End-to-end example-based sim-to-real RL policy transfer based on neural stylisation with application to robotic cutting
作者: Jamie Hathaway, Alireza Rastegarpanah, Rustam Stolkin
分类: cs.RO
发布日期: 2026-01-28
备注: 14 pages, 9 figures. Submitted to Nature Scientific Reports
💡 一句话要点
提出基于神经风格化的端到端示例强化学习策略迁移方法,用于机器人切割任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 领域自适应 神经风格迁移 机器人切割 变分自编码器
📋 核心要点
- 现有强化学习方法依赖大量仿真数据,但仿真与现实的差距限制了其在真实机器人任务中的应用。
- 该论文提出一种基于神经风格迁移的强化学习策略迁移方法,利用真实世界数据合成训练数据,缩小领域差距。
- 实验表明,该方法在机器人切割任务中,相比基线方法,能以更少真实数据实现更快的任务完成和更稳定的行为。
📝 摘要(中文)
强化学习已成功应用于复杂、不确定环境中的机器人控制问题,但对大量数据的依赖(通常来自仿真环境)限制了其在现实世界的部署,这是由于仿真系统和物理系统之间的领域差距,以及有限的真实世界样本可用性。本文提出了一种新颖的强化学习策略从仿真到现实的迁移方法,该方法基于对神经风格迁移的重新解释,从不成对的、未标记的真实世界数据集中合成新的训练数据。我们采用变分自编码器来联合学习风格迁移的自监督特征表示,并生成弱配对的源-目标轨迹,以提高合成轨迹的物理真实感。我们通过机器人切割未知材料的案例研究,展示了我们方法的应用。与包括我们之前的工作CycleGAN和基于条件变分自编码器的时间序列翻译等基线方法相比,我们的方法以最少的真实世界数据实现了更短的任务完成时间和更好的行为稳定性。我们的框架展示了对几何和材料变化的鲁棒性,并突出了在无法获得真实世界奖励信息的具有挑战性的接触任务中进行策略适应的可行性。
🔬 方法详解
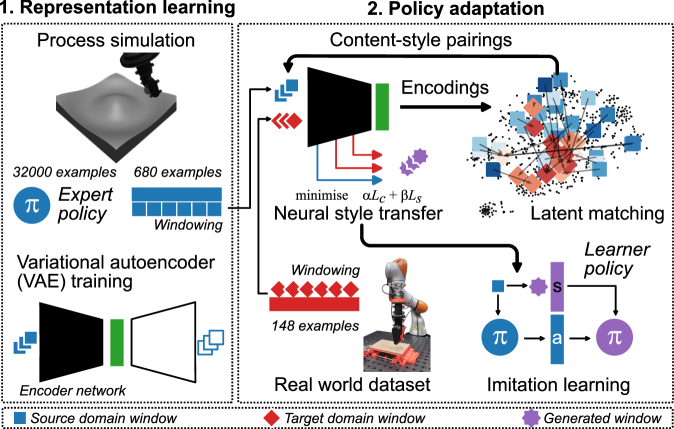
问题定义:现有强化学习算法在机器人控制领域取得了显著进展,但其对大量训练数据的需求限制了其在真实世界的应用。仿真环境虽然可以提供大量数据,但仿真与现实环境存在差异(即领域差距),导致在仿真环境中训练的策略难以直接迁移到真实机器人上。尤其是在机器人切割等接触任务中,精确建模物理交互非常困难,领域差距问题更为突出。
核心思路:本文的核心思路是利用神经风格迁移技术,将真实世界的数据“风格化”到仿真数据中,从而生成更接近真实环境的训练数据,缩小领域差距。通过这种方式,可以利用仿真环境进行策略训练,然后将训练好的策略迁移到真实机器人上,而无需大量的真实世界数据。
技术框架:该方法主要包含以下几个模块:1) 数据收集:从仿真环境和真实世界分别收集轨迹数据。真实世界的数据不需要标签,只需要包含状态信息即可。2) 特征提取与风格迁移:使用变分自编码器(VAE)学习仿真数据和真实数据的特征表示。VAE被用于学习一个共享的潜在空间,使得仿真数据和真实数据可以在这个空间中进行风格迁移。3) 策略训练:在风格迁移后的仿真数据上训练强化学习策略。4) 策略部署:将训练好的策略部署到真实机器人上进行切割任务。
关键创新:该方法的主要创新在于将神经风格迁移技术应用于强化学习的领域自适应问题。与传统的领域自适应方法不同,该方法不需要显式地建模领域之间的映射关系,而是通过学习数据的特征表示,隐式地实现领域自适应。此外,使用VAE学习特征表示可以更好地捕捉数据的内在结构,从而提高风格迁移的效果。
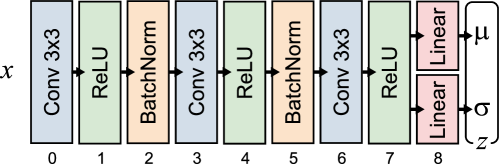
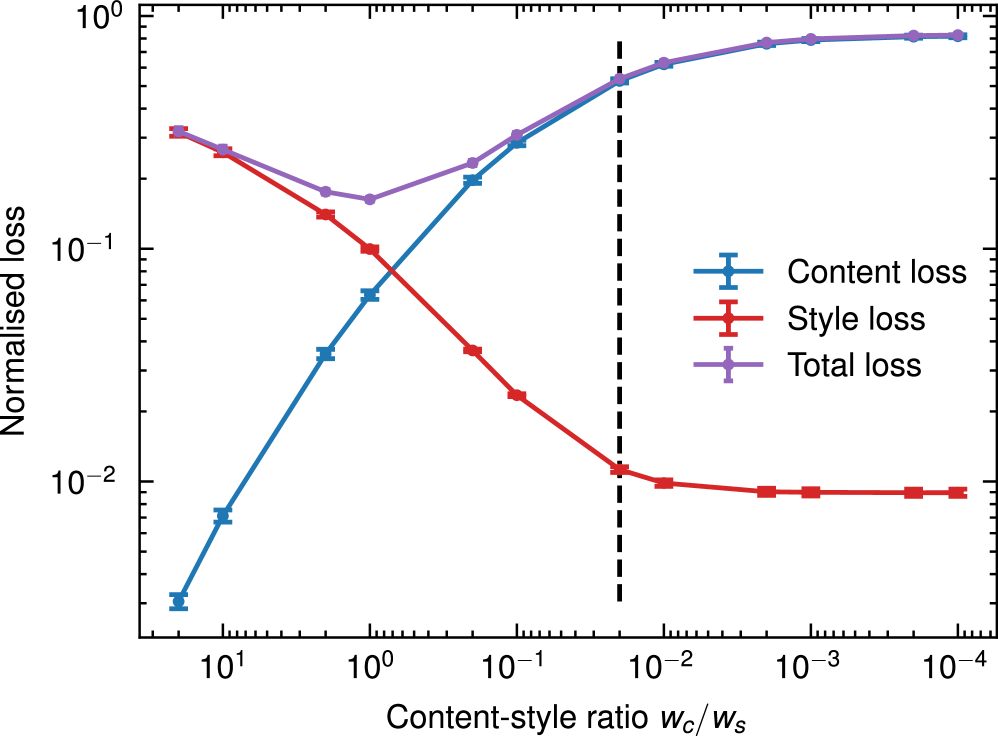
