TC-IDM: Grounding Video Generation for Executable Zero-shot Robot Motion
作者: Weishi Mi, Yong Bao, Xiaowei Chi, Xiaozhu Ju, Zhiyuan Qin, Kuangzhi Ge, Kai Tang, Peidong Jia, Shanghang Zhang, Jian Tang
分类: cs.RO
发布日期: 2026-01-26
💡 一句话要点
提出工具中心逆动力学模型(TC-IDM),用于生成式世界模型驱动的零样本机器人运动控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 生成式世界模型 逆动力学模型 工具中心表示 零样本学习
📋 核心要点
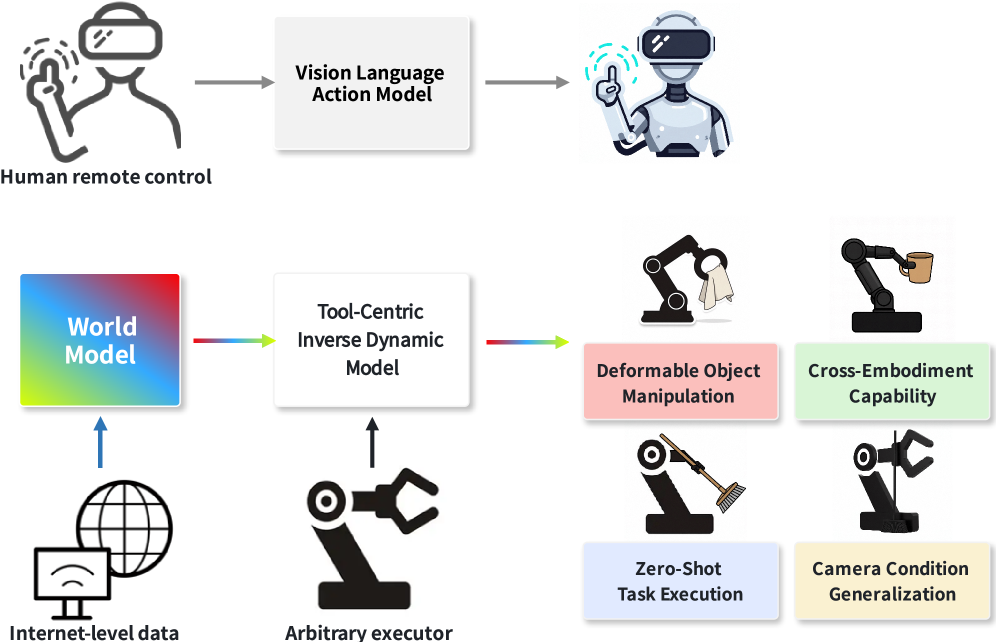
- 现有VLA方法依赖大规模机器人数据,泛化性受限;生成式世界模型虽有潜力,但像素级规划难以转化为可执行动作。
- TC-IDM以工具轨迹为中间表示,从生成视频中提取工具点云轨迹,解耦动作头预测末端执行器运动。
- 实验表明,TC-IDM在真实世界任务中平均成功率达61.11%,尤其在简单任务和零样本可变形物体任务上表现出色。
📝 摘要(中文)
视觉-语言-动作(VLA)范式通过利用视觉-语言模型实现了强大的机器人控制,但其对大规模、高质量机器人数据的依赖限制了其泛化能力。生成式世界模型为通用具身智能提供了一个有希望的替代方案,但其像素级规划与物理可执行动作之间仍然存在关键差距。为此,我们提出了工具中心逆动力学模型(TC-IDM)。通过关注世界模型合成的工具的想象轨迹,TC-IDM建立了一个鲁棒的中间表示,弥合了视觉规划和物理控制之间的差距。TC-IDM通过从生成的视频中分割和3D运动估计来提取工具的点云轨迹。考虑到不同的工具属性,我们的架构采用了解耦的动作头,将这些规划的轨迹投影到6自由度末端执行器运动和相应的控制信号中。这种规划-翻译范式不仅支持各种末端执行器,而且显著提高了视点不变性。此外,它在长时程和分布外任务中表现出强大的泛化能力,包括与可变形物体的交互。在真实世界的评估中,带有TC-IDM的世界模型实现了61.11%的平均成功率,在简单任务上为77.7%,在零样本可变形物体任务上为38.46%。它大大优于端到端VLA风格的基线和其他逆动力学模型。
🔬 方法详解
问题定义:现有基于视觉-语言-动作(VLA)的机器人控制方法依赖于大规模、高质量的机器人数据进行训练,这限制了其泛化能力。生成式世界模型虽然具有潜力,但其生成的像素级规划与机器人能够执行的物理动作之间存在着巨大的鸿沟,难以直接应用。因此,如何将世界模型的视觉规划转化为可执行的机器人动作是一个关键问题。
核心思路:论文的核心思路是引入一个工具中心的中间表示,即工具的轨迹。通过从世界模型生成的视频中提取工具的轨迹,并将其转化为机器人末端执行器的运动指令,从而弥合视觉规划和物理控制之间的差距。这种方法的核心在于将复杂的环境交互分解为工具的运动规划,降低了控制的难度。
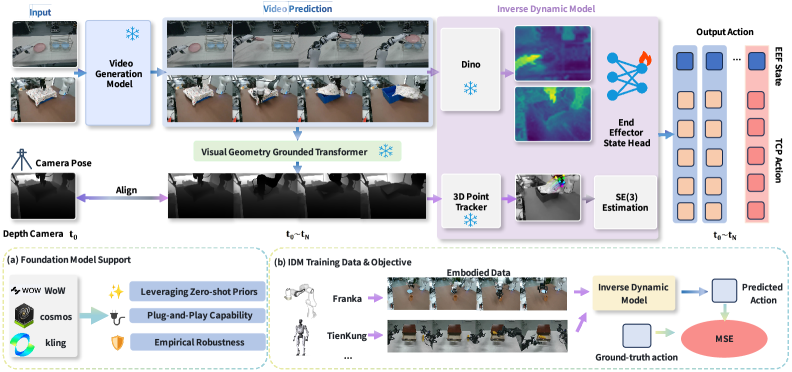
技术框架:TC-IDM的整体框架包含以下几个主要模块:1) 视频生成模块:利用世界模型生成包含工具交互的视频。2) 工具轨迹提取模块:从生成的视频中分割出工具,并估计其3D运动轨迹,得到工具的点云轨迹。3) 动作解耦模块:针对不同的工具属性,采用解耦的动作头,将工具轨迹投影到6自由度的末端执行器运动和相应的控制信号。4) 机器人控制模块:根据生成的控制信号,控制机器人执行相应的动作。
关键创新:该方法最重要的创新点在于提出了工具中心的中间表示,将视觉规划和物理控制解耦。与直接将视觉信息映射到机器人动作的端到端方法相比,TC-IDM更加关注工具的运动轨迹,从而提高了泛化能力和鲁棒性。此外,解耦的动作头设计使得该方法可以适应不同的工具和末端执行器。
