SG-CADVLM: A Context-Aware Decoding Powered Vision Language Model for Safety-Critical Scenario Generation
作者: Hongyi Zhao, Shuo Wang, Qijie He, Ziyuan Pu
分类: cs.RO
发布日期: 2026-01-26
💡 一句话要点
提出SG-CADVLM,利用上下文感知解码生成安全关键场景,提升自动驾驶验证效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全关键场景生成 视觉语言模型 上下文感知解码 自动驾驶验证 多模态融合
📋 核心要点
- 现有数据驱动方法在生成安全关键场景时,由于依赖现有潜在分布,缺乏多样性;对抗方法则难以保证生成场景的物理真实性。
- SG-CADVLM的核心思想是利用上下文感知解码,结合碰撞报告和道路网络图等多模态输入,引导视觉语言模型生成更逼真、符合实际事故特征的场景。
- 实验表明,SG-CADVLM生成的关键风险场景比例显著提升,达到84.4%,相比基线方法提升了469%,并能生成可执行的自动驾驶仿真。
📝 摘要(中文)
为了验证自动驾驶汽车的安全性,需要在安全关键场景下进行测试。由于真实世界中此类事件稀少且碰撞风险高昂,因此利用碰撞报告生成逼真的高风险场景成为一种重要替代方案。现有方法受限于数据驱动方法的多样性不足和对抗方法的物理真实性欠缺。基于大型语言模型(LLM)和视觉语言模型(VLM)的方法展现出潜力,但存在上下文抑制问题,导致生成的场景偏离实际事故特征。本文提出了SG-CADVLM,一个结合上下文感知解码和多模态输入处理的框架,用于从碰撞报告和道路网络图中生成安全关键场景。该框架缓解了VLM的幻觉问题,并能够同时生成道路几何形状和车辆轨迹。实验结果表明,SG-CADVLM生成的关键风险场景的比例为84.4%,而基线方法仅为12.5%,提升了469%,并生成可执行的自动驾驶车辆测试仿真。
🔬 方法详解
问题定义:自动驾驶安全验证需要大量安全关键场景,但真实场景数据稀缺且测试成本高昂。现有方法,如数据驱动和对抗方法,在多样性和物理真实性方面存在局限性。基于LLM/VLM的方法虽然有潜力,但存在上下文抑制问题,导致生成场景与实际事故不符。
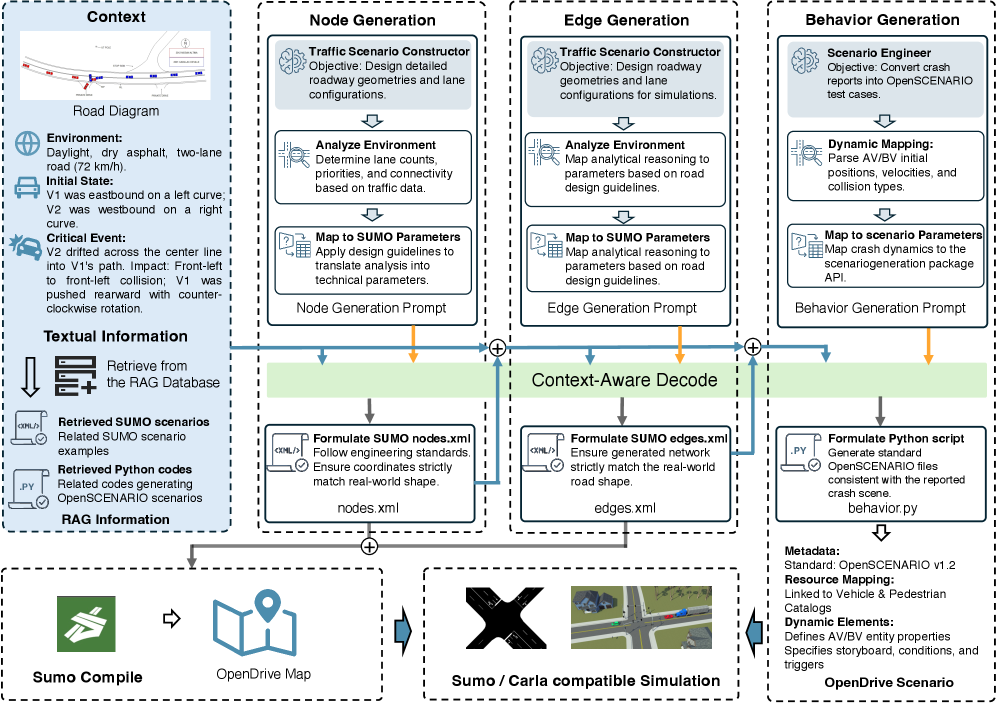
核心思路:SG-CADVLM的核心思路是通过上下文感知解码,引导VLM更好地理解和利用输入的碰撞报告和道路网络图等信息,从而生成更符合实际事故特征的安全关键场景。通过显式地关注和利用上下文信息,缓解VLM的幻觉问题,提高生成场景的真实性和有效性。
技术框架:SG-CADVLM框架包含多模态输入处理模块和上下文感知解码模块。多模态输入处理模块负责提取碰撞报告中的文本信息和道路网络图中的视觉信息,并将它们编码成VLM可以理解的表示。上下文感知解码模块则利用这些表示,指导VLM生成道路几何形状和车辆轨迹。整体流程是从碰撞报告和道路网络图出发,经过编码和解码,最终生成可用于自动驾驶测试的仿真场景。
关键创新:SG-CADVLM的关键创新在于上下文感知解码机制。传统VLM在生成过程中容易受到内部参数知识的影响,忽略输入的上下文信息,导致生成结果与实际事故不符。SG-CADVLM通过引入上下文感知解码,显式地引导VLM关注和利用输入的上下文信息,从而缓解了VLM的幻觉问题,提高了生成场景的真实性和有效性。
关键设计:论文中可能涉及的关键设计包括:用于编码碰撞报告和道路网络图的特定网络结构(例如,Transformer、CNN等),上下文感知解码的具体实现方式(例如,注意力机制、门控机制等),以及用于评估生成场景质量的损失函数(例如,物理约束损失、行为合理性损失等)。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片


📊 实验亮点
SG-CADVLM在生成关键风险场景方面的表现显著优于基线方法,达到了84.4%的成功率,相比基线方法的12.5%提升了469%。这表明SG-CADVLM能够更有效地生成符合实际事故特征的安全关键场景,为自动驾驶车辆的安全性验证提供了更可靠的手段。
