One Step Is Enough: Dispersive MeanFlow Policy Optimization
作者: Guowei Zou, Haitao Wang, Hejun Wu, Yukun Qian, Yuhang Wang, Weibing Li
分类: cs.RO
发布日期: 2026-01-28
备注: Code and project page: https://guowei-zou.github.io/dmpo-page/
💡 一句话要点
提出Dispersive MeanFlow Policy Optimization,实现机器人实时控制的单步策略生成。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人控制 强化学习 策略优化 实时控制 单步生成 MeanFlow 分散正则化
📋 核心要点
- 现有基于扩散和流匹配的生成策略需要多步采样,限制了其在时间敏感场景中的部署。
- DMPO通过MeanFlow实现单步推理,分散正则化防止表征崩溃,并使用强化学习微调超越专家演示。
- 实验表明,DMPO在多个基准测试中表现优异,推理速度提升5-20倍,并在真实机器人上验证了其可行性。
📝 摘要(中文)
本文提出Dispersive MeanFlow Policy Optimization (DMPO),一个统一的框架,通过三个关键组件实现真正的单步生成:MeanFlow用于数学推导的单步推理,无需知识蒸馏;分散正则化防止表征崩溃;以及强化学习(RL)微调以超越专家演示。在RoboMimic操作和OpenAI Gym运动基准测试中,实验表明DMPO与多步基线相比具有竞争性或更优越的性能。凭借轻量级的模型架构和协同工作的三大算法组件,DMPO超过了实时控制要求(>120Hz),并在高性能GPU上实现了5-20倍的推理加速,达到数百赫兹。在Franka-Emika-Panda机器人上的物理部署验证了其在现实世界中的适用性。
🔬 方法详解
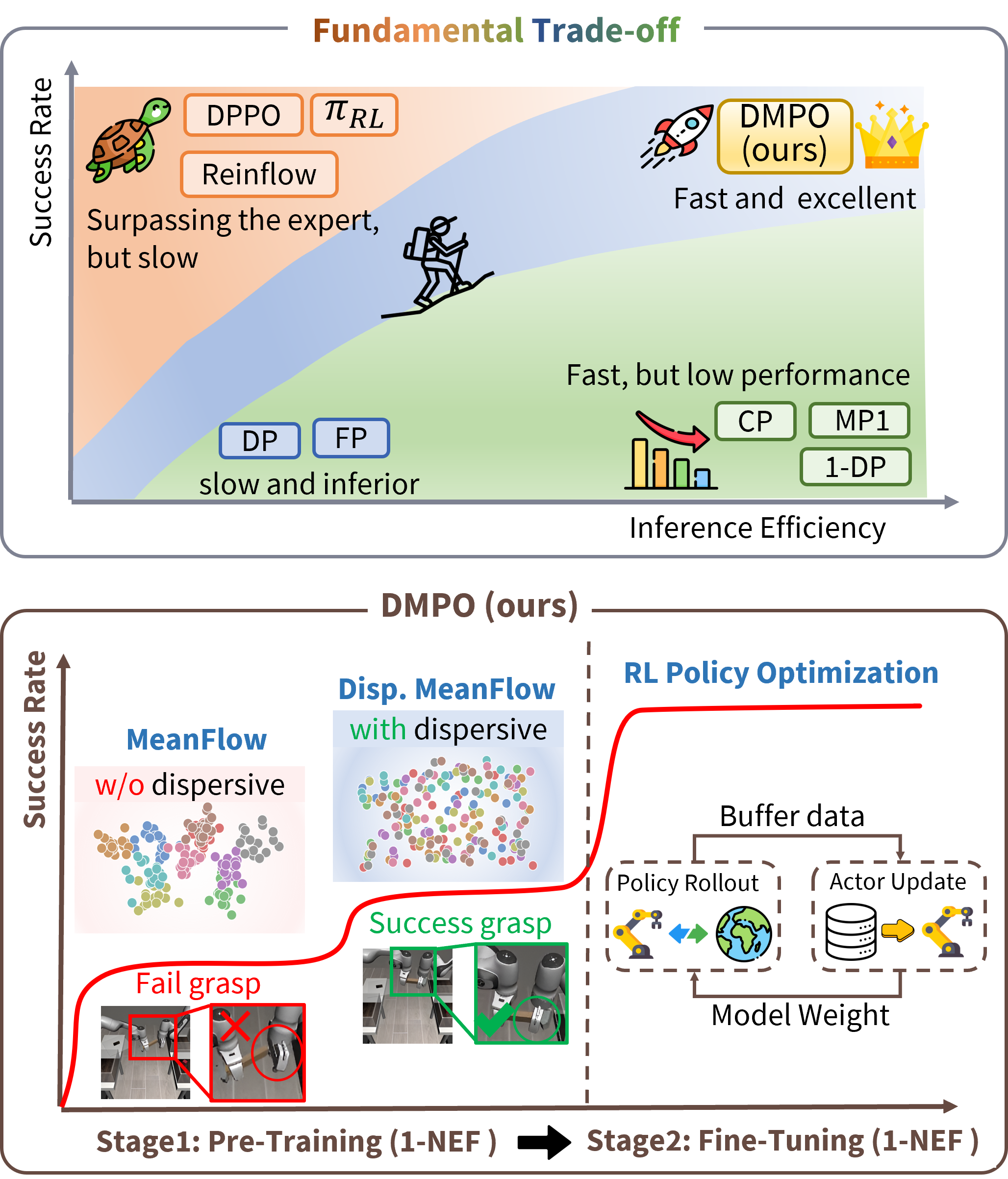
问题定义:现有基于扩散模型或流匹配的生成策略在机器人实时控制中面临挑战,因为它们需要多步采样才能生成动作。这导致推理速度慢,无法满足实时性要求高的应用场景。因此,需要一种能够单步生成动作的策略,以提高控制频率。
