Scaling Rough Terrain Locomotion with Automatic Curriculum Reinforcement Learning
作者: Ziming Li, Chenhao Li, Marco Hutter
分类: cs.RO
发布日期: 2026-01-24
💡 一句话要点
提出基于学习进度的自动课程强化学习,提升四足机器人复杂地形运动能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 强化学习 课程学习 复杂地形 运动控制
📋 核心要点
- 现有课程学习方法在复杂地形机器人运动中面临挑战,难以定义任务难度排序。
- LP-ACRL通过在线估计学习进度,自适应调整任务采样,实现自动课程生成。
- ANYmal D在多种地形上实现2.5m/s线速度和3.0rad/s角速度,性能显著提升。
📝 摘要(中文)
课程学习在机器人学习中表现出显著效果。然而,当扩展到复杂、广泛的任务空间时,它仍然面临局限性。这类任务空间通常缺乏明确的难度结构,使得先前方法所需的难度排序难以定义。我们提出了一种基于学习进度的自动课程强化学习(LP-ACRL)框架,该框架在线估计智能体的学习进度,并自适应地调整任务采样分布,从而在无需事先了解任务空间难度分布的情况下实现自动课程生成。使用LP-ACRL训练的策略使ANYmal D四足机器人能够在包括楼梯、斜坡、碎石和低摩擦平面等多种地形上实现并保持稳定、高速的运动,达到2.5米/秒的线速度和3.0弧度/秒的角速度——而先前的方法通常仅限于在平坦地形上的高速运动或在复杂地形上的低速运动。实验结果表明,LP-ACRL具有很强的可扩展性和实际应用性,为未来在复杂、广泛的机器人学习任务空间中进行课程生成的研究提供了一个强大的基线。
🔬 方法详解
问题定义:论文旨在解决四足机器人在复杂地形上高速稳定运动的难题。现有方法要么只能在平坦地形上实现高速运动,要么在复杂地形上速度很低。核心痛点在于,传统的课程学习方法需要预先定义任务的难度排序,但在复杂地形下,任务难度难以明确定义和量化。
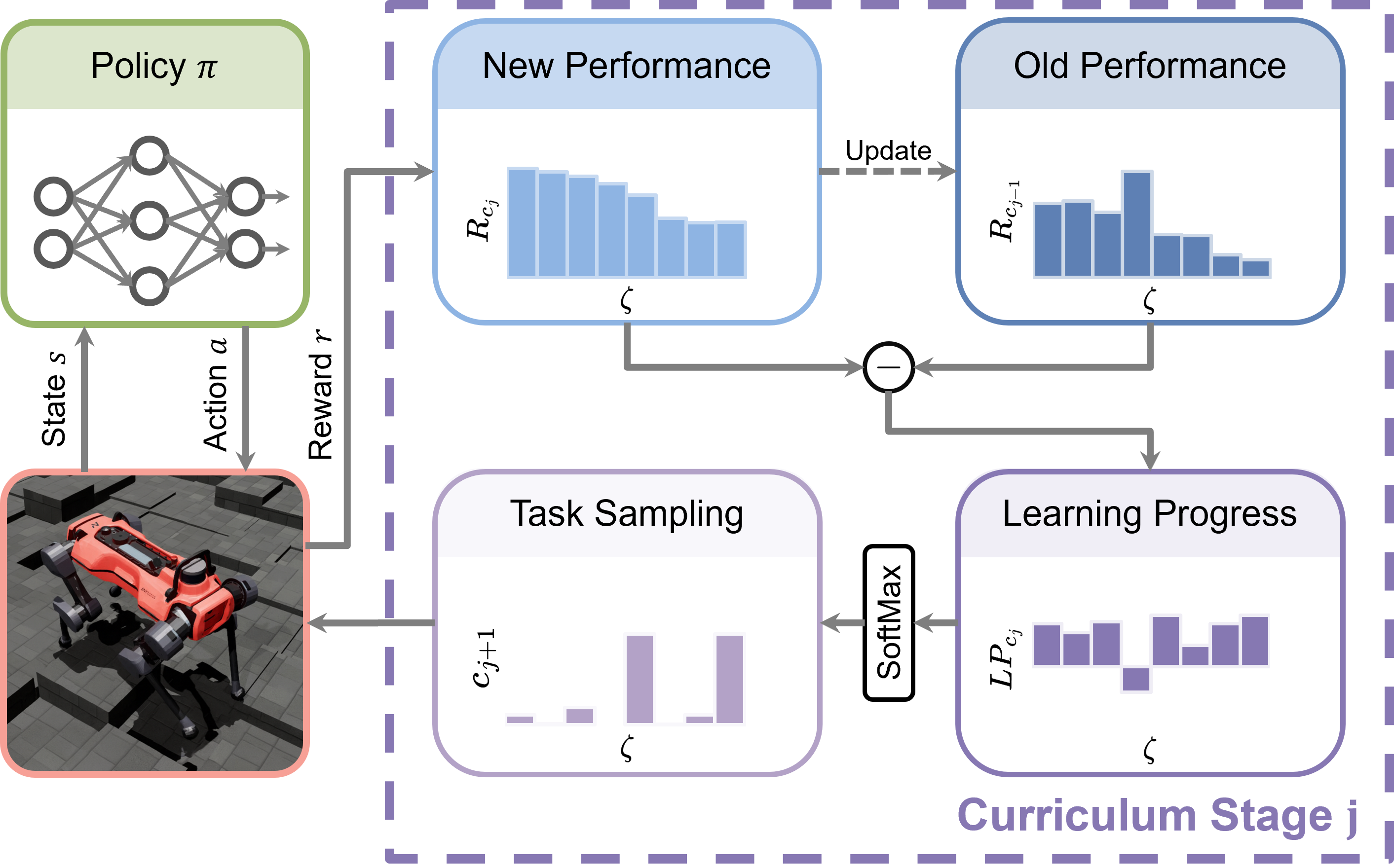
核心思路:论文的核心思路是利用强化学习,并结合自动课程学习的思想,让机器人自己探索和学习。关键在于,不预先定义任务难度,而是根据机器人自身的学习进度,动态调整训练任务的采样分布。如果机器人学习进度快,就增加难度;如果学习进度慢,就降低难度。
技术框架:LP-ACRL框架主要包含以下几个模块:1) 强化学习智能体,负责学习运动控制策略;2) 环境模拟器,提供各种复杂地形环境;3) 学习进度估计器,用于在线评估智能体的学习效果;4) 任务采样器,根据学习进度动态调整任务采样分布。整体流程是:智能体在模拟环境中与环境交互,学习进度估计器评估学习效果,任务采样器根据学习进度调整下一轮训练的任务,如此循环迭代。
关键创新:最重要的创新点在于提出了基于学习进度的自动课程生成方法。与传统方法需要人工定义难度排序不同,LP-ACRL能够根据智能体的实际学习情况,自动调整训练任务的难度,从而更有效地引导智能体学习。这种方法避免了人工干预,更具通用性和可扩展性。
关键设计:论文中,学习进度估计器通过计算智能体在一段时间内的奖励变化来评估学习效果。任务采样器使用一个概率分布来表示不同任务的采样概率,并根据学习进度动态调整这个分布。具体来说,如果智能体在某个任务上的学习进度快,就降低该任务的采样概率;反之,则增加采样概率。损失函数采用标准的强化学习损失函数,例如PPO或SAC。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LP-ACRL能够使ANYmal D四足机器人在多种复杂地形上实现稳定、高速的运动,达到2.5米/秒的线速度和3.0弧度/秒的角速度。相比于传统方法,LP-ACRL在复杂地形上的运动速度和稳定性都有显著提升。此外,实验还验证了LP-ACRL具有良好的可扩展性,能够适应不同的地形环境。
