AC^2-VLA: Action-Context-Aware Adaptive Computation in Vision-Language-Action Models for Efficient Robotic Manipulation
作者: Wenda Yu, Tianshi Wang, Fengling Li, Jingjing Li, Lei Zhu
分类: cs.RO, cs.MM
发布日期: 2026-01-27
💡 一句话要点
提出AC^2-VLA,通过动作上下文感知的自适应计算提升机器人操作中VLA模型的效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 自适应计算 动作上下文感知 模型压缩 自蒸馏 效率优化
📋 核心要点
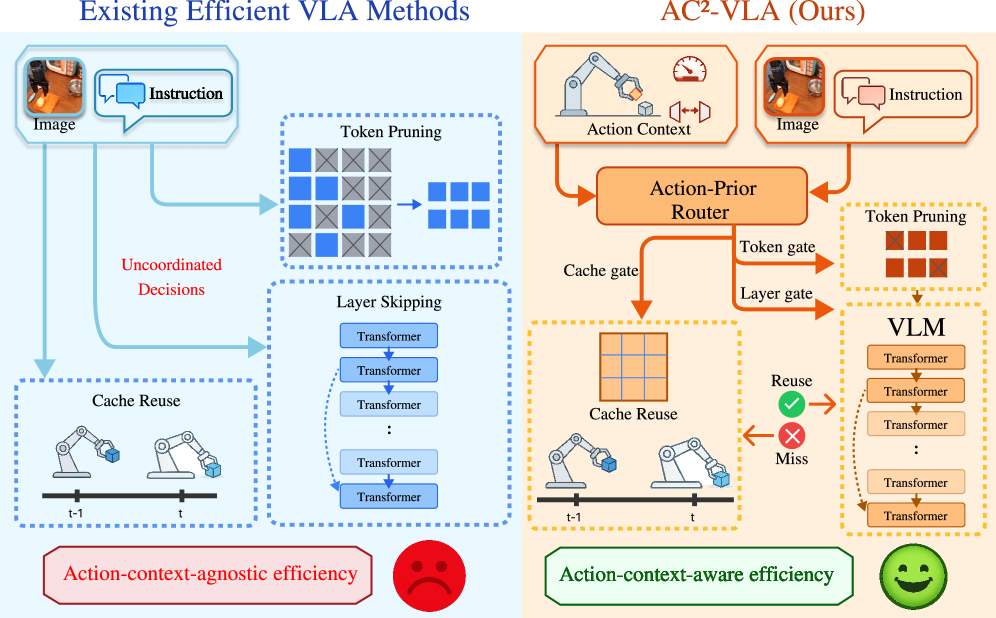
- VLA模型计算成本高昂,限制了其在机器人操作中的闭环部署,现有方法忽略了动作上下文。
- AC^2-VLA框架利用视觉、语言和动作上下文,自适应地进行认知重用、token剪枝和选择性模型执行。
- 通过动作引导的自蒸馏训练自适应策略,实验表明AC^2-VLA显著提升了效率,同时保持了任务成功率。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在机器人操作中表现出强大的性能,但由于每次都需要重复运行大型视觉-语言骨干网络,导致高延迟和计算成本,阻碍了其闭环部署。我们观察到VLA推理在时间、空间和深度维度上存在结构性冗余,并且大多数现有效率方法忽略了动作上下文,而动作上下文在具身任务中起着核心作用。为了解决这一差距,我们提出了VLA模型的动作上下文感知自适应计算(AC^2-VLA),这是一个统一的框架,它根据当前的视觉观察、语言指令和先前的动作状态来调节计算。基于这种以动作为中心的上下文,AC^2-VLA自适应地执行跨时间步的认知重用、token剪枝和模型组件的选择性执行,所有这些都在一个统一的机制中完成。为了训练自适应策略,我们引入了一种动作引导的自蒸馏方案,该方案在实现跨任务和设置的结构化稀疏化的同时,保留了密集VLA策略的行为。在机器人操作基准上的大量实验表明,AC^2-VLA实现了高达1.79倍的加速,同时将FLOPs降低到密集基线的29.4%,并具有相当的任务成功率。
🔬 方法详解
问题定义:VLA模型在机器人操作中表现出色,但其高计算成本和延迟阻碍了实际应用。现有方法通常忽略了动作上下文信息,未能充分利用VLA推理过程中的冗余,导致效率提升有限。因此,需要一种能够感知动作上下文并自适应调整计算资源的VLA模型。
核心思路:论文的核心思路是利用动作上下文信息,对VLA模型的计算过程进行自适应调整。通过分析视觉观察、语言指令和历史动作状态,模型可以判断哪些计算是必要的,哪些是冗余的,从而实现计算资源的有效利用。这种自适应计算策略旨在减少不必要的计算,提高推理速度,同时保持任务的成功率。
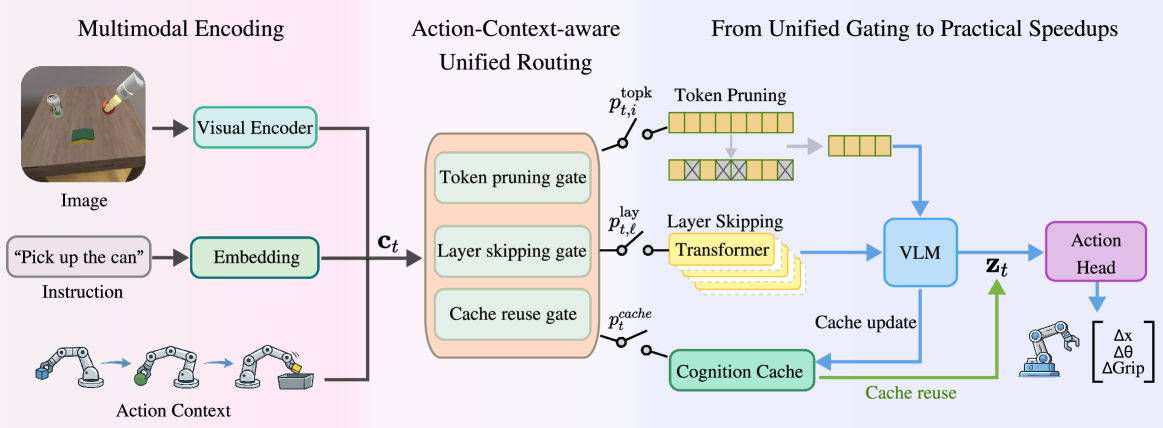
技术框架:AC^2-VLA框架包含三个主要模块:1) 上下文编码器:用于编码视觉观察、语言指令和历史动作状态,生成动作上下文向量。2) 自适应计算策略:基于上下文向量,决定是否进行认知重用、token剪枝和选择性模型执行。3) VLA模型:执行实际的视觉-语言-动作推理,生成控制指令。整个流程是,首先通过上下文编码器获取动作上下文信息,然后自适应计算策略根据上下文信息动态调整VLA模型的计算过程,最后VLA模型输出动作指令。
关键创新:该论文的关键创新在于提出了动作上下文感知的自适应计算策略。与传统的VLA模型相比,AC^2-VLA能够根据当前的任务状态动态调整计算资源,避免了不必要的计算,从而提高了效率。此外,动作引导的自蒸馏训练方法也保证了在进行模型稀疏化的同时,能够保留原始模型的性能。
