Shallow-π: Knowledge Distillation for Flow-based VLAs
作者: Boseong Jeon, Yunho Choi, Taehan Kim
分类: cs.RO
发布日期: 2026-01-28
💡 一句话要点
Shallow-π:面向流式VLA模型的知识蒸馏,显著加速机器人实时部署。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 知识蒸馏 模型压缩 机器人 实时推理
📋 核心要点
- 现有VLA模型主要关注token级别的效率优化,Transformer层级的系统性缩减研究不足,尤其是在流式VLA模型中。
- Shallow-π通过知识蒸馏,同时减少VLM骨干网络和流式动作头部的Transformer层数,实现模型压缩和加速。
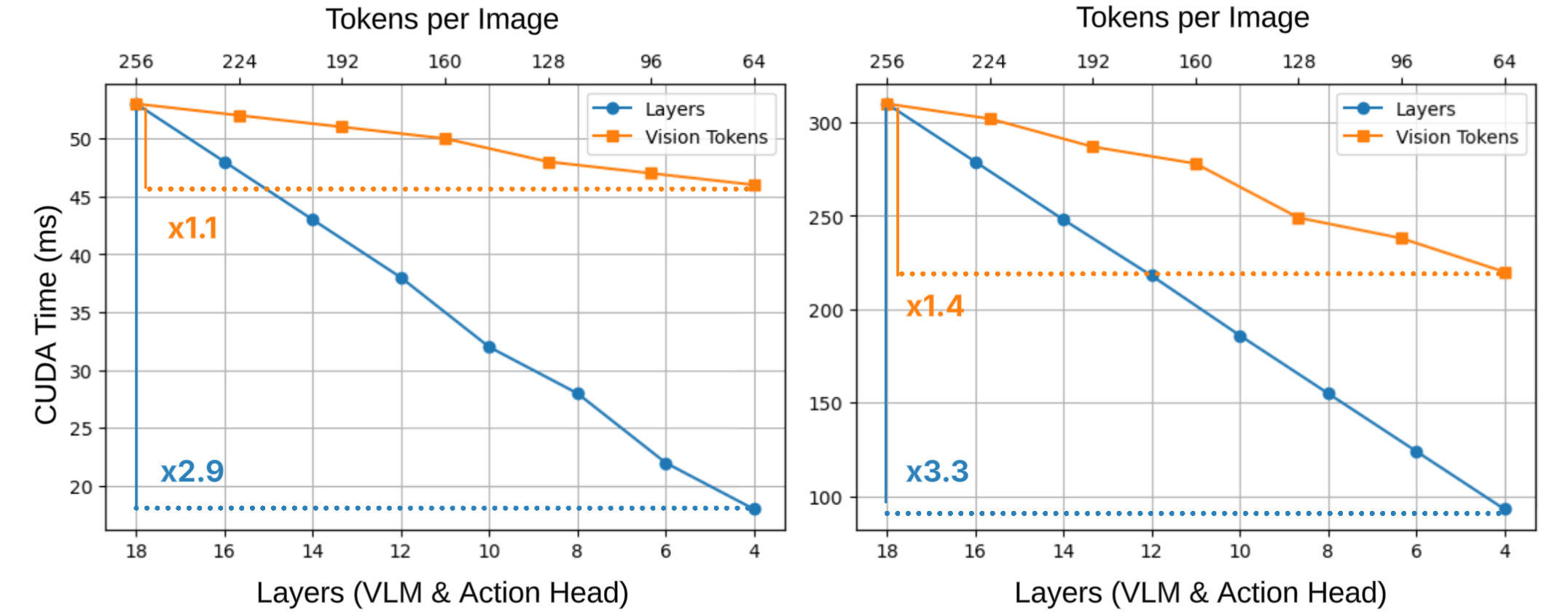
- 实验表明,Shallow-π在标准操作基准测试中,推理速度提升超过两倍,成功率下降小于1%,并在真实机器人平台上验证了有效性。
📝 摘要(中文)
针对视觉-语言-动作(VLA)模型在实时机器人部署中对快速片上推理的需求日益增长的问题,本文提出Shallow-π,一种基于知识蒸馏的框架,旨在大幅减少Transformer的深度。该方法同时压缩VLM骨干网络和基于流的动作头部的Transformer层数,从18层减少到6层。在标准操作基准测试中,Shallow-π在成功率仅下降不到1%的情况下,实现了超过两倍的推理速度提升,在精简VLA模型中达到了最先进的性能。此外,通过在Jetson Orin和Jetson Thor等工业级平台上,跨多个人形机器人平台进行的复杂动态操作场景的真实世界实验,验证了该方法的有效性。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人实时部署中面临推理速度的瓶颈。虽然视觉token剪枝等方法在token级别上提高了效率,但Transformer层级的缩减,特别是对于流式VLA模型,尚未得到充分研究。现有方法难以在保证性能的同时,满足实时性要求。
核心思路:本文的核心思路是利用知识蒸馏技术,将一个深度、性能优越的教师模型的知识迁移到一个浅层、高效的学生模型。通过这种方式,学生模型可以在大幅减少Transformer层数的同时,尽可能地保留教师模型的性能。这样设计的目的是在推理速度和模型性能之间取得平衡,从而满足实时机器人部署的需求。
技术框架:Shallow-π框架包含一个深度教师模型和一个浅层学生模型。教师模型是一个标准的流式VLA模型,具有较深的Transformer结构。学生模型则是一个层数较少的Transformer结构。训练过程包括:首先,使用标准VLA训练方法训练教师模型。然后,利用教师模型的输出(例如,动作分布)作为监督信号,训练学生模型。学生模型的训练目标是尽可能地模仿教师模型的输出,从而学习到教师模型的知识。
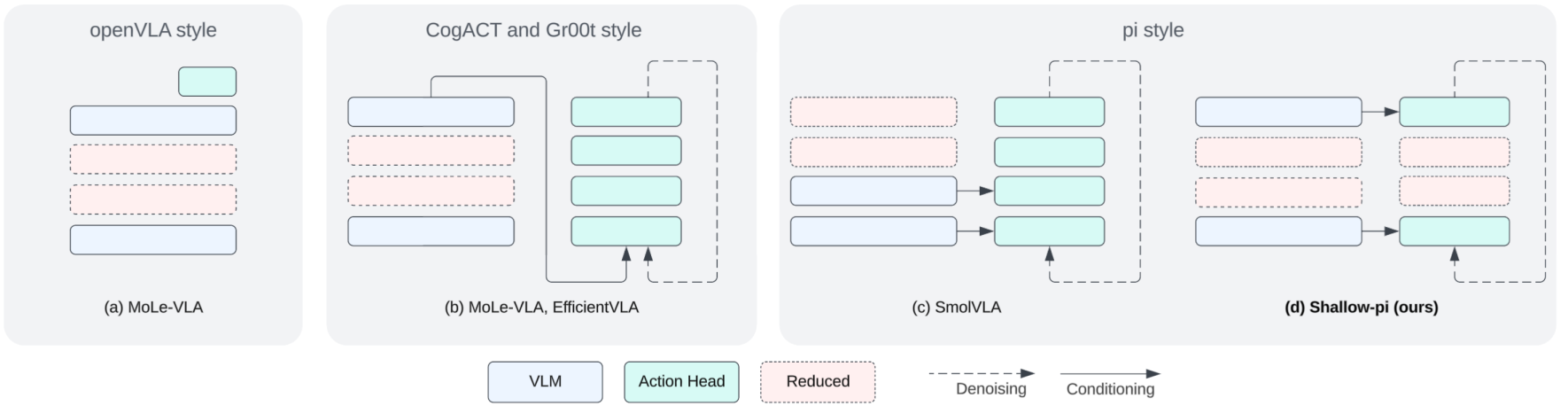
关键创新:Shallow-π的关键创新在于同时对VLM骨干网络和流式动作头部进行Transformer层数的缩减,并采用知识蒸馏进行训练。与以往主要关注token级别优化的方法不同,Shallow-π从模型结构层面入手,实现了更大幅度的模型压缩和加速。此外,该方法首次将知识蒸馏应用于流式VLA模型的Transformer层级缩减。
