ReViP: Reducing False Completion in Vision-Language-Action Models with Vision-Proprioception Rebalance
作者: Zhuohao Li, Yinghao Li, Jian-Jian Jiang, Lang Zhou, Tianyu Zhang, Wei-Shi Zheng
分类: cs.RO, cs.CV
发布日期: 2026-01-23
💡 一句话要点
ReViP:通过视觉-本体感受重平衡减少VLA模型中的虚假完成
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 模态融合 本体感受 视觉重平衡 虚假完成 环境感知
📋 核心要点
- 现有VLA模型融合视觉、语言和本体感受信息时,存在本体感受主导的偏差,导致即使视觉上失败也会错误地完成任务。
- ReViP通过引入任务感知的环境先验,自适应地调节视觉和本体感受之间的耦合,从而增强视觉信息的利用。
- 实验表明,ReViP在虚假完成率和成功率方面优于现有VLA模型,并在多个基准测试和真实世界环境中验证了其有效性。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通过结合视觉、语言和本体感受来预测动作,从而推动了机器人操作的发展。然而,先前的方法直接将本体感受信号与VLM编码的视觉-语言特征融合,导致状态主导的偏差和虚假完成,即使执行失败是可见的。我们将其归因于模态不平衡,即策略过度依赖内部状态,而低估了视觉证据。为了解决这个问题,我们提出了ReViP,一种具有视觉-本体感受重平衡的新型VLA框架,以增强视觉基础和在扰动下的鲁棒性。关键在于引入辅助的、任务感知的环境先验,以自适应地调节语义感知和本体感受动力学之间的耦合。具体来说,我们使用外部VLM作为任务阶段观察器,从视觉观察中提取实时的、以任务为中心的视觉线索,这些线索驱动视觉-本体感受特征式线性调制,以增强环境感知并减少状态驱动的错误。此外,为了评估虚假完成,我们提出了第一个基于LIBERO的虚假完成基准测试套件,其中包含对象掉落等受控设置。大量实验表明,ReViP有效地降低了虚假完成率,并在我们的套件上提高了相对于强大的VLA基线的成功率,并且收益扩展到LIBERO、RoboTwin 2.0和真实世界的评估。
🔬 方法详解
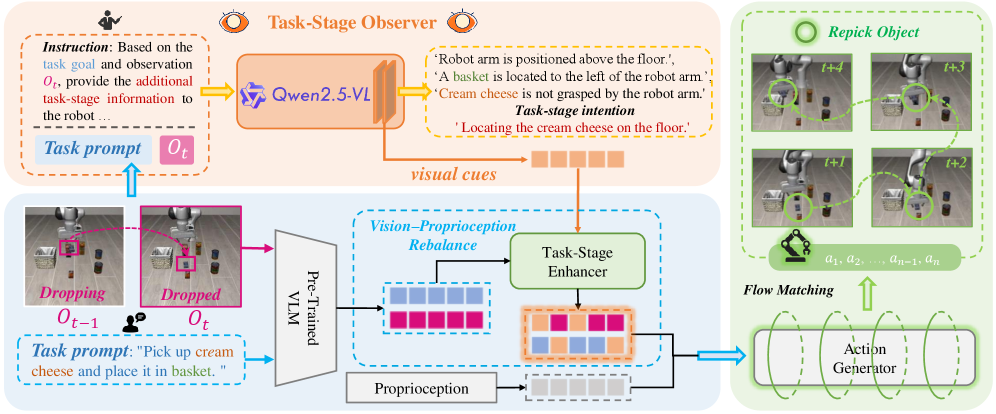
问题定义:现有VLA模型在机器人操作任务中,过度依赖本体感受信息(如关节角度、速度等),而忽略视觉信息,导致即使视觉上已经失败(例如物体掉落),模型仍然会输出完成任务的动作,即“虚假完成”。这种现象降低了模型的鲁棒性和可靠性。
核心思路:ReViP的核心思路是通过重新平衡视觉和本体感受信息的重要性,使模型更多地关注视觉证据,减少对内部状态的过度依赖。具体来说,利用外部VLM提取任务相关的视觉线索,并用这些线索来调节本体感受特征,从而增强环境感知能力。
技术框架:ReViP框架包含以下主要模块:1) 视觉输入模块:接收视觉观察;2) 语言输入模块:接收任务指令;3) 本体感受输入模块:接收机器人自身的运动状态信息;4) 任务阶段观察器:使用外部VLM从视觉观察中提取任务相关的视觉线索;5) 视觉-本体感受特征式线性调制(ViP-FiLM):利用任务阶段观察器提取的视觉线索,对本体感受特征进行调制,增强环境感知;6) 动作预测模块:根据融合后的视觉和本体感受特征,预测下一步的动作。
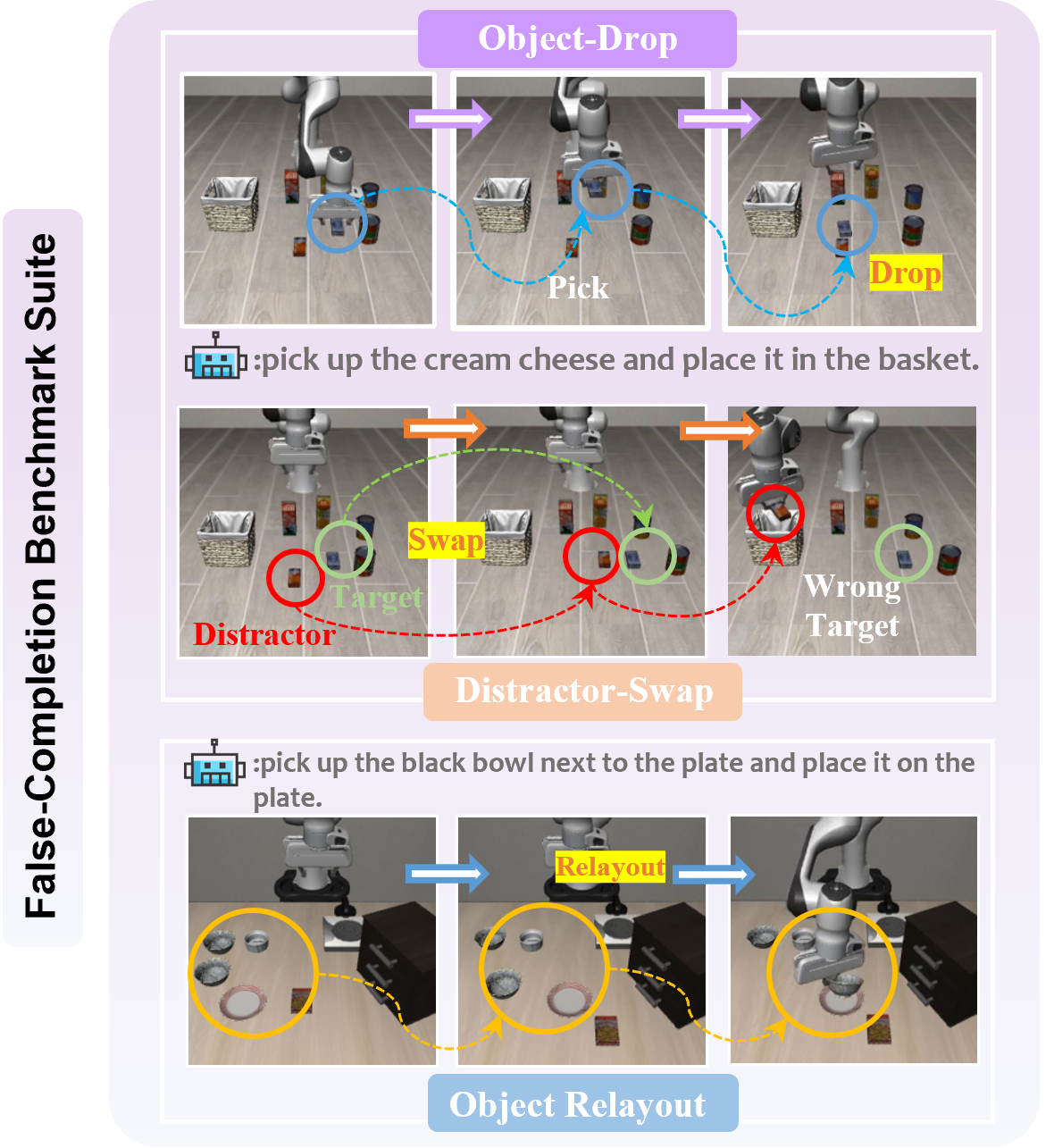
关键创新:ReViP的关键创新在于引入了视觉-本体感受重平衡机制,通过任务感知的视觉线索来调节本体感受特征。这与现有方法直接融合视觉和本体感受特征的方式不同,能够更有效地利用视觉信息,减少状态驱动的错误。此外,提出了False-Completion Benchmark Suite,用于评估模型在虚假完成方面的性能。
