Trustworthy Evaluation of Robotic Manipulation: A New Benchmark and AutoEval Methods
作者: Mengyuan Liu, Juyi Sheng, Peiming Li, Ziyi Wang, Tianming Xu, Tiantian Xu, Hong Liu
分类: cs.RO
发布日期: 2026-01-26
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Eval-Actions基准和AutoEval架构,实现机器人操作行为的可信评估。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 可信评估 模仿学习 视觉-动作模型 基准数据集
📋 核心要点
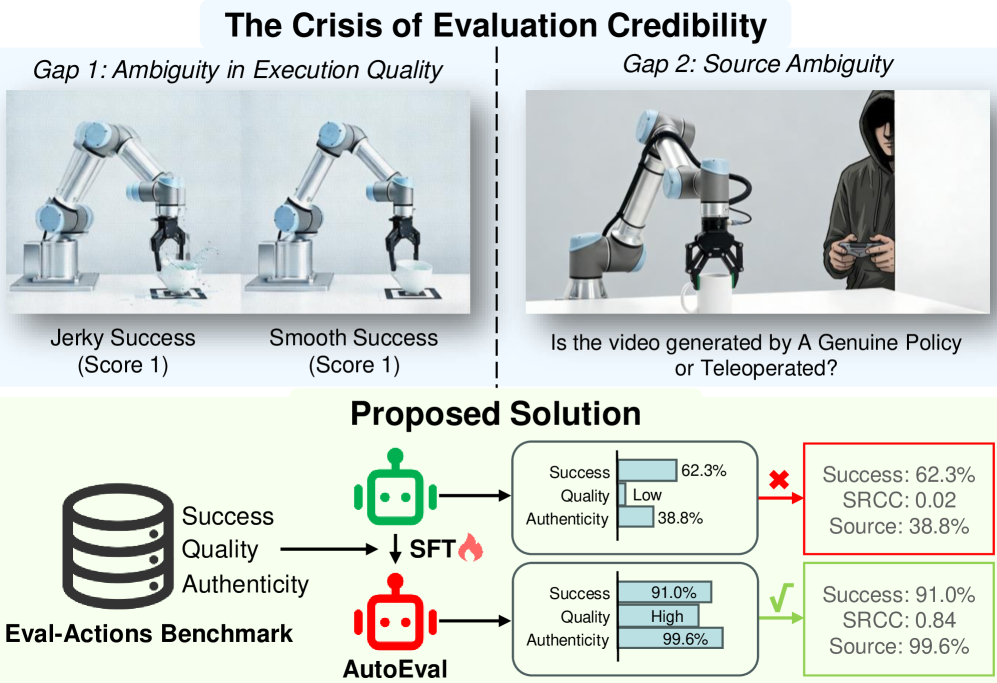
- 现有机器人操作评估方法依赖二元成功率,忽略了来源真实性和执行质量等关键信任维度。
- 提出Eval-Actions基准和AutoEval架构,前者包含成功和失败案例,后者利用时空聚合和运动学校准进行评估。
- 实验表明,AutoEval在评估指标上表现出色,并能有效区分策略生成和人类遥操作行为。
📝 摘要(中文)
随着视觉-动作和视觉-语言-动作模型的快速发展,模仿学习显著提升了机器人操作能力。然而,评估方法滞后,阻碍了这些行为的可信评估。现有范式依赖于二元成功率,未能解决信任的关键维度:来源真实性(即区分真实的策略行为与人类遥操作)和执行质量(例如,平滑性和安全性)。为了弥合这些差距,我们提出了一种结合Eval-Actions基准和AutoEval架构的解决方案。Eval-Actions集成了VA和VLA策略执行轨迹以及人类遥操作数据,显式地包含了失败场景。该数据集围绕三个核心监督信号构建:专家评分(EG)、排序引导偏好(RG)和思维链(CoT)。AutoEval利用时空聚合进行语义评估,并通过辅助运动学校准信号来细化运动平滑性;AutoEval Plus(AutoEval-P)结合了群体相对策略优化(GRPO)范式,以增强逻辑推理能力。实验表明,AutoEval在EG和RG协议下分别实现了0.81和0.84的Spearman等级相关系数(SRCC)。该框架具有强大的来源区分能力,能够以99.6%的准确率区分策略生成和遥操作视频,从而为可信的机器人评估建立了严格的标准。
🔬 方法详解
问题定义:现有机器人操作评估方法主要依赖于二元成功率,无法全面评估策略的质量和可信度。尤其缺乏对策略来源真实性(区分策略生成与人类遥操作)和执行质量(如平滑性、安全性)的有效评估手段。这阻碍了机器人操作领域的发展,难以建立可靠的性能评估标准。
核心思路:论文的核心思路是构建一个更全面、更可信的机器人操作评估体系。通过构建包含成功和失败案例的Eval-Actions基准,以及设计能够自动评估策略质量和来源真实性的AutoEval架构,从而弥补现有评估方法的不足。这种设计旨在提供更细粒度、更客观的评估结果,促进机器人操作策略的改进和发展。
技术框架:整体框架包含两个主要部分:Eval-Actions基准和AutoEval架构。Eval-Actions基准包含机器人操作任务的多种轨迹数据,包括VA/VLA策略执行和人类遥操作,并提供专家评分、排序引导偏好和思维链等多种监督信号。AutoEval架构则利用时空聚合进行语义评估,并通过运动学校准信号来优化运动平滑性。AutoEval Plus (AutoEval-P) 在此基础上,引入了群体相对策略优化(GRPO)范式,以增强逻辑推理能力。
关键创新:论文的关键创新在于:1) 提出了Eval-Actions基准,该基准包含失败案例和多种监督信号,更全面地反映了机器人操作的真实场景。2) 设计了AutoEval架构,能够自动评估策略的质量和来源真实性,摆脱了对人工评估的依赖。3) 结合时空聚合、运动学校准和群体相对策略优化等技术,提高了评估的准确性和可靠性。与现有方法相比,该方法能够更全面、更客观地评估机器人操作策略的性能。
关键设计:AutoEval架构的关键设计包括:1) 使用时空聚合网络提取视频中的语义信息。2) 引入运动学校准信号,通过分析机器人关节运动的平滑性来评估执行质量。3) AutoEval-P 使用 GRPO 损失函数,鼓励策略在群体中表现出相对优势,从而提高逻辑推理能力。具体参数设置和网络结构细节在论文中有详细描述,但此处未提供具体数值。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AutoEval架构在专家评分(EG)和排序引导偏好(RG)协议下分别实现了0.81和0.84的Spearman等级相关系数(SRCC),表明其评估结果与人类专家的判断高度一致。更重要的是,该框架能够以99.6%的准确率区分策略生成和遥操作视频,证明其具有强大的来源区分能力,为可信的机器人评估提供了有力支持。
