Efficiently Learning Robust Torque-based Locomotion Through Reinforcement with Model-Based Supervision
作者: Yashuai Yan, Tobias Egle, Christian Ott, Dongheui Lee
分类: cs.RO
发布日期: 2026-01-22
💡 一句话要点
提出一种基于模型监督的强化学习方法,高效学习鲁棒的力矩控制双足运动。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双足机器人 强化学习 模型预测控制 领域随机化 残差学习 sim-to-real 运动控制
📋 核心要点
- 现有基于模型的双足运动控制方法难以应对真实世界动力学建模不准确和传感器噪声带来的不确定性。
- 提出一种结合模型预测控制和残差强化学习的框架,利用模型作为先验知识,强化学习进行误差补偿。
- 通过模型监督的强化学习,策略能够高效学习纠正行为,在随机环境中表现出更强的鲁棒性和泛化能力。
📝 摘要(中文)
本文提出了一种控制框架,该框架将基于模型的双足运动控制与残差强化学习(RL)相结合,以在真实世界的不确定性中实现鲁棒和自适应的行走。我们的方法利用基于模型的控制器(包括运动发散分量(DCM)轨迹规划器和全身控制器)作为可靠的基础策略。为了解决不准确的动力学建模和传感器噪声的不确定性,我们引入了一种通过领域随机化进行RL训练的残差策略。至关重要的是,我们采用了一种基于模型的Oracle策略,该策略在训练期间具有访问真实动力学的特权,通过一种新颖的监督损失来监督残差策略。这种监督使策略能够有效地学习纠正行为,以补偿未建模的影响,而无需进行广泛的奖励塑造。我们的方法展示了在各种随机条件下改进的鲁棒性和泛化能力,为双足运动中的sim-to-real迁移提供了一种可扩展的解决方案。
🔬 方法详解
问题定义:论文旨在解决双足机器人运动控制中,由于动力学模型不准确和传感器噪声等不确定性因素,导致传统基于模型的控制方法鲁棒性不足的问题。现有方法通常需要精细的动力学建模或复杂的奖励函数设计,难以实现sim-to-real的有效迁移。
