IVRA: Improving Visual-Token Relations for Robot Action Policy with Training-Free Hint-Based Guidance
作者: Jongwoo Park, Kanchana Ranasinghe, Jinhyeok Jang, Cristina Mata, Yoo Sung Jang, Michael S Ryoo
分类: cs.RO
发布日期: 2026-01-22
💡 一句话要点
IVRA:利用免训练提示引导,改善视觉Token关系,提升机器人动作策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人动作策略 视觉语言动作模型 空间关系理解 免训练方法 亲和力提示
📋 核心要点
- 现有VLA模型将图像展平为1D token序列,丢失了重要的2D空间信息,影响了机器人操作的精度。
- IVRA利用模型内置视觉编码器中的亲和力提示,无需额外训练,即可在推理时改善视觉token间的关系。
- 实验表明,IVRA在多种VLA架构和机器人任务中均能提升性能,例如在LIBERO上最高提升至97.1%。
📝 摘要(中文)
许多视觉-语言-动作(VLA)模型将图像块展平为一维token序列,削弱了精确操作所需的二维空间线索。我们提出了IVRA,一种轻量级的、免训练的方法,通过利用模型内置视觉编码器中已有的亲和力提示来改善空间理解,而无需任何外部编码器或重新训练。IVRA选择性地将这些亲和力信号注入到实例级特征所在的语言模型层中。这种推理时的干预重新调整了视觉token的交互,更好地保留了几何结构,同时保持所有模型参数固定。我们通过将其应用于跨越2D和3D操作的模拟基准测试(VIMA和LIBERO)以及各种真实机器人任务中的不同VLA架构(LLaRA、OpenVLA和FLOWER),证明了IVRA的通用性。在2D VIMA上,在低数据情况下,IVRA比基线LLaRA的平均成功率提高了+4.2%。在3D LIBERO上,它在OpenVLA和FLOWER基线上产生了持续的收益,包括基线精度接近饱和时(96.3%到97.1%)的改进。所有代码和模型将公开发布。
🔬 方法详解
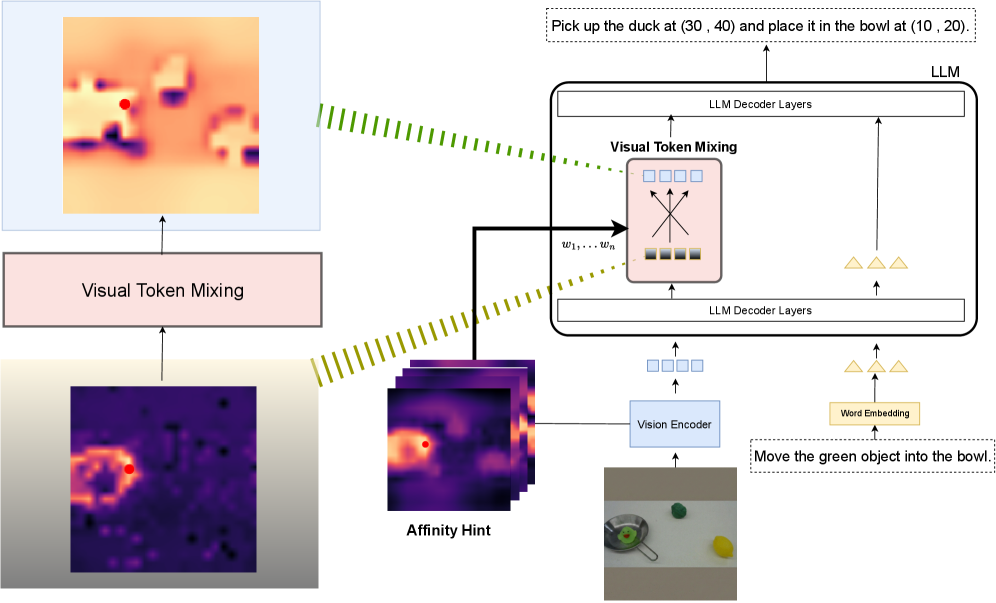
问题定义:现有的视觉-语言-动作(VLA)模型在处理图像输入时,通常会将图像分割成多个patch,然后将这些patch展平成一维的token序列。这种处理方式破坏了图像原有的二维空间结构信息,使得模型难以准确理解图像中物体之间的空间关系,从而影响机器人执行精确操作的能力。尤其是在需要精细操作的任务中,空间信息的缺失会显著降低模型的性能。
核心思路:IVRA的核心思路是利用视觉编码器中已经存在的亲和力(affinity)信息,来增强视觉token之间的空间关系。亲和力信息反映了图像中不同区域之间的相似程度,可以作为一种提示(hint)来引导模型更好地理解图像的几何结构。IVRA通过选择性地将这些亲和力信号注入到语言模型层中,从而在不改变模型参数的情况下,改善视觉token的交互方式,保留更多的几何结构信息。
技术框架:IVRA方法主要包含以下几个步骤:1) 从预训练的视觉编码器中提取视觉特征和亲和力矩阵。2) 选择一个合适的语言模型层,通常是实例级别的特征层。3) 将亲和力矩阵的信息注入到选定的语言模型层中,具体来说,就是利用亲和力矩阵来调整视觉token之间的交互权重。4) 使用调整后的视觉特征进行后续的语言理解和动作规划。整个过程在推理阶段进行,不需要重新训练模型。
关键创新:IVRA的关键创新在于它是一种免训练的、轻量级的空间信息增强方法。与需要重新训练或引入额外模块的方法不同,IVRA直接利用了现有模型中已经存在的亲和力信息,避免了额外的计算开销和数据需求。此外,IVRA的选择性注入机制可以有效地控制空间信息的引入,避免对模型原有功能的干扰。