关键设计:在上下文编码器中,可以使用Transformer等模型来提取视觉、语言和动作特征,并将它们融合在一起。自适应计算策略可以使用强化学习或监督学习来训练,目标是最大化效率和任务成功率。动作引导的自蒸馏损失函数可以设计为原始模型输出和稀疏模型输出之间的KL散度,以保证稀疏模型的行为与原始模型一致。具体的网络结构和参数设置需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
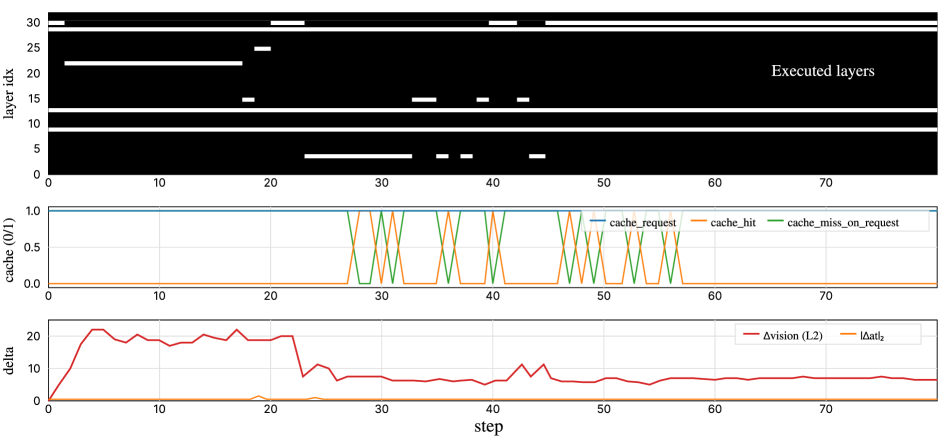
实验结果表明,AC^2-VLA在机器人操作基准上实现了显著的性能提升。与密集基线相比,AC^2-VLA实现了高达1.79倍的加速,同时将FLOPs降低到密集基线的29.4%,并且保持了相当的任务成功率。这些结果验证了AC^2-VLA在提高VLA模型效率方面的有效性。
🎯 应用场景
AC^2-VLA模型可广泛应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过降低计算成本和延迟,该模型可以使机器人更加高效、灵活地完成任务,并有望在工业自动化、智能家居、医疗机器人等领域发挥重要作用。此外,该研究提出的自适应计算思想也可以推广到其他视觉-语言任务中。
📄 摘要(原文)
Vision-Language-Action (VLA) models have demonstrated strong performance in robotic manipulation, yet their closed-loop deployment is hindered by the high latency and compute cost of repeatedly running large vision-language backbones at every timestep. We observe that VLA inference exhibits structured redundancies across temporal, spatial, and depth dimensions, and that most existing efficiency methods ignore action context, despite its central role in embodied tasks. To address this gap, we propose Action-Context-aware Adaptive Computation for VLA models (AC^2-VLA), a unified framework that conditions computation on current visual observations, language instructions, and previous action states. Based on this action-centric context, AC^2-VLA adaptively performs cognition reuse across timesteps, token pruning, and selective execution of model components within a unified mechanism. To train the adaptive policy, we introduce an action-guided self-distillation scheme that preserves the behavior of the dense VLA policy while enabling structured sparsification that transfers across tasks and settings. Extensive experiments on robotic manipulation benchmarks show that AC^2-VLA achieves up to a 1.79\times speedup while reducing FLOPs to 29.4% of the dense baseline, with comparable task success.