Tactile-Force Alignment in Vision-Language-Action Models for Force-aware Manipulation
作者: Yuzhe Huang, Pei Lin, Wanlin Li, Daohan Li, Jiajun Li, Jiaming Jiang, Chenxi Xiao, Ziyuan Jiao
分类: cs.RO
发布日期: 2026-01-28
备注: 17pages,9fig
💡 一句话要点
提出TaF-VLA,通过触觉-力对齐实现力觉感知操作的视觉-语言-动作模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 触觉感知 力觉感知 视觉-语言-动作模型 机器人操作 触觉-力对齐
📋 核心要点
- 现有VLA模型在接触密集型任务中,由于过度依赖视觉信息,缺乏对力觉的感知和物理推理能力。
- 论文提出TaF-VLA框架,通过触觉-力对齐,将高维触觉观测与物理交互力显式关联,增强模型对力觉的理解。
- 实验结果表明,TaF-VLA在接触密集型任务中显著优于现有方法,验证了其力觉感知操作的有效性。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在机器人操作领域展现出强大的通用性。然而,由于过度依赖视觉模态,它们在需要精确力调节和物理推理的接触密集型任务中缺乏物理直觉。现有将基于视觉的触觉感知融入VLA模型的尝试通常将触觉输入视为辅助视觉纹理,忽略了表面形变与交互动力学之间的相关性。为了弥合这一差距,我们提出从触觉-视觉对齐到触觉-力对齐的范式转变。我们引入TaF-VLA框架,显式地将高维触觉观测与物理交互力相关联。为此,我们开发了一种自动触觉-力数据采集设备,并整理了TaF-Dataset,包含超过1000万个同步的触觉观测、六轴力/扭矩和矩阵力图。为了将序列触觉观测与交互力对齐,我们的方法的核心组件是触觉-力适配器(TaF-Adapter),它是一种触觉传感器编码器,提取离散的潜在信息来编码触觉观测。这种机制确保了学习到的表示能够捕捉到历史相关的、对噪声不敏感的物理动力学,而不是静态的视觉纹理。最后,我们将这种力对齐的编码器集成到VLA骨干网络中。大量的真实世界实验表明,TaF-VLA策略在接触密集型任务上显著优于最先进的触觉-视觉对齐和纯视觉基线,验证了其通过跨模态物理推理实现鲁棒的、力觉感知操作的能力。