🎯 应用场景
该研究成果可广泛应用于搜救机器人、巡检机器人、物流机器人等领域。通过提升机器人在复杂地形下的运动能力,可以使其更好地完成各种任务,例如在灾难现场进行搜救、在复杂环境中进行巡检、在崎岖地形上进行物流配送等。该研究也为其他机器人学习任务的课程生成提供了新的思路。
📄 摘要(原文)
Curriculum learning has demonstrated substantial effectiveness in robot learning. However, it still faces limitations when scaling to complex, wide-ranging task spaces. Such task spaces often lack a well-defined difficulty structure, making the difficulty ordering required by previous methods challenging to define. We propose a Learning Progress-based Automatic Curriculum Reinforcement Learning (LP-ACRL) framework, which estimates the agent's learning progress online and adaptively adjusts the task-sampling distribution, thereby enabling automatic curriculum generation without prior knowledge of the difficulty distribution over the task space. Policies trained with LP-ACRL enable the ANYmal D quadruped to achieve and maintain stable, high-speed locomotion at 2.5 m/s linear velocity and 3.0 rad/s angular velocity across diverse terrains, including stairs, slopes, gravel, and low-friction flat surfaces--whereas previous methods have generally been limited to high speeds on flat terrain or low speeds on complex terrain. Experimental results demonstrate that LP-ACRL exhibits strong scalability and real-world applicability, providing a robust baseline for future research on curriculum generation in complex, wide-ranging robotic learning task spaces.