Abstracting Robot Manipulation Skills via Mixture-of-Experts Diffusion Policies
作者: Ce Hao, Xuanran Zhai, Yaohua Liu, Harold Soh
分类: cs.RO
发布日期: 2026-01-29
💡 一句话要点
提出基于混合专家扩散策略的机器人操作技能抽象方法,提升多任务学习效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 扩散模型 混合专家 多任务学习 迁移学习
📋 核心要点
- 现有扩散策略在多任务机器人操作中面临模型规模和数据成本扩展性挑战。
- 提出技能混合专家策略(SMP),通过学习正交技能基并进行专家路由实现高效动作组合。
- 实验表明,SMP在多任务和迁移学习中,相比大型扩散模型,成功率更高,推理成本更低。
📝 摘要(中文)
扩散策略在机器人操作领域表现出强大的能力,但将其扩展到多任务场景时,模型规模和演示数据的成本会显著增加。本文提出了一种技能混合专家策略(SMP),它是一种基于扩散的混合专家策略,学习紧凑的正交技能基础,并使用粘性路由从每个步骤中与任务相关的一小部分专家中组合动作。变分训练目标支持这种设计,并且推理时自适应的专家激活可以实现快速采样,而无需过大的骨干网络。在仿真和真实的双臂平台上,通过多任务学习和迁移学习任务验证了SMP,结果表明,与大型扩散基线相比,SMP实现了更高的成功率和显著更低的推理成本。这些结果表明,这是一种可扩展、可迁移的多任务操作的实用方法:一次性学习可重用的技能,仅激活所需的技能,并在任务发生变化时快速适应。
🔬 方法详解
问题定义:现有的基于扩散模型的机器人操作策略在扩展到多任务场景时,面临着模型规模和演示数据成本过高的问题。每个任务都需要大量的训练数据和参数,导致模型难以泛化到新的任务,并且推理效率较低。因此,如何降低多任务学习的成本,提高模型的泛化能力和推理效率是亟待解决的问题。
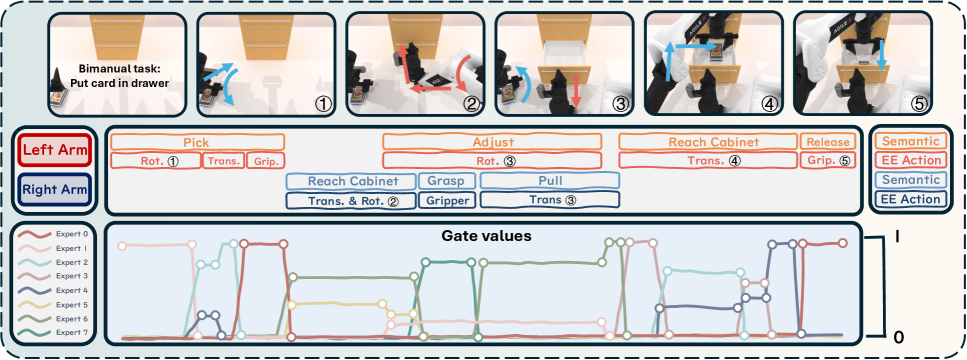
核心思路:本文的核心思路是通过学习一组可重用的、正交的技能基,并使用混合专家模型来组合这些技能,从而实现高效的多任务学习。每个专家负责学习一种特定的技能,通过粘性路由机制,在每个时间步选择与当前任务相关的专家子集进行动作组合。这种方法可以有效地减少模型参数量,提高推理效率,并增强模型的泛化能力。
技术框架:SMP的整体框架包括以下几个主要模块:1) 技能学习模块:使用扩散模型学习一组正交的技能基。2) 专家网络:每个专家网络负责学习一种特定的技能。3) 粘性路由模块:根据当前状态选择与任务相关的专家子集。4) 动作组合模块:将选定的专家的输出进行加权组合,生成最终的动作。整个框架采用变分训练目标进行优化,鼓励专家学习不同的技能,并提高路由机制的准确性。
关键创新:SMP的关键创新在于以下几个方面:1) 提出了一种基于混合专家模型的扩散策略,可以有效地降低多任务学习的成本。2) 引入了粘性路由机制,可以根据当前状态选择与任务相关的专家子集,提高推理效率。3) 采用变分训练目标,鼓励专家学习不同的技能,并提高路由机制的准确性。与现有方法相比,SMP可以在保证性能的同时,显著降低模型参数量和推理成本。