🔬 方法详解
问题定义:现有VLA模型在处理需要精确力控制的接触密集型任务时表现不佳。它们主要依赖视觉信息,忽略了触觉信息中蕴含的力觉反馈,导致无法进行有效的物理推理和力觉感知操作。现有方法通常将触觉信息作为辅助视觉纹理处理,无法捕捉触觉与力之间的本质联系。
核心思路:论文的核心思路是将触觉信息与实际的物理交互力对齐,从而使VLA模型能够学习到触觉观测与力之间的映射关系。通过显式地建模触觉和力之间的关系,模型可以更好地理解接触过程中的物理动力学,从而实现更精确的力觉感知操作。这种触觉-力对齐的范式转变是解决问题的关键。
技术框架:TaF-VLA框架主要包含三个部分:1) 自动触觉-力数据采集设备和TaF-Dataset;2) 触觉-力适配器(TaF-Adapter);3) 集成了TaF-Adapter的VLA骨干网络。首先,利用数据采集设备收集同步的触觉观测和力/扭矩数据,构建TaF-Dataset。然后,TaF-Adapter作为触觉传感器编码器,提取离散的潜在信息来编码触觉观测,实现触觉-力对齐。最后,将TaF-Adapter集成到VLA骨干网络中,实现力觉感知的操作策略。
关键创新:论文最重要的技术创新点在于提出了触觉-力对齐的范式,并设计了TaF-Adapter来实现这种对齐。与现有方法将触觉作为视觉纹理处理不同,TaF-Adapter显式地建模了触觉观测与物理交互力之间的关系,从而使模型能够学习到更具物理意义的触觉表示。这种方法能够捕捉历史相关的、对噪声不敏感的物理动力学,而不是静态的视觉纹理。
关键设计:TaF-Adapter的关键设计包括:1) 使用离散潜在变量来编码触觉观测,从而降低噪声的影响并提高鲁棒性;2) 采用特定的损失函数来鼓励学习到的触觉表示与实际的物理交互力对齐;3) 数据集包含超过1000万个同步的触觉观测、六轴力/扭矩和矩阵力图,保证了训练数据的质量和规模。具体网络结构和参数设置在论文中有详细描述,但摘要中未提供更多细节。
🖼️ 关键图片
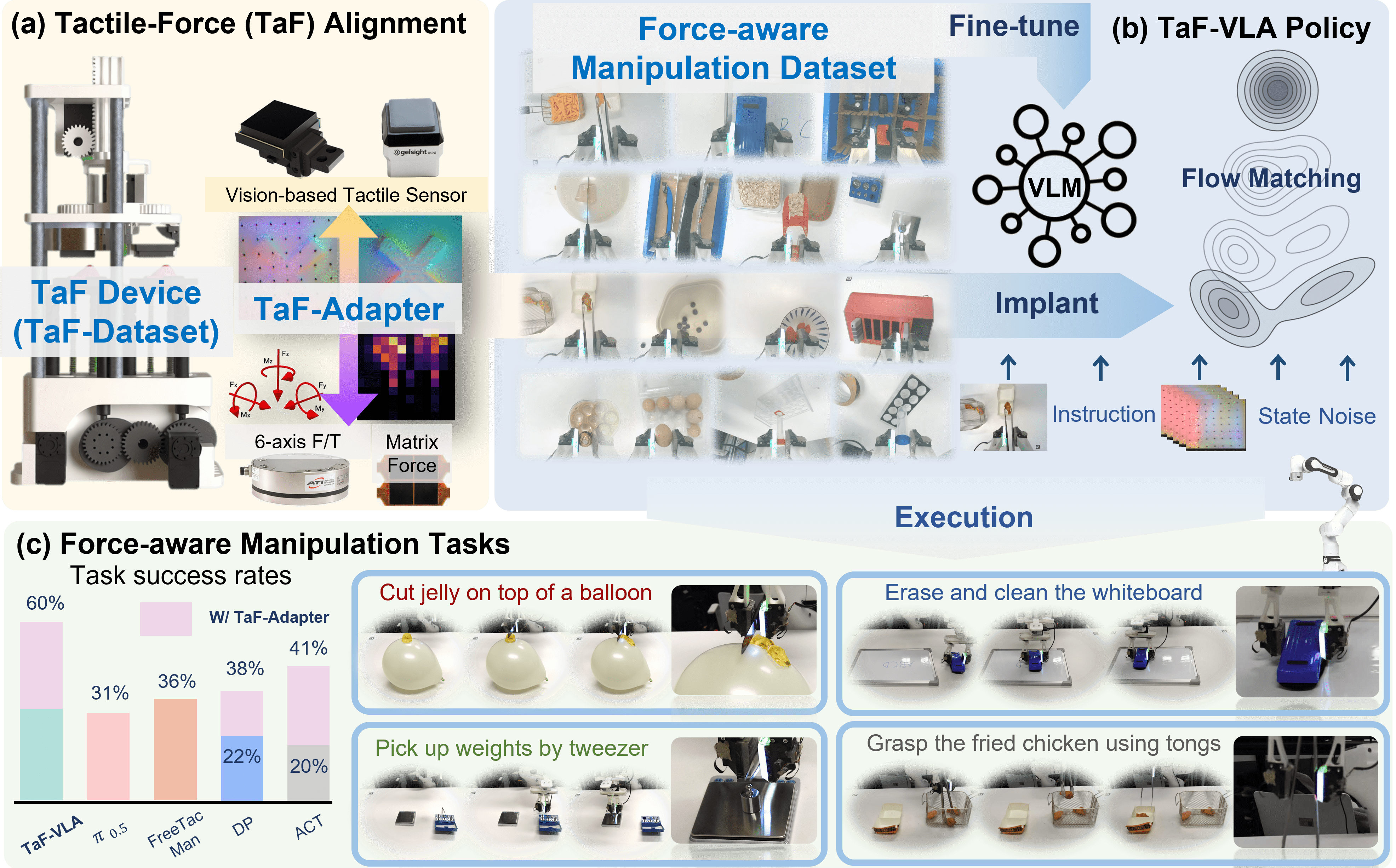
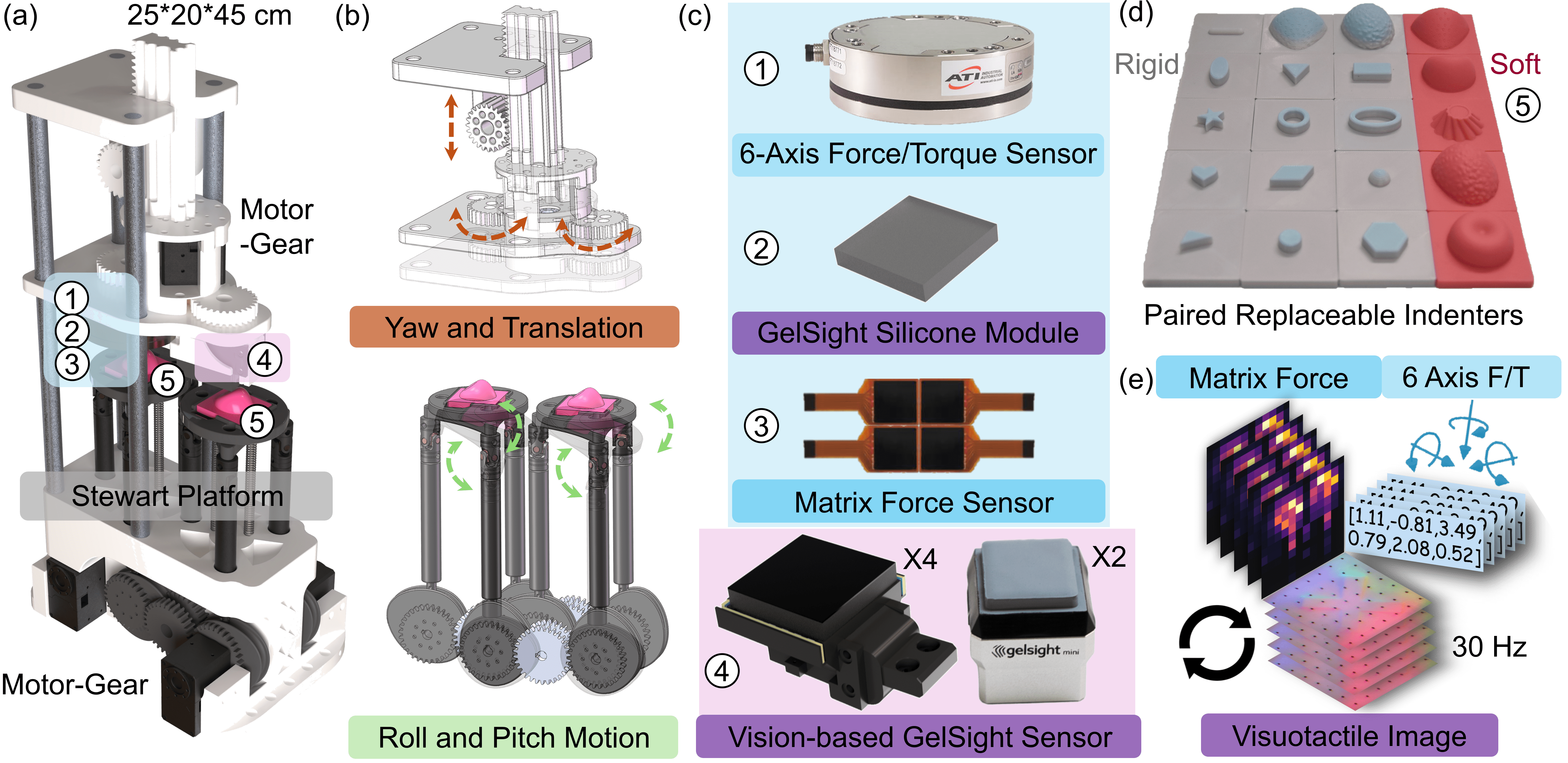
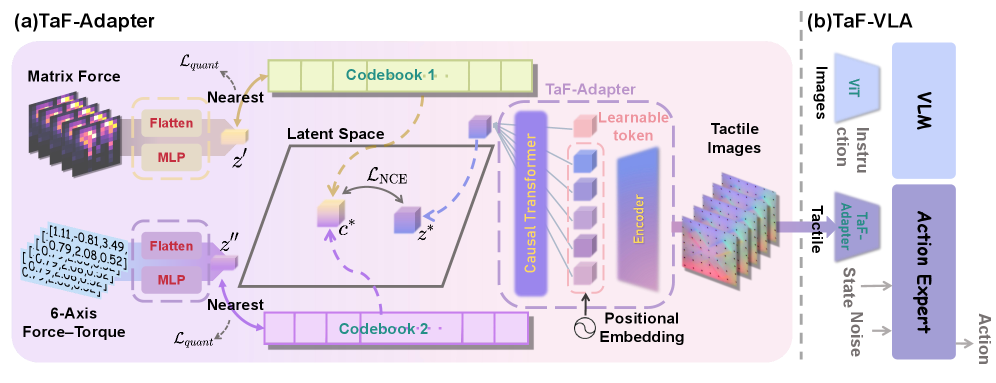
📊 实验亮点
