Towards Space-Based Environmentally-Adaptive Grasping
作者: Leonidas Askianakis, Aleksandr Artemov
分类: cs.RO
发布日期: 2026-01-29
💡 一句话要点
提出基于潜在空间的强化学习方法,解决空间环境下的自适应抓取问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 空间机器人 强化学习 潜在空间 多模态融合 机器人抓取
📋 核心要点
- 现有机器人操作方法在高维动作空间和稀疏奖励下泛化能力弱,难以适应空间环境等非结构化场景。
- 提出一种基于学习到的潜在空间的强化学习方法,融合多模态信息,实现更高效的策略学习和泛化。
- 实验表明,该方法在空间抓取任务中,比现有视觉基线方法收敛更快,且对新物体和环境具有更强的鲁棒性。
📝 摘要(中文)
在非结构化环境中进行机器人操作需要在各种条件下可靠执行,但许多最先进的系统仍然难以应对高维动作空间、稀疏奖励以及在精心设计的训练场景之外的缓慢泛化。本文以空间环境中的抓取为例研究这些局限性。我们直接在学习到的潜在空间中学习控制策略,该潜在空间将多种模态融合(语法化)为用于策略决策的结构化表示。基于GPU加速的物理模拟,我们实例化了一组单次操作任务,并在不到100万个环境步骤中,通过基于Soft Actor-Critic (SAC)的强化学习,在不断变化的抓取条件下,实现了超过95%的任务成功率。经验表明,在相同的开环单次条件下,这比具有代表性的最先进的视觉基线收敛速度更快。我们的分析表明,与标准基线相比,在潜在空间中进行显式推理可以提高样本效率,并提高对新物体和夹具几何形状、环境杂波和传感器配置的鲁棒性。我们确定了剩余的局限性,并概述了在极端空间条件下实现完全自适应和通用抓取的方向。
🔬 方法详解
问题定义:论文旨在解决空间环境下机器人抓取任务的自适应性问题。现有方法在高维动作空间、稀疏奖励以及环境变化时,泛化能力不足,难以应对空间环境的复杂性和不确定性。这些痛点限制了机器人自主完成空间任务的能力。
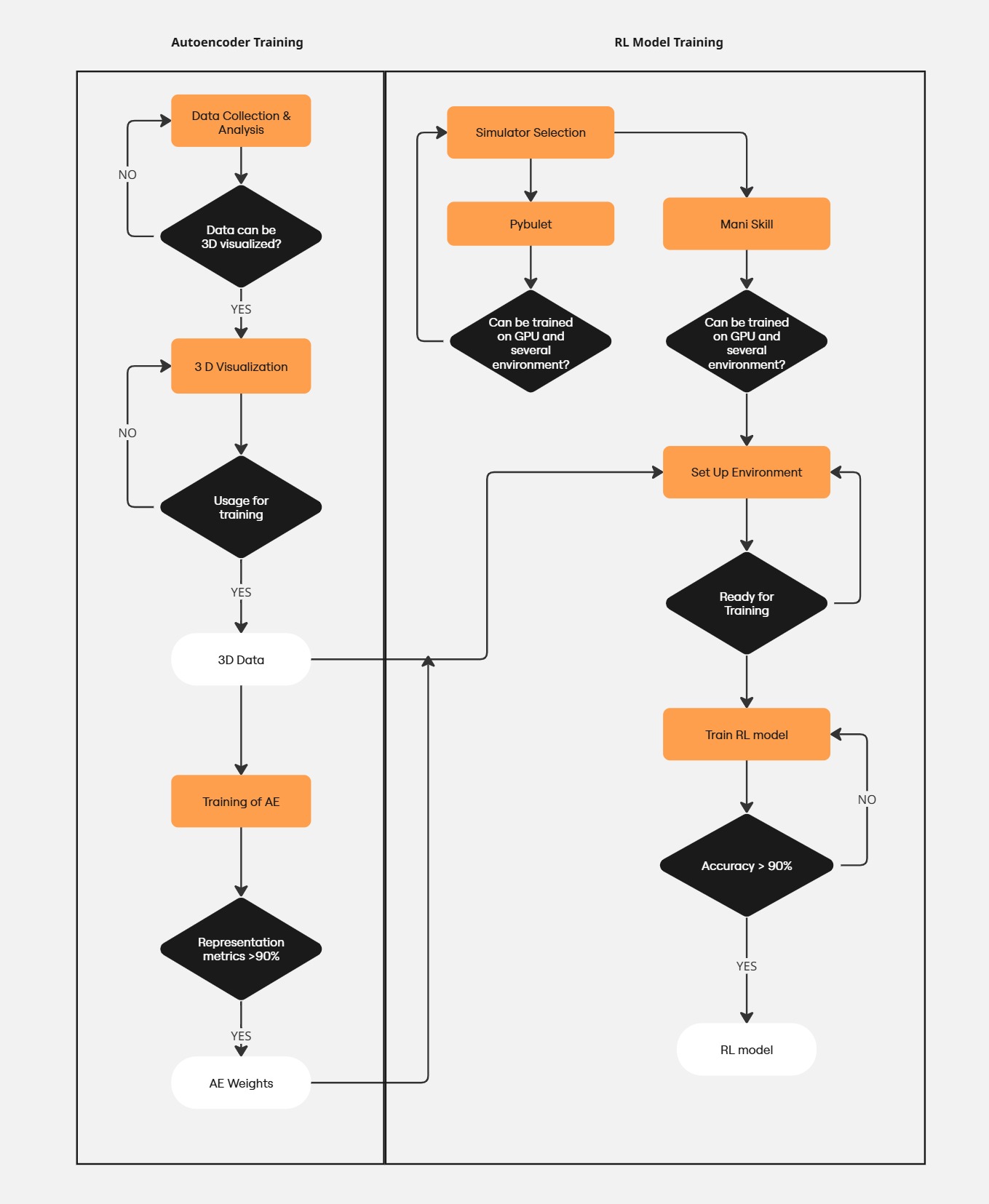
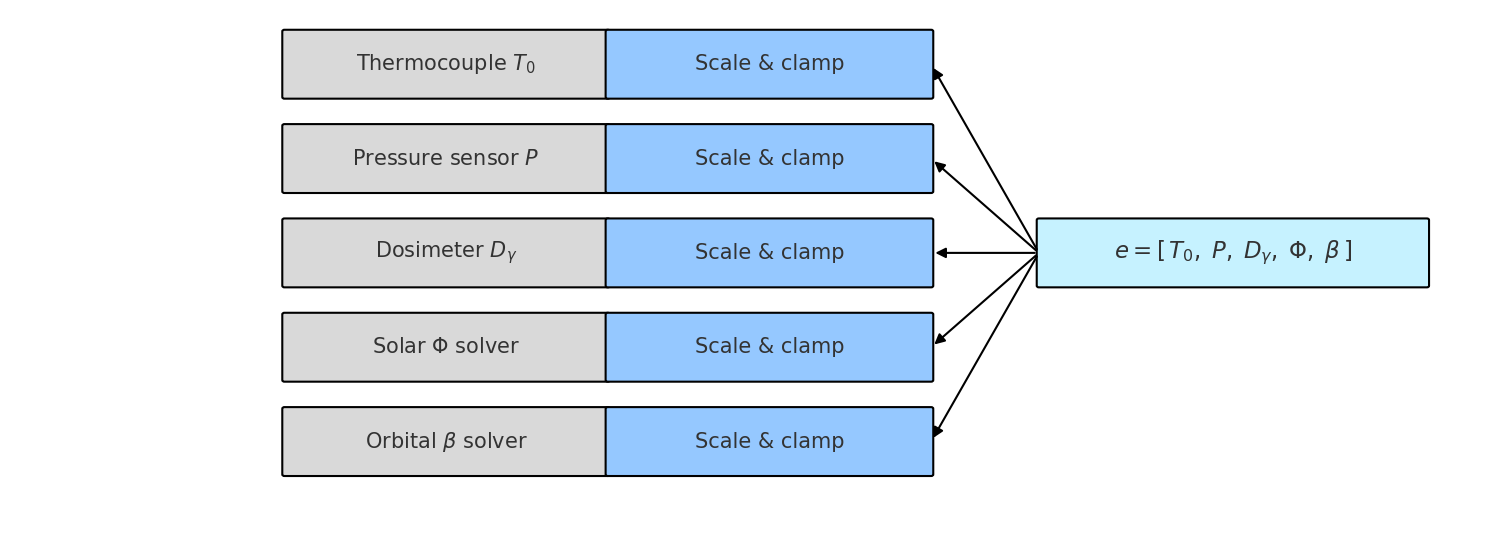