关键设计:IVRA的关键设计包括:1) 亲和力矩阵的计算方式,通常可以使用注意力机制或相似度度量来计算。2) 注入位置的选择,需要选择一个能够有效融合视觉和语言信息的层。3) 注入方式的设计,可以使用加权平均、注意力机制等方式将亲和力信息融入到视觉特征中。论文中具体使用了何种参数设置和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
IVRA在多个机器人操作任务上取得了显著的性能提升。在2D VIMA任务中,IVRA在低数据情况下比基线LLaRA的平均成功率提高了4.2%。在3D LIBERO任务中,IVRA在OpenVLA和FLOWER基线上实现了持续的性能提升,甚至在基线精度接近饱和时(96.3%)也能提升至97.1%。这些结果表明,IVRA能够有效地改善视觉token之间的关系,提升机器人对空间信息的理解能力。
🎯 应用场景
IVRA具有广泛的应用前景,可应用于各种需要机器人进行精确操作的场景,例如:工业自动化中的零件装配、医疗手术中的微创操作、家庭服务中的物品整理等。通过提升机器人对空间信息的理解能力,IVRA可以显著提高机器人的操作精度和效率,降低操作风险,从而推动机器人技术在各个领域的应用。
📄 摘要(原文)
Many Vision-Language-Action (VLA) models flatten image patches into a 1D token sequence, weakening the 2D spatial cues needed for precise manipulation. We introduce IVRA, a lightweight, training-free method that improves spatial understanding by exploiting affinity hints already available in the model's built-in vision encoder, without requiring any external encoder or retraining. IVRA selectively injects these affinity signals into a language-model layer in which instance-level features reside. This inference-time intervention realigns visual-token interactions and better preserves geometric structure while keeping all model parameters fixed. We demonstrate the generality of IVRA by applying it to diverse VLA architectures (LLaRA, OpenVLA, and FLOWER) across simulated benchmarks spanning both 2D and 3D manipulation (VIMA and LIBERO) and on various real-robot tasks. On 2D VIMA, IVRA improves average success by +4.2% over the baseline LLaRA in a low-data regime. On 3D LIBERO, it yields consistent gains over the OpenVLA and FLOWER baselines, including improvements when baseline accuracy is near saturation (96.3% to 97.1%). All code and models will be released publicly. Visualizations are available at: jongwoopark7978.github.io/IVRA