关键设计:在工具轨迹提取模块中,使用了基于分割和3D运动估计的方法来获取工具的点云轨迹。在动作解耦模块中,针对不同的工具属性(例如,抓取、推动、旋转),设计了不同的动作头,每个动作头负责预测末端执行器在特定自由度上的运动。损失函数的设计也至关重要,需要同时考虑轨迹的准确性和控制信号的平滑性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TC-IDM在真实世界的机器人任务中取得了显著的性能提升。在平均成功率方面,TC-IDM达到了61.11%,优于端到端VLA风格的基线和其他逆动力学模型。尤其是在简单任务上,成功率高达77.7%。在更具挑战性的零样本可变形物体任务上,TC-IDM也取得了38.46%的成功率,展示了其强大的泛化能力。
🎯 应用场景
该研究成果可应用于各种机器人自动化任务,例如工业生产中的装配、搬运,家庭服务中的物品整理、清洁,以及医疗领域的辅助手术等。通过结合生成式世界模型,机器人可以更好地理解和适应复杂环境,从而实现更智能、更灵活的自动化。
📄 摘要(原文)
The vision-language-action (VLA) paradigm has enabled powerful robotic control by leveraging vision-language models, but its reliance on large-scale, high-quality robot data limits its generalization. Generative world models offer a promising alternative for general-purpose embodied AI, yet a critical gap remains between their pixel-level plans and physically executable actions. To this end, we propose the Tool-Centric Inverse Dynamics Model (TC-IDM). By focusing on the tool's imagined trajectory as synthesized by the world model, TC-IDM establishes a robust intermediate representation that bridges the gap between visual planning and physical control. TC-IDM extracts the tool's point cloud trajectories via segmentation and 3D motion estimation from generated videos. Considering diverse tool attributes, our architecture employs decoupled action heads to project these planned trajectories into 6-DoF end-effector motions and corresponding control signals. This plan-and-translate paradigm not only supports a wide range of end-effectors but also significantly improves viewpoint invariance. Furthermore, it exhibits strong generalization capabilities across long-horizon and out-of-distribution tasks, including interacting with deformable objects. In real-world evaluations, the world model with TC-IDM achieves an average success rate of 61.11 percent, with 77.7 percent on simple tasks and 38.46 percent on zero-shot deformable object tasks. It substantially outperforms end-to-end VLA-style baselines and other inverse dynamics models.