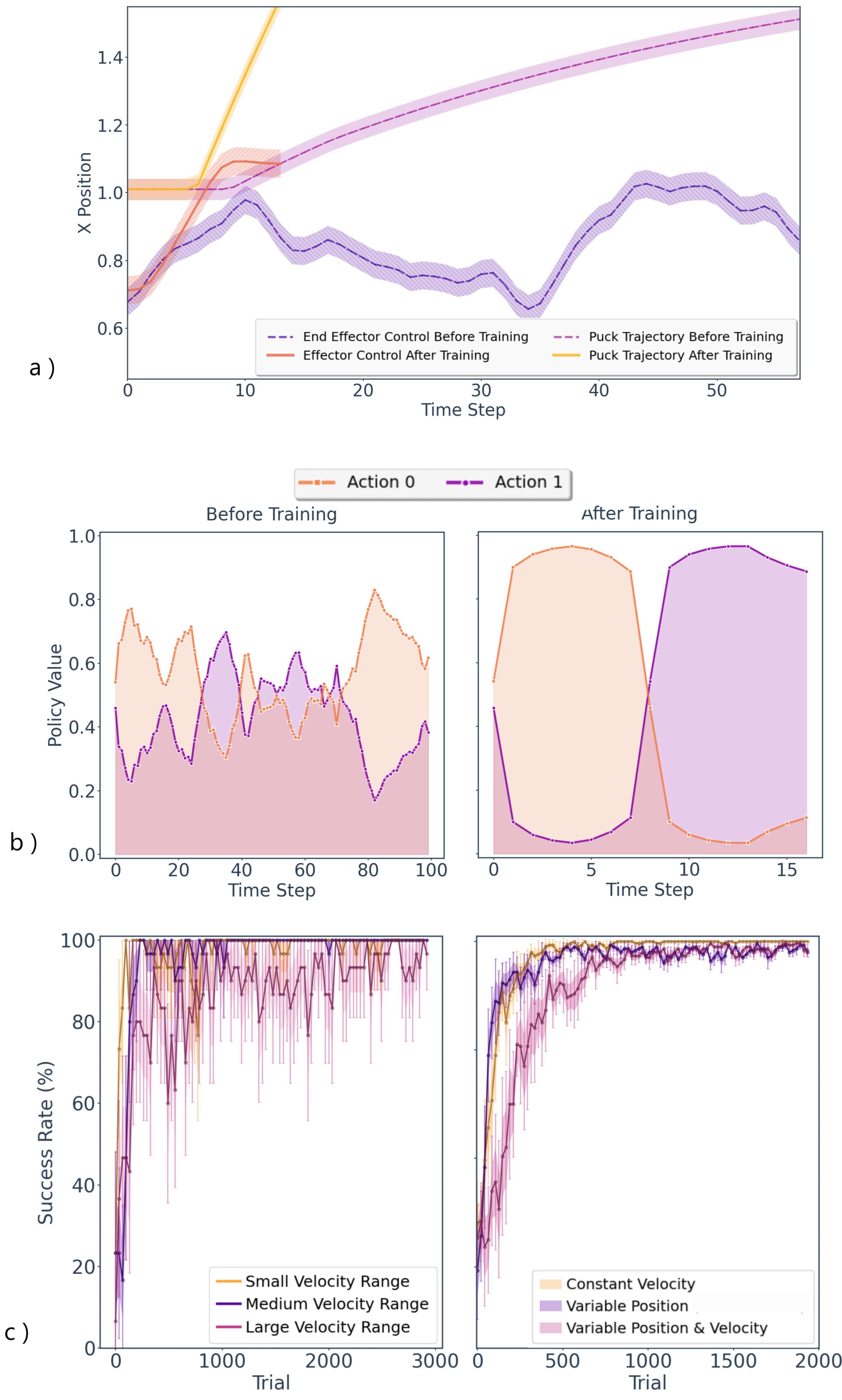
该研究在气垫球博弈任务中取得了显著成果。通过强化学习,该系统在极少的试验次数内成功地实现了与冰球的交互。与传统的控制方法相比,该方法具有更快的响应速度和更低的功耗。具体的性能数据和对比基线在论文中有详细描述,但具体数值未知。
🎯 应用场景
该研究成果可应用于需要快速决策和实时控制的机器人领域,例如无人驾驶、工业自动化、医疗机器人等。利用神经形态硬件和脉冲神经网络,可以实现低功耗、高效率的智能控制系统,从而提高机器人的自主性和适应性。此外,该研究也为神经形态计算在机器人领域的应用提供了新的思路。
📄 摘要(原文)
Air hockey demands split-second decisions at high puck velocities, a challenge we address with a compact network of spiking neurons running on a mixed-signal analog/digital neuromorphic processor. By co-designing hardware and learning algorithms, we train the system to achieve successful puck interactions through reinforcement learning in a remarkably small number of trials. The network leverages fixed random connectivity to capture the task's temporal structure and adopts a local e-prop learning rule in the readout layer to exploit event-driven activity for fast and efficient learning. The result is real-time learning with a setup comprising a computer and the neuromorphic chip in-the-loop, enabling practical training of spiking neural networks for robotic autonomous systems. This work bridges neuroscience-inspired hardware with real-world robotic control, showing that brain-inspired approaches can tackle fast-paced interaction tasks while supporting always-on learning in intelligent machines.