关键设计:在VAE的设计上,使用了自监督学习的方式,即通过重构输入数据来训练VAE。损失函数包括重构损失和KL散度损失。重构损失用于保证VAE能够准确地重构输入数据,KL散度损失用于约束潜在空间的分布,使其接近标准正态分布。在策略训练方面,可以使用任何off-policy的强化学习算法,例如DDPG或SAC。关键在于如何设计奖励函数,使其能够反映切割任务的完成情况。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在机器人切割任务中,相比于CycleGAN和基于条件变分自编码器的时间序列翻译等基线方法,能够以更少的真实世界数据实现更短的任务完成时间和更好的行为稳定性。具体而言,该方法在任务完成时间上取得了显著提升,并且在切割过程中表现出更强的鲁棒性,能够适应几何和材料的变化。
🎯 应用场景
该研究成果可广泛应用于机器人自动化领域,尤其是在需要处理复杂物理交互、且难以获取大量真实数据的场景中,例如机器人切割、打磨、装配等。通过仿真训练和风格迁移,可以降低机器人部署成本,提高其在复杂环境中的适应性。未来,该方法有望扩展到更多机器人任务,加速机器人智能化进程。
📄 摘要(原文)
Whereas reinforcement learning has been applied with success to a range of robotic control problems in complex, uncertain environments, reliance on extensive data - typically sourced from simulation environments - limits real-world deployment due to the domain gap between simulated and physical systems, coupled with limited real-world sample availability. We propose a novel method for sim-to-real transfer of reinforcement learning policies, based on a reinterpretation of neural style transfer from image processing to synthesise novel training data from unpaired unlabelled real world datasets. We employ a variational autoencoder to jointly learn self-supervised feature representations for style transfer and generate weakly paired source-target trajectories to improve physical realism of synthesised trajectories. We demonstrate the application of our approach based on the case study of robot cutting of unknown materials. Compared to baseline methods, including our previous work, CycleGAN, and conditional variational autoencoder-based time series translation, our approach achieves improved task completion time and behavioural stability with minimal real-world data. Our framework demonstrates robustness to geometric and material variation, and highlights the feasibility of policy adaptation in challenging contact-rich tasks where real-world reward information is unavailable.