A Pragmatic VLA Foundation Model
作者: Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, Yiyu Ren, Kejia Zhang, Hui Yu, Jingmei Zhao, Shuai Zhou, Zhenqi Qiu, Houlong Xiong, Ziyu Wang, Zechen Wang, Ran Cheng, Yong-Lu Li, Yongtao Huang, Xing Zhu, Yujun Shen, Kecheng Zheng
分类: cs.RO, cs.CV
发布日期: 2026-01-26
备注: Project Webpage: https://technology.robbyant.com/lingbot-vla/, Code: https://github.com/Robbyant/lingbot-vla/
💡 一句话要点
LingBot-VLA:基于大规模真实世界数据的实用型视觉-语言-动作机器人基础模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 基础模型 泛化能力 真实世界数据 双臂机器人 模仿学习
📋 核心要点
- 现有VLA模型在任务和平台泛化能力上存在不足,且数据和计算成本高昂,限制了其在机器人操作中的应用。
- LingBot-VLA利用大规模真实世界数据进行训练,旨在提升模型在不同任务和机器人平台上的泛化能力,并优化训练效率。
- 实验结果表明,LingBot-VLA在多个机器人平台上表现出卓越的性能和泛化能力,并实现了显著的训练速度提升。
📝 摘要(中文)
本文提出了一种实用的视觉-语言-动作(VLA)基础模型LingBot-VLA,旨在为机器人操作提供强大的泛化能力,同时保证成本效益。该模型利用来自9种流行的双臂机器人配置的约20,000小时真实世界数据进行训练。在三个机器人平台上进行的系统评估中,每个平台完成100个任务,每个任务进行130次后训练迭代,LingBot-VLA明显优于竞争对手,展示了其强大的性能和广泛的泛化能力。此外,该论文还构建了一个高效的代码库,在8-GPU训练设置下,每秒每GPU可处理261个样本,比现有的VLA代码库快1.5~2.8倍(取决于所依赖的VLM基础模型)。为了促进机器人学习领域的发展,该论文开放了代码、基础模型和基准数据,重点是支持更具挑战性的任务并促进健全的评估标准。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作领域面临泛化性差和训练成本高的问题。具体来说,模型难以适应不同的机器人平台和任务,需要大量的特定领域数据和计算资源进行微调,限制了其在实际场景中的应用。
核心思路:LingBot-VLA的核心思路是利用大规模的真实世界机器人操作数据进行预训练,从而学习到通用的视觉、语言和动作之间的关联。通过这种方式,模型能够更好地理解指令,并将其转化为相应的机器人动作,从而提高泛化能力。
技术框架:LingBot-VLA的整体架构包含视觉编码器、语言编码器和动作解码器三个主要模块。视觉编码器负责提取图像特征,语言编码器负责理解指令,动作解码器则根据视觉特征和指令生成机器人的动作序列。该框架采用Transformer架构,能够有效地处理长序列数据,并捕捉不同模态之间的复杂关系。
关键创新:LingBot-VLA的关键创新在于其训练数据的规模和多样性。该模型使用了来自9种不同双臂机器人配置的20,000小时真实世界数据进行训练,涵盖了各种不同的任务和场景。这种大规模的训练数据使得模型能够学习到更加鲁棒和通用的特征表示,从而提高泛化能力。
关键设计:在训练过程中,LingBot-VLA采用了对比学习和模仿学习相结合的策略。对比学习用于学习视觉和语言之间的关联,模仿学习用于学习人类操作员的动作策略。此外,该模型还采用了数据增强技术,例如随机裁剪、旋转和颜色抖动,以提高模型的鲁棒性。为了提高训练效率,该论文还优化了代码库,使其能够在多GPU环境下高效运行。
🖼️ 关键图片
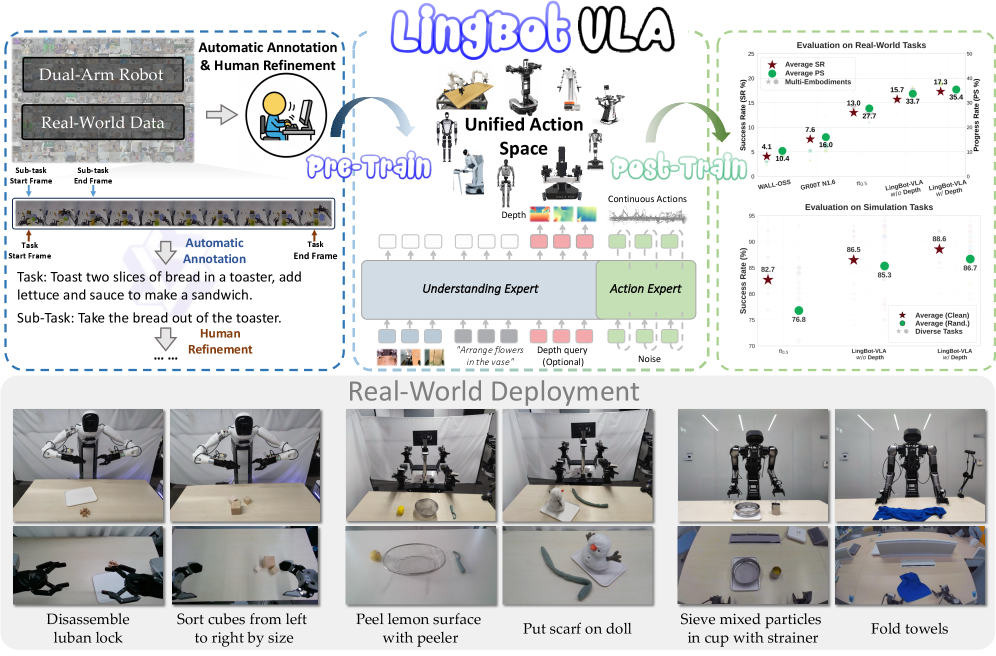


📊 实验亮点
LingBot-VLA在三个机器人平台上进行了系统评估,每个平台完成100个任务,每个任务进行130次后训练迭代。实验结果表明,LingBot-VLA明显优于竞争对手,展示了其强大的性能和广泛的泛化能力。此外,该论文构建的高效代码库,在8-GPU训练设置下,每秒每GPU可处理261个样本,比现有的VLA代码库快1.5~2.8倍。
🎯 应用场景
LingBot-VLA具有广泛的应用前景,可应用于智能制造、家庭服务、医疗辅助等领域。例如,在智能制造中,它可以用于自动化装配、质量检测等任务;在家庭服务中,它可以用于帮助老年人或残疾人完成日常任务;在医疗辅助中,它可以用于辅助医生进行手术或康复治疗。该研究有望推动机器人技术的发展,使其更加智能化和实用化。
📄 摘要(原文)
Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.