Sim-to-Real Transfer via a Style-Identified Cycle Consistent Generative Adversarial Network: Zero-Shot Deployment on Robotic Manipulators through Visual Domain Adaptation
作者: Lucía Güitta-López, Lionel Güitta-López, Jaime Boal, Álvaro Jesús López-López
分类: cs.RO, cs.AI
发布日期: 2026-01-23
期刊: Engineering Applications of Artificial Intelligence, volume 159, published Jan.2026
DOI: 10.1016/j.engappai.2025.111510
💡 一句话要点
提出基于StyleID-CycleGAN的Sim-to-Real迁移方法,实现机器人操作的零样本部署。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Sim-to-Real 领域自适应 生成对抗网络 强化学习 机器人操作
📋 核心要点
- 真实环境训练DRL智能体成本高、耗时,而虚拟环境训练存在Sim-to-Real差距,导致策略难以迁移。
- 提出StyleID-CycleGAN,将虚拟观测转换为真实合成图像,构建混合域训练DRL智能体,实现零样本迁移。
- 实验表明,该方法在机器人抓取任务中实现了95%以上的准确率,并成功泛化到不同颜色和形状的真实物体。
📝 摘要(中文)
深度强化学习(DRL)中的样本效率问题限制了其在工业领域的应用,因为真实环境训练成本高昂且耗时。虚拟环境为训练DRL智能体提供了一种经济高效的替代方案,但学习到的策略向真实环境的迁移受到Sim-to-Real差距的阻碍。零样本迁移,即智能体无需额外调整即可直接在真实环境中执行,因其效率和实用价值而备受青睐。本文提出了一种新颖的领域自适应方法,该方法依赖于风格识别循环一致生成对抗网络(StyleID-CycleGAN或SICGAN),这是一种基于原始循环一致生成对抗网络(CycleGAN)的模型。SICGAN将原始虚拟观测转换为真实合成图像,从而创建一个混合域,用于训练DRL智能体,该混合域将虚拟动力学与类真实的视觉输入相结合。经过虚拟训练后,智能体可以直接部署,无需在真实环境中进行额外训练。该流程通过两个不同的工业机器人在抓取操作的接近阶段进行了验证。在虚拟环境中,智能体实现了90%到100%的成功率,而真实环境部署证实了鲁棒的零样本迁移(即,无需在物理环境中进行额外训练),在大多数工作空间区域的准确率高于95%。我们使用增强现实目标来提高评估过程的效率,并通过实验证明,智能体成功地泛化到各种颜色和形状的真实物体,包括乐高积木和一个马克杯。这些结果表明,所提出的流程是一种高效、可扩展的Sim-to-Real问题解决方案。
🔬 方法详解
问题定义:论文旨在解决深度强化学习中,策略从仿真环境迁移到真实机器人环境时遇到的Sim-to-Real问题。现有方法通常需要大量的真实数据进行微调,成本高昂且耗时。零样本迁移是理想目标,但由于仿真环境与真实环境的视觉差异,直接迁移效果往往不佳。
核心思路:论文的核心思路是利用领域自适应技术,将仿真环境的图像风格转换为接近真实环境的风格,从而减小视觉差异。通过在风格转换后的图像上训练强化学习智能体,使其能够更好地适应真实环境,实现零样本迁移。
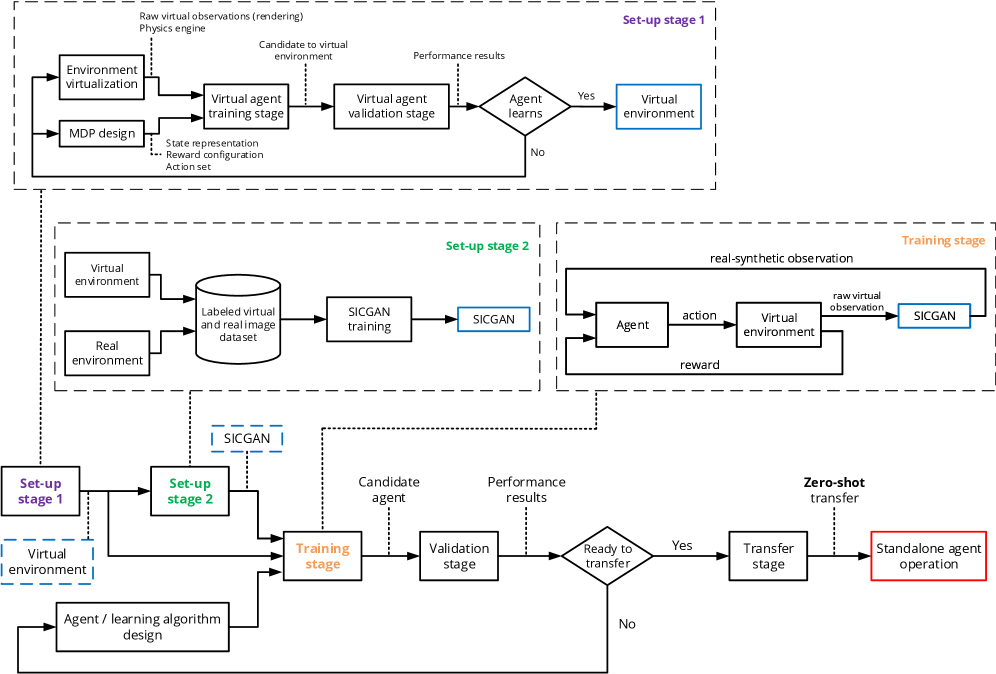
技术框架:整体框架包含三个主要部分:仿真环境、StyleID-CycleGAN和强化学习智能体。首先,在仿真环境中生成大量的图像数据。然后,使用StyleID-CycleGAN将仿真图像转换为真实风格的合成图像。最后,在混合域(仿真动力学+真实风格图像)上训练强化学习智能体。训练完成后,直接将智能体部署到真实机器人环境中。
关键创新:论文的关键创新在于提出了StyleID-CycleGAN,这是一种改进的CycleGAN,能够更好地进行风格迁移。与传统的CycleGAN相比,StyleID-CycleGAN能够更好地保留图像的内容信息,同时实现更逼真的风格转换。此外,论文还探索了如何将风格迁移与强化学习相结合,实现高效的Sim-to-Real迁移。
关键设计:StyleID-CycleGAN的关键设计包括:(1) 使用循环一致性损失来保证图像内容的一致性;(2) 使用风格损失来促使生成图像具有真实环境的风格;(3) 使用身份映射损失来保留图像的原始结构信息。强化学习智能体使用DDPG算法进行训练,奖励函数根据任务目标进行设计,例如,接近目标物体。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用StyleID-CycleGAN进行Sim-to-Real迁移后,机器人在真实环境中的抓取成功率达到95%以上,实现了鲁棒的零样本迁移。与直接在仿真环境中训练的智能体相比,该方法的性能显著提升。此外,实验还证明了该方法具有良好的泛化能力,可以成功处理不同颜色和形状的物体。