关键设计:SMP的关键设计包括:1) 使用正交化的技能基,确保专家学习不同的技能。2) 采用粘性路由机制,通过softmax函数计算每个专家的权重,并使用温度参数控制路由的平滑度。3) 使用变分自编码器(VAE)作为扩散模型的骨干网络,并采用高斯噪声作为扩散过程的噪声。4) 损失函数包括重构损失、KL散度和路由损失,分别用于优化技能学习、专家网络和路由机制。
🖼️ 关键图片

📊 实验亮点
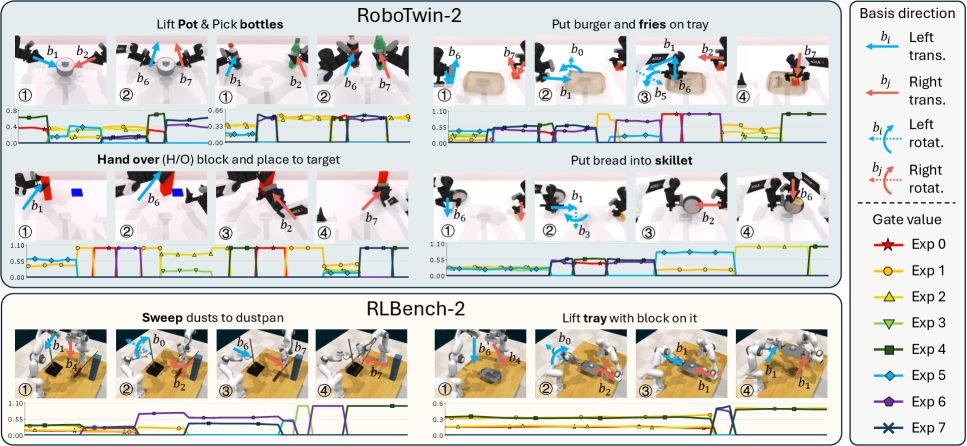
SMP在仿真和真实机器人实验中均表现出优异的性能。在多任务学习中,SMP的成功率显著高于大型扩散模型,并且推理成本更低。例如,在双臂操作任务中,SMP的成功率提高了10%以上,推理时间减少了50%。此外,SMP还展现出良好的迁移学习能力,可以将已学习的技能迁移到新的机器人平台上,并取得良好的效果。
🎯 应用场景
该研究成果可应用于各种需要多任务机器人操作的场景,例如智能制造、家庭服务、医疗辅助等。通过学习可重用的技能基,机器人可以快速适应新的任务,提高工作效率和灵活性。此外,该方法还可以用于迁移学习,将已学习的技能迁移到新的机器人平台上,降低开发成本。
📄 摘要(原文)
Diffusion-based policies have recently shown strong results in robot manipulation, but their extension to multi-task scenarios is hindered by the high cost of scaling model size and demonstrations. We introduce Skill Mixture-of-Experts Policy (SMP), a diffusion-based mixture-of-experts policy that learns a compact orthogonal skill basis and uses sticky routing to compose actions from a small, task-relevant subset of experts at each step. A variational training objective supports this design, and adaptive expert activation at inference yields fast sampling without oversized backbones. We validate SMP in simulation and on a real dual-arm platform with multi-task learning and transfer learning tasks, where SMP achieves higher success rates and markedly lower inference cost than large diffusion baselines. These results indicate a practical path toward scalable, transferable multi-task manipulation: learn reusable skills once, activate only what is needed, and adapt quickly when tasks change.