🎯 应用场景
SG-CADVLM可应用于自动驾驶车辆的安全性验证和测试,通过生成大量逼真的安全关键场景,帮助开发者更全面地评估和改进自动驾驶系统的性能。此外,该技术还可用于交通安全研究,分析事故发生的原因和模式,为改进道路设计和交通管理提供依据。未来,该方法有望扩展到其他安全攸关领域,如机器人、航空航天等。
📄 摘要(原文)
Autonomous vehicle safety validation requires testing on safety-critical scenarios, but these events are rare in real-world driving and costly to test due to collision risks. Crash reports provide authentic specifications of safety-critical events, offering a vital alternative to scarce real-world collision trajectory data. This makes them valuable sources for generating realistic high-risk scenarios through simulation. Existing approaches face significant limitations because data-driven methods lack diversity due to their reliance on existing latent distributions, whereas adversarial methods often produce unrealistic scenarios lacking physical fidelity. Large Language Model (LLM) and Vision Language Model (VLM)-based methods show significant promise. However, they suffer from context suppression issues where internal parametric knowledge overrides crash specifications, producing scenarios that deviate from actual accident characteristics. This paper presents SG-CADVLM (A Context-Aware Decoding Powered Vision Language Model for Safety-Critical Scenario Generation), a framework that integrates Context-Aware Decoding with multi-modal input processing to generate safety-critical scenarios from crash reports and road network diagrams. The framework mitigates VLM hallucination issues while enabling the simultaneous generation of road geometry and vehicle trajectories. The experimental results demonstrate that SG-CADVLM generates critical risk scenarios at a rate of 84.4% compared to 12.5% for the baseline methods, representing an improvement of 469%, while producing executable simulations for autonomous vehicle testing.