关键设计:ViP-FiLM模块是ReViP的关键组成部分。它使用任务阶段观察器提取的视觉特征,通过线性变换生成调制参数(scale和bias),然后利用这些参数对本体感受特征进行逐特征的缩放和平移。这种方式能够自适应地调整本体感受特征的表示,使其更加关注与当前任务相关的视觉信息。任务阶段观察器使用预训练的VLM,例如CLIP,以提取高质量的视觉特征。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ReViP在False-Completion Benchmark Suite上显著降低了虚假完成率,并提高了任务成功率。例如,在Object-Drop场景中,ReViP相对于基线方法,虚假完成率降低了15%以上,成功率提高了10%以上。此外,ReViP在LIBERO、RoboTwin 2.0和真实世界环境中也取得了显著的性能提升。
🎯 应用场景
ReViP的研究成果可以广泛应用于各种机器人操作任务中,例如装配、抓取、放置等。通过提高机器人对环境变化的鲁棒性和可靠性,可以减少人为干预,提高自动化水平。该技术在工业自动化、家庭服务机器人、医疗机器人等领域具有重要的应用价值和潜力。
📄 摘要(原文)
Vision-Language-Action (VLA) models have advanced robotic manipulation by combining vision, language, and proprioception to predict actions. However, previous methods fuse proprioceptive signals directly with VLM-encoded vision-language features, resulting in state-dominant bias and false completions despite visible execution failures. We attribute this to modality imbalance, where policies over-rely on internal state while underusing visual evidence. To address this, we present ReViP, a novel VLA framework with Vision-Proprioception Rebalance to enhance visual grounding and robustness under perturbations. The key insight is to introduce auxiliary task-aware environment priors to adaptively modulate the coupling between semantic perception and proprioceptive dynamics. Specifically, we use an external VLM as a task-stage observer to extract real-time task-centric visual cues from visual observations, which drive a Vision-Proprioception Feature-wise Linear Modulation to enhance environmental awareness and reduce state-driven errors. Moreover, to evaluate false completion, we propose the first False-Completion Benchmark Suite built on LIBERO with controlled settings such as Object-Drop. Extensive experiments show that ReViP effectively reduces false-completion rates and improves success rates over strong VLA baselines on our suite, with gains extending to LIBERO, RoboTwin 2.0, and real-world evaluations.