🎯 应用场景
该研究成果可广泛应用于机器人操作策略的开发、测试和评估。例如,可以用于比较不同策略的性能,识别策略的优缺点,以及评估策略在真实环境中的可靠性。此外,该方法还可以用于机器人教育和培训,帮助学生和研究人员更好地理解和掌握机器人操作技术。未来,该研究有望推动机器人操作技术在工业自动化、医疗保健、家庭服务等领域的应用。
📄 摘要(原文)
Driven by the rapid evolution of Vision-Action and Vision-Language-Action models, imitation learning has significantly advanced robotic manipulation capabilities. However, evaluation methodologies have lagged behind, hindering the establishment of Trustworthy Evaluation for these behaviors. Current paradigms rely on binary success rates, failing to address the critical dimensions of trust: Source Authenticity (i.e., distinguishing genuine policy behaviors from human teleoperation) and Execution Quality (e.g., smoothness and safety). To bridge these gaps, we propose a solution that combines the Eval-Actions benchmark and the AutoEval architecture. First, we construct the Eval-Actions benchmark to support trustworthiness analysis. Distinct from existing datasets restricted to successful human demonstrations, Eval-Actions integrates VA and VLA policy execution trajectories alongside human teleoperation data, explicitly including failure scenarios. This dataset is structured around three core supervision signals: Expert Grading (EG), Rank-Guided preferences (RG), and Chain-of-Thought (CoT). Building on this, we propose the AutoEval architecture: AutoEval leverages Spatio-Temporal Aggregation for semantic assessment, augmented by an auxiliary Kinematic Calibration Signal to refine motion smoothness; AutoEval Plus (AutoEval-P) incorporates the Group Relative Policy Optimization (GRPO) paradigm to enhance logical reasoning capabilities. Experiments show AutoEval achieves Spearman's Rank Correlation Coefficients (SRCC) of 0.81 and 0.84 under the EG and RG protocols, respectively. Crucially, the framework possesses robust source discrimination capabilities, distinguishing between policy-generated and teleoperated videos with 99.6% accuracy, thereby establishing a rigorous standard for trustworthy robotic evaluation. Our project and code are available at https://term-bench.github.io/.