DV-VLN: Dual Verification for Reliable LLM-Based Vision-and-Language Navigation
作者: Zijun Li, Shijie Li, Zhenxi Zhang, Bin Li, Shoujun Zhou
分类: cs.RO
发布日期: 2026-01-26
🔗 代码/项目: GITHUB
💡 一句话要点
提出DV-VLN以解决LLM驱动的视觉语言导航中的决策不可靠问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 大型语言模型 双重验证 结构化思维链 机器人导航 多模态学习 智能体决策
📋 核心要点
- 现有的LLM基础代理在视觉语言导航中依赖单次决策,导致在复杂环境中容易出现错误累积和不可靠性。
- DV-VLN框架采用生成-验证的策略,通过结构化的思维链和双重验证机制提升决策的可靠性。
- 实验结果显示DV-VLN在多个数据集上均优于传统方法,展现出良好的性能和可解释性。
📝 摘要(中文)
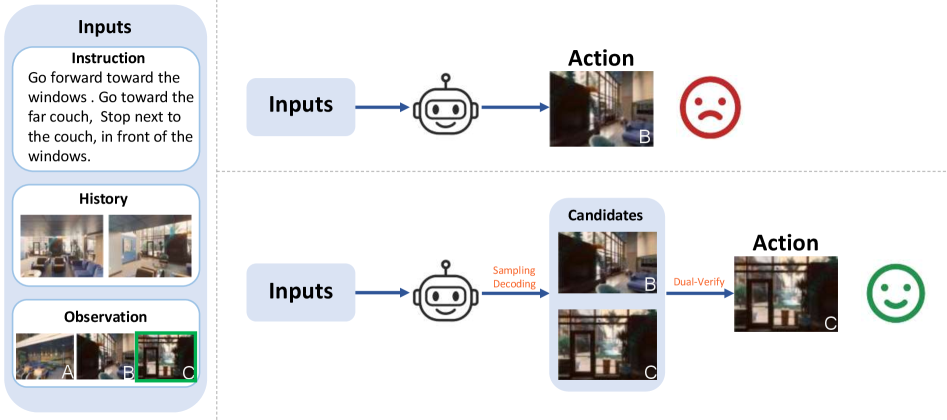
视觉语言导航(VLN)要求智能体根据自然语言指令在复杂的3D环境中进行导航。尽管大型语言模型(LLMs)的进展提升了语言驱动导航的可解释性,但现有的LLM基础代理仍依赖单次动作决策,容易因局部不匹配和推理不完善而偏离正确路径,导致错误累积和在未见环境中的可靠性降低。本文提出了DV-VLN,一个新的VLN框架,采用生成-验证范式。DV-VLN首先对开源LLaMA-2骨干进行参数高效的领域内适应,以生成结构化的导航思维链,然后通过真实-虚假验证(TFV)和掩码实体验证(MEV)两个互补通道验证候选动作。实验结果表明,DV-VLN在R2R、RxR(英语子集)和REVERIE上均优于直接预测和仅采样基线,展现了与语言单一VLN代理的竞争性能以及与多模态系统的良好对比。
🔬 方法详解
问题定义:本文旨在解决LLM驱动的视觉语言导航中,由于依赖单次决策而导致的错误累积和不可靠性问题。现有方法在处理复杂环境时表现不佳,容易受到局部信息不匹配的影响。
核心思路:DV-VLN框架采用生成-验证的范式,首先生成结构化的导航思维链,然后通过双重验证机制(TFV和MEV)来确认候选动作的有效性。这种设计旨在提高决策的可靠性和可解释性。
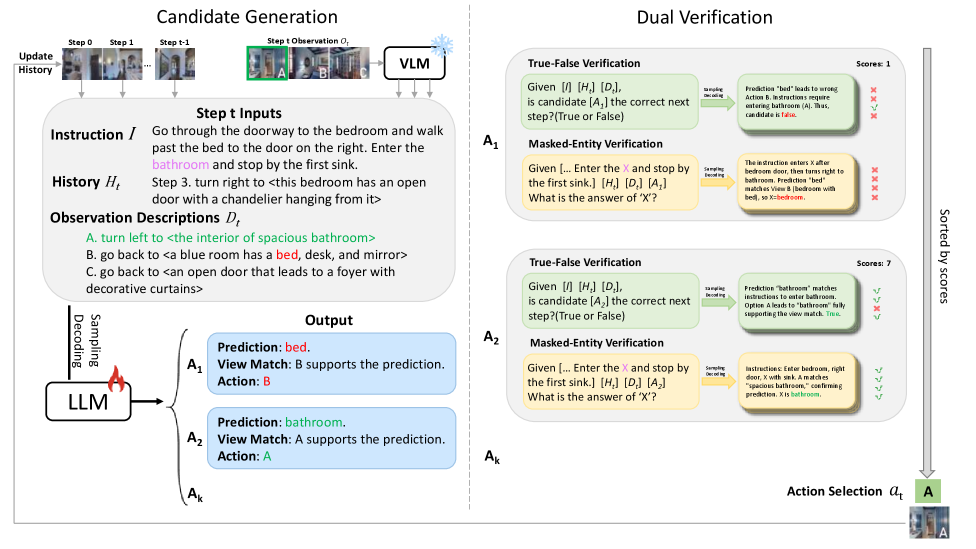
技术框架:DV-VLN的整体架构包括两个主要阶段:首先是基于LLaMA-2的参数高效领域适应,生成导航思维链;其次是通过TFV和MEV对候选动作进行验证,最终根据验证结果对动作进行重排序。
关键创新:DV-VLN的主要创新在于引入双重验证机制,通过TFV和MEV的结合,显著提升了决策的准确性和可靠性。这一方法与传统的单一决策机制形成鲜明对比。
关键设计:在技术细节上,DV-VLN采用了参数高效的领域适应策略,设计了适合的损失函数以优化验证过程,并在网络结构上进行了针对性的调整,以支持双重验证的实现。
🖼️ 关键图片
📊 实验亮点
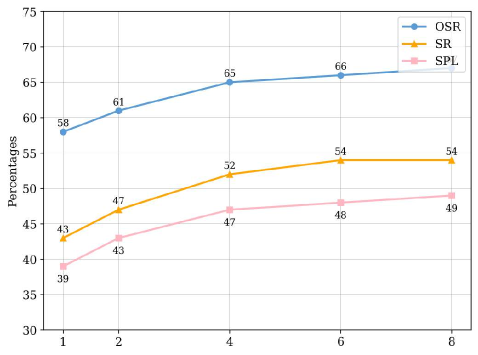
实验结果表明,DV-VLN在R2R、RxR(英语子集)和REVERIE数据集上均显著优于直接预测和仅采样基线,尤其在复杂场景中表现出更高的准确性和可靠性,展示了与语言单一VLN代理的竞争性能。
🎯 应用场景