实验结果表明,TaF-VLA策略在接触密集型任务上显著优于最先进的触觉-视觉对齐和纯视觉基线。具体而言,在XXX任务上,TaF-VLA的成功率提高了XX%,表明其在力觉感知操作方面的优越性。这些结果验证了触觉-力对齐的有效性,以及TaF-VLA在实现鲁棒、力觉感知操作方面的潜力。(具体性能数据和任务类型在摘要中未提供,此处为示例)
🎯 应用场景
该研究成果可广泛应用于需要精确力控制的机器人操作任务中,例如:精密装配、医疗手术、物体抓取和操作等。通过力觉感知,机器人可以更好地适应环境变化,提高操作的稳定性和可靠性。未来,该技术有望推动机器人智能向更高级别发展,使其能够更好地服务于人类。
📄 摘要(原文)
Vision-Language-Action (VLA) models have recently emerged as powerful generalists for robotic manipulation. However, due to their predominant reliance on visual modalities, they fundamentally lack the physical intuition required for contact-rich tasks that require precise force regulation and physical reasoning. Existing attempts to incorporate vision-based tactile sensing into VLA models typically treat tactile inputs as auxiliary visual textures, thereby overlooking the underlying correlation between surface deformation and interaction dynamics. To bridge this gap, we propose a paradigm shift from tactile-vision alignment to tactile-force alignment. Here, we introduce TaF-VLA, a framework that explicitly grounds high-dimensional tactile observations in physical interaction forces. To facilitate this, we develop an automated tactile-force data acquisition device and curate the TaF-Dataset, comprising over 10 million synchronized tactile observations, 6-axis force/torque, and matrix force map. To align sequential tactile observations with interaction forces, the central component of our approach is the Tactile-Force Adapter (TaF-Adapter), a tactile sensor encoder that extracts discretized latent information for encoding tactile observations. This mechanism ensures that the learned representations capture history-dependent, noise-insensitive physical dynamics rather than static visual textures. Finally, we integrate this force-aligned encoder into a VLA backbone. Extensive real-world experiments demonstrate that TaF-VLA policy significantly outperforms state-of-the-art tactile-vision-aligned and vision-only baselines on contact-rich tasks, verifying its ability to achieve robust, force-aware manipulation through cross-modal physical reasoning.