核心思路:DMPO的核心思路是利用MeanFlow,通过数学推导实现单步推理,从而避免了多步采样带来的延迟。同时,引入分散正则化来防止表征崩溃,并使用强化学习进行微调,以进一步提升策略的性能,使其超越专家演示。
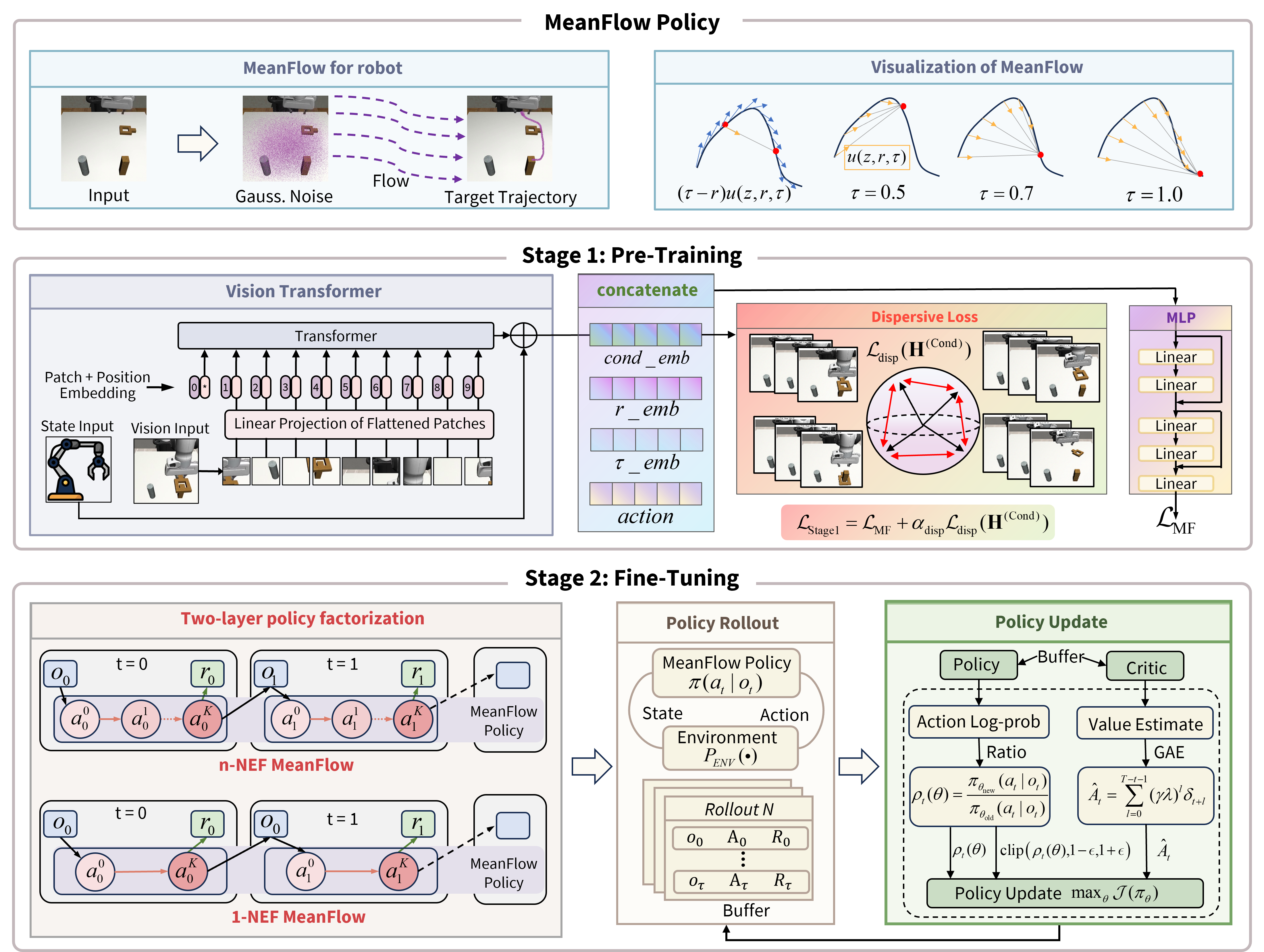
技术框架:DMPO的整体框架包含三个主要组成部分:MeanFlow模块,用于单步动作生成;分散正则化模块,用于防止表征坍塌;以及强化学习微调模块,用于提升策略性能。首先,MeanFlow基于专家数据进行训练,然后应用分散正则化来改善表征空间,最后使用强化学习算法对策略进行微调。
关键创新:DMPO的关键创新在于将MeanFlow应用于策略优化,并结合分散正则化和强化学习微调,实现了真正意义上的单步策略生成。与传统的基于扩散或流匹配的方法相比,DMPO无需多步采样,从而显著提高了推理速度。此外,分散正则化和强化学习微调进一步提升了策略的性能和鲁棒性。
关键设计:MeanFlow模块采用特定的网络结构来建模动作分布,具体结构未知。分散正则化通过添加额外的损失项来鼓励表征的多样性,损失函数的具体形式未知。强化学习微调使用PPO等算法,奖励函数的设计需要根据具体的任务进行调整。模型架构轻量化,具体参数未知。
🖼️ 关键图片
📊 实验亮点
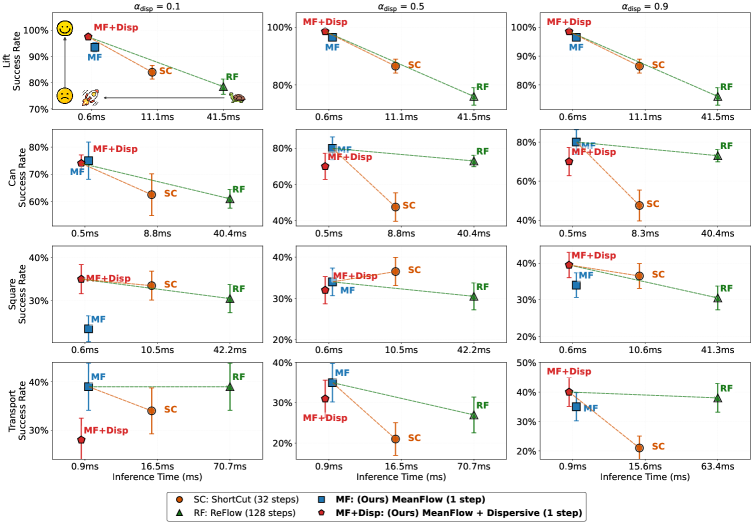
DMPO在RoboMimic操作和OpenAI Gym运动基准测试中表现出优异的性能,与多步基线相比具有竞争性或更优越的性能。最重要的是,DMPO实现了5-20倍的推理加速,在高性能GPU上达到数百赫兹,超过了实时控制的要求(>120Hz)。在Franka-Emika-Panda机器人上的物理部署验证了其在现实世界中的可行性。
🎯 应用场景
DMPO在机器人实时控制领域具有广泛的应用前景,例如高速运动控制、人机协作、自动驾驶等。其单步生成策略的特性使其能够满足对实时性要求极高的场景,从而提高机器人的响应速度和控制精度。此外,DMPO还可以应用于游戏AI、金融交易等需要快速决策的领域。
📄 摘要(原文)
Real-time robotic control demands fast action generation. However, existing generative policies based on diffusion and flow matching require multi-step sampling, fundamentally limiting deployment in time-critical scenarios. We propose Dispersive MeanFlow Policy Optimization (DMPO), a unified framework that enables true one-step generation through three key components: MeanFlow for mathematically-derived single-step inference without knowledge distillation, dispersive regularization to prevent representation collapse, and reinforcement learning (RL) fine-tuning to surpass expert demonstrations. Experiments across RoboMimic manipulation and OpenAI Gym locomotion benchmarks demonstrate competitive or superior performance compared to multi-step baselines. With our lightweight model architecture and the three key algorithmic components working in synergy, DMPO exceeds real-time control requirements (>120Hz) with 5-20x inference speedup, reaching hundreds of Hertz on high-performance GPUs. Physical deployment on a Franka-Emika-Panda robot validates real-world applicability.