🎯 应用场景
该研究成果可广泛应用于机器人自动化领域,尤其是在需要快速部署和低成本维护的场景中。例如,在工业生产线上,机器人可以快速适应新的产品类型,而无需进行大量的真实数据训练。此外,该方法还可以应用于自动驾驶、无人机等领域,提高智能体在复杂环境中的适应能力。
📄 摘要(原文)
The sample efficiency challenge in Deep Reinforcement Learning (DRL) compromises its industrial adoption due to the high cost and time demands of real-world training. Virtual environments offer a cost-effective alternative for training DRL agents, but the transfer of learned policies to real setups is hindered by the sim-to-real gap. Achieving zero-shot transfer, where agents perform directly in real environments without additional tuning, is particularly desirable for its efficiency and practical value. This work proposes a novel domain adaptation approach relying on a Style-Identified Cycle Consistent Generative Adversarial Network (StyleID-CycleGAN or SICGAN), an original Cycle Consistent Generative Adversarial Network (CycleGAN) based model. SICGAN translates raw virtual observations into real-synthetic images, creating a hybrid domain for training DRL agents that combines virtual dynamics with real-like visual inputs. Following virtual training, the agent can be directly deployed, bypassing the need for real-world training. The pipeline is validated with two distinct industrial robots in the approaching phase of a pick-and-place operation. In virtual environments agents achieve success rates of 90 to 100\%, and real-world deployment confirms robust zero-shot transfer (i.e., without additional training in the physical environment) with accuracies above 95\% for most workspace regions. We use augmented reality targets to improve the evaluation process efficiency, and experimentally demonstrate that the agent successfully generalizes to real objects of varying colors and shapes, including LEGO\textsuperscript{\textregistered}~cubes and a mug. These results establish the proposed pipeline as an efficient, scalable solution to the sim-to-real problem.