关键设计:在具体实现上,Shallow-π采用了多种知识蒸馏技术,例如,模仿教师模型的动作分布、中间层特征等。损失函数包括动作预测损失和蒸馏损失。Transformer层数的选择是一个关键参数,需要根据具体的任务和硬件平台进行调整。作者将模型从18层压缩到6层,取得了较好的效果。此外,作者还在真实机器人平台上进行了实验,验证了该方法在实际应用中的有效性。
🖼️ 关键图片

📊 实验亮点
Shallow-π在标准操作基准测试中,将Transformer层数从18层减少到6层,实现了超过两倍的推理速度提升,同时成功率仅下降不到1%。在真实机器人平台上,包括Jetson Orin和Jetson Thor,Shallow-π在复杂动态操作场景中表现出色,验证了其在实际应用中的有效性。该方法在精简VLA模型中达到了最先进的性能。
🎯 应用场景
Shallow-π具有广泛的应用前景,尤其是在计算资源受限的机器人平台上,例如无人机、移动机器人和人形机器人。该方法可以加速VLA模型的推理速度,使其能够实时响应环境变化,从而提高机器人的自主性和适应性。此外,Shallow-π还可以应用于其他需要高效推理的视觉-语言任务,例如图像描述和视觉问答。
📄 摘要(原文)
The growing demand for real-time robotic deployment necessitates fast and on-device inference for vision-language-action (VLA) models. Within the VLA literature, efficiency has been extensively studied at the token level, such as visual token pruning. In contrast, systematic transformer layer reduction has received limited attention and, to the best of our knowledge, has not been explored for flow-based VLA models under knowledge distillation. In this work, we propose Shallow-pi, a principled knowledge distillation framework that aggressively reduces the transformer depth of both the VLM backbone and the flow-based action head, compressing the model from 18 to 6 layers. Shallow-pi achieves over two times faster inference with less than one percent absolute drop in success rate on standard manipulation benchmarks, establishing state-of-the-art performance among reduced VLA models. Crucially, we validate our approach through industrial-scale real-world experiments on Jetson Orin and Jetson Thor across multiple robot platforms, including humanoid systems, in complex and dynamic manipulation scenarios.