核心思路:论文的核心思路是将多模态信息(例如视觉、触觉等)融合到一个学习到的低维潜在空间中,并在该潜在空间中进行强化学习。通过在潜在空间中进行策略学习,可以降低动作空间的维度,提高样本效率,并增强对环境变化的鲁棒性。这种方法类似于将复杂的原始输入“语法化”为更简洁、更易于理解的表示。
技术框架:整体框架包含以下几个主要模块:1) 多模态数据采集与预处理;2) 潜在空间学习模块,用于将多模态数据编码到低维潜在空间;3) 基于潜在空间的强化学习模块,使用SAC算法学习抓取策略;4) 物理仿真环境,用于训练和评估策略。整个流程是端到端的,从原始传感器数据到最终的抓取动作。
关键创新:最重要的技术创新点在于将多模态信息融合到潜在空间中进行策略学习。与直接在原始高维空间中学习策略相比,这种方法可以显著提高样本效率和泛化能力。此外,论文还强调了在潜在空间中进行显式推理的重要性,这有助于提高对新物体和环境的鲁棒性。
关键设计:论文使用变分自编码器(VAE)或类似模型来学习潜在空间。SAC算法被用于在潜在空间中学习抓取策略。奖励函数的设计至关重要,需要平衡抓取成功率和动作的平滑性。此外,物理仿真环境的精度和效率也对训练效果有重要影响。具体参数设置和网络结构在论文中应该有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在空间抓取任务中取得了超过95%的成功率,并且比现有的视觉基线方法收敛速度更快。更重要的是,该方法对新物体和环境具有更强的鲁棒性,这表明其具有更好的泛化能力。这些结果验证了基于潜在空间的强化学习方法在复杂机器人操作任务中的有效性。
🎯 应用场景
该研究成果可应用于空间机器人、深海机器人等需要在复杂、非结构化环境中进行操作的领域。例如,可以用于空间站的维护、卫星的维修、太空垃圾的清理等任务。此外,该方法也可以推广到其他机器人操作任务,例如工业自动化、医疗机器人等。
📄 摘要(原文)
Robotic manipulation in unstructured environments requires reliable execution under diverse conditions, yet many state-of-the-art systems still struggle with high-dimensional action spaces, sparse rewards, and slow generalization beyond carefully curated training scenarios. We study these limitations through the example of grasping in space environments. We learn control policies directly in a learned latent manifold that fuses (grammarizes) multiple modalities into a structured representation for policy decision-making. Building on GPU-accelerated physics simulation, we instantiate a set of single-shot manipulation tasks and achieve over 95% task success with Soft Actor-Critic (SAC)-based reinforcement learning in less than 1M environment steps, under continuously varying grasping conditions from step 1. This empirically shows faster convergence than representative state-of-the-art visual baselines under the same open-loop single-shot conditions. Our analysis indicates that explicitly reasoning in latent space yields more sample-efficient learning and improved robustness to novel object and gripper geometries, environmental clutter, and sensor configurations compared to standard baselines. We identify remaining limitations and outline directions toward fully adaptive and generalizable grasping in the extreme conditions of space.