核心思路:论文的核心思路是将基于模型的控制作为基础策略,并通过残差强化学习来学习对模型预测误差的补偿。利用一个具有ground-truth动力学信息的模型(Oracle Policy)来监督强化学习过程,从而加速学习并提高鲁棒性。
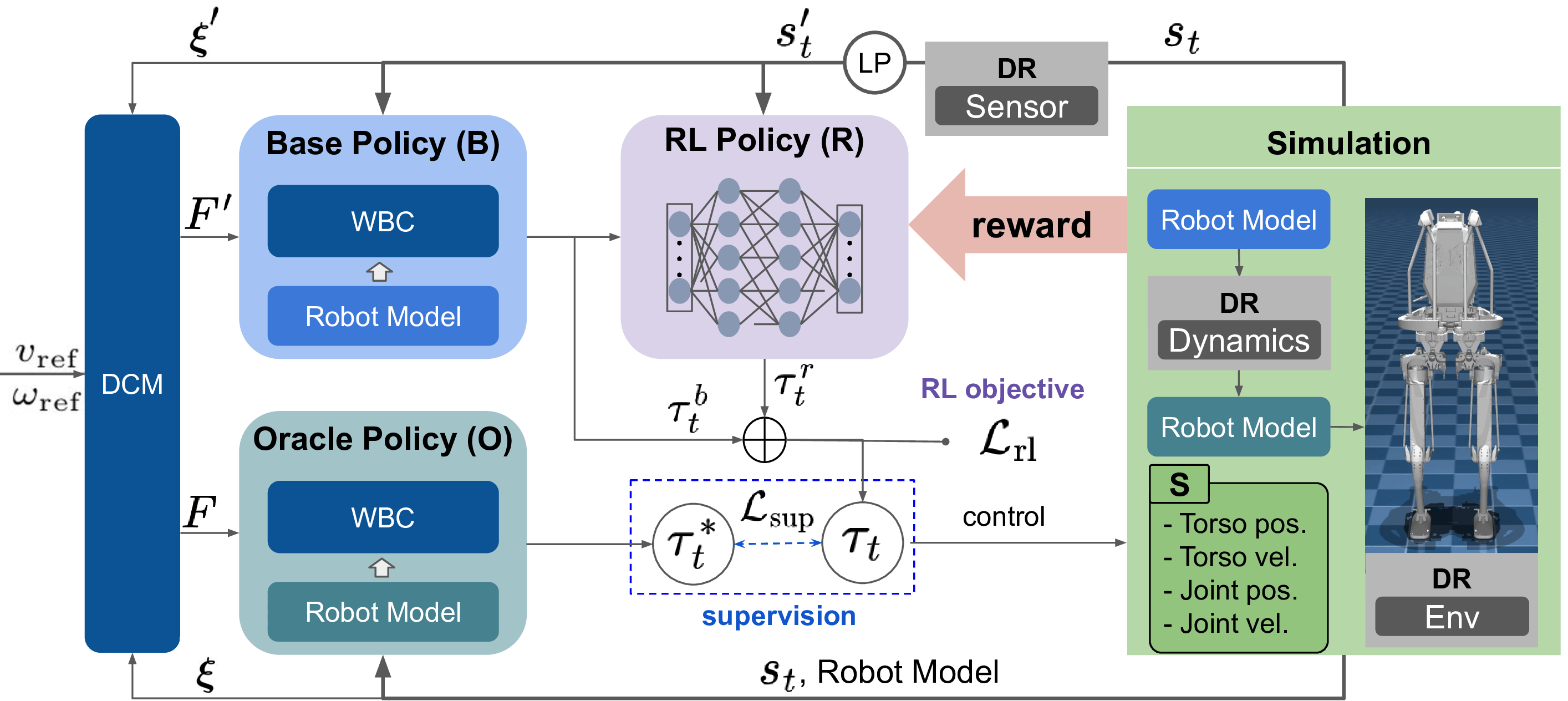
技术框架:整体框架包含三个主要模块:1) 基于模型的控制器,包括DCM轨迹规划器和全身控制器,提供基础运动控制;2) 残差强化学习策略,学习对模型预测误差的补偿;3) 模型监督模块,利用Oracle Policy提供的动作作为监督信号,指导残差策略的学习。训练过程中使用领域随机化来提高策略的泛化能力。
关键创新:最重要的创新点在于使用模型监督来指导残差强化学习。传统的强化学习需要精心设计的奖励函数,而模型监督可以直接利用Oracle Policy的动作作为目标,从而更有效地学习补偿策略。这种方法避免了复杂的奖励塑造,并加速了学习过程。
关键设计:关键设计包括:1) 领域随机化的参数范围,例如质量、摩擦力等;2) 残差策略的网络结构,通常是多层感知机;3) 监督损失函数,例如均方误差损失,用于衡量残差策略输出的动作与Oracle Policy输出的动作之间的差异;4) 强化学习算法的选择,例如PPO或SAC。
🖼️ 关键图片
📊 实验亮点
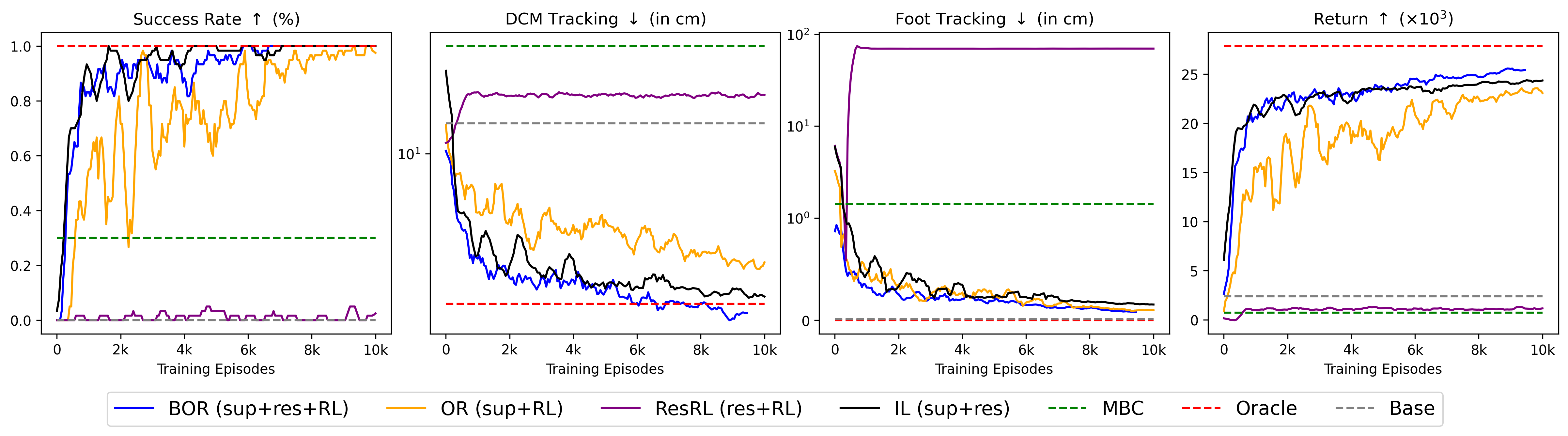
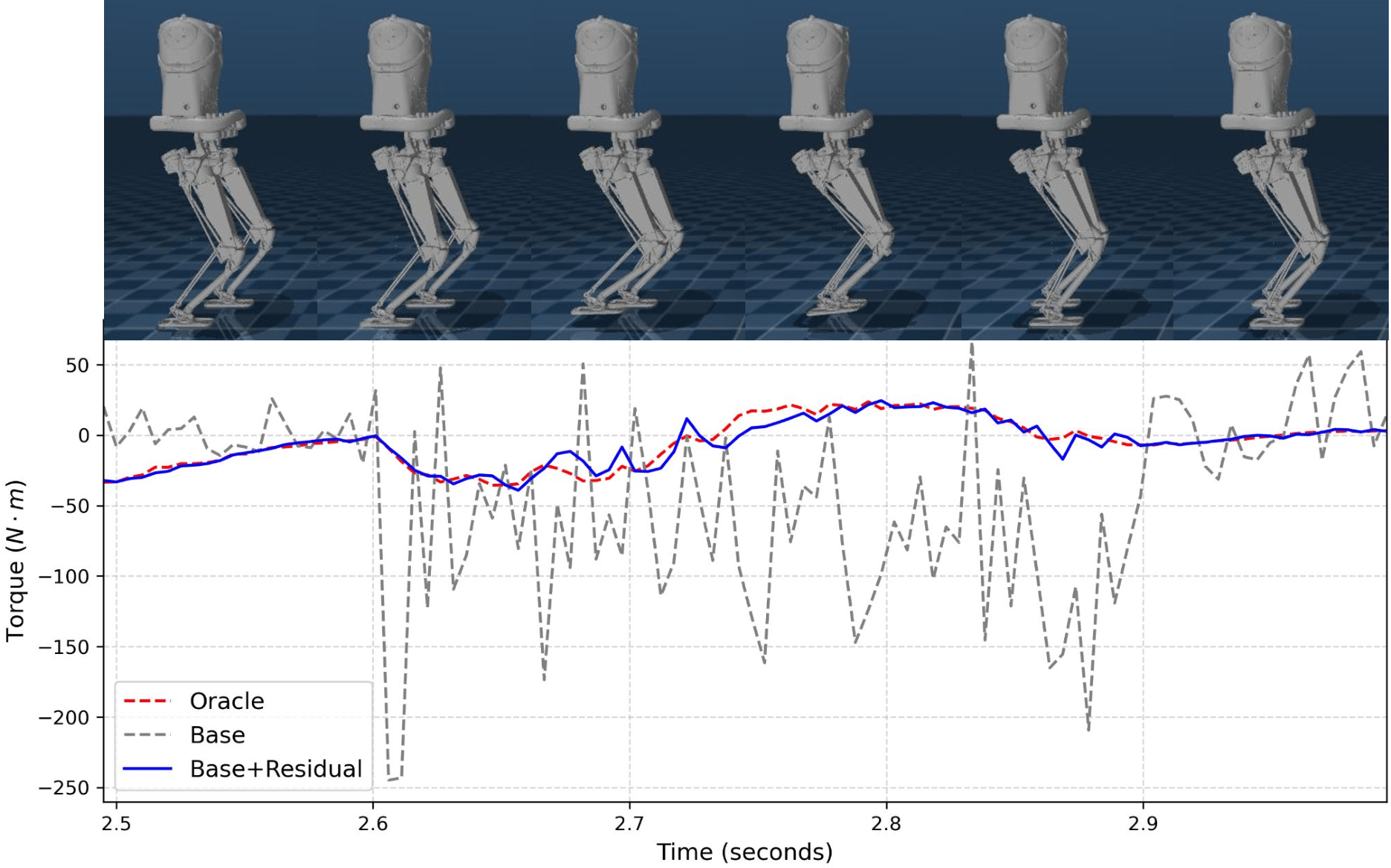
实验结果表明,该方法在各种随机条件下均表现出优异的鲁棒性和泛化能力。与传统的基于模型的控制方法相比,该方法能够显著提高双足机器人的行走稳定性,并减少跌倒的概率。此外,通过模型监督,强化学习的训练效率得到了显著提升,能够在更短的时间内学习到有效的补偿策略。具体性能数据未知,但摘要强调了“improved robustness and generalization”。
🎯 应用场景
该研究成果可应用于各种双足机器人,使其能够在复杂和不确定的环境中实现稳定和高效的行走。例如,可以应用于灾难救援机器人、家庭服务机器人和工业巡检机器人等,提高它们在真实世界中的适应性和可靠性。此外,该方法也可以推广到其他类型的机器人运动控制问题,例如四足机器人和人形机器人的运动控制。
📄 摘要(原文)
We propose a control framework that integrates model-based bipedal locomotion with residual reinforcement learning (RL) to achieve robust and adaptive walking in the presence of real-world uncertainties. Our approach leverages a model-based controller, comprising a Divergent Component of Motion (DCM) trajectory planner and a whole-body controller, as a reliable base policy. To address the uncertainties of inaccurate dynamics modeling and sensor noise, we introduce a residual policy trained through RL with domain randomization. Crucially, we employ a model-based oracle policy, which has privileged access to ground-truth dynamics during training, to supervise the residual policy via a novel supervised loss. This supervision enables the policy to efficiently learn corrective behaviors that compensate for unmodeled effects without extensive reward shaping. Our method demonstrates improved robustness and generalization across a range of randomized conditions, offering a scalable solution for sim-to-real transfer in bipedal locomotion.