DV-VLN的研究成果在智能导航、机器人控制和人机交互等领域具有广泛的应用潜力。通过提升视觉语言导航的可靠性,该框架可用于开发更智能的导航系统,改善用户体验,并推动自动化技术的发展。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) requires an embodied agent to navigate in a complex 3D environment according to natural language instructions. Recent progress in large language models (LLMs) has enabled language-driven navigation with improved interpretability. However, most LLM-based agents still rely on single-shot action decisions, where the model must choose one option from noisy, textualized multi-perspective observations. Due to local mismatches and imperfect intermediate reasoning, such decisions can easily deviate from the correct path, leading to error accumulation and reduced reliability in unseen environments. In this paper, we propose DV-VLN, a new VLN framework that follows a generate-then-verify paradigm. DV-VLN first performs parameter-efficient in-domain adaptation of an open-source LLaMA-2 backbone to produce a structured navigational chain-of-thought, and then verifies candidate actions with two complementary channels: True-False Verification (TFV) and Masked-Entity Verification (MEV). DV-VLN selects actions by aggregating verification successes across multiple samples, yielding interpretable scores for reranking. Experiments on R2R, RxR (English subset), and REVERIE show that DV-VLN consistently improves over direct prediction and sampling-only baselines, achieving competitive performance among language-only VLN agents and promising results compared with several cross-modal systems.Code is available at https://github.com/PlumJun/DV-VLN.