DextER: Language-driven Dexterous Grasp Generation with Embodied Reasoning
作者: Junha Lee, Eunha Park, Minsu Cho
分类: cs.RO, cs.CV
发布日期: 2026-01-22
💡 一句话要点
DextER:提出基于具身推理的灵巧抓取生成方法,提升任务语义理解和物理交互能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 灵巧抓取 具身推理 语言驱动 机器人操作 接触预测
📋 核心要点
- 现有语言驱动的灵巧抓取生成方法缺乏对物理交互的中间推理,难以有效理解任务语义和物理约束。
- DextER通过预测手部与物体的接触点,建立具身感知的中间表示,从而连接任务语义和物理约束。
- 实验表明,DextER在抓取成功率和意图对齐方面均优于现有方法,并支持通过指定接触点进行可控生成。
📝 摘要(中文)
本文提出DextER,一种基于具身推理的灵巧抓取生成方法,旨在解决语言驱动的灵巧抓取生成问题。该问题需要模型理解任务语义、3D几何以及复杂的手-物交互。现有方法通常直接将观测映射到抓取参数,缺乏对物理交互的中间推理。DextER的核心思想是预测手部链接与物体表面的接触点,以此作为具身感知的中间表示,连接任务语义和物理约束。DextER自回归地生成具身接触令牌,指定哪些手指链接接触物体表面的哪些位置,然后生成编码手部配置的抓取令牌。在DexGYS数据集上,DextER的成功率为67.14%,超过了现有最佳方法3.83个百分点,意图对齐方面提升了96.4%。此外,DextER还支持通过部分接触规范进行可控生成,从而实现对抓取合成的精细控制。
🔬 方法详解
问题定义:论文旨在解决语言驱动的灵巧抓取生成问题。现有方法直接将视觉和语言信息映射到抓取参数,缺乏对物理交互过程的建模,导致难以理解任务语义和物理约束,生成的抓取质量不高。现有方法的痛点在于缺乏一个有效的中间表示来桥接任务语义和物理约束。
核心思路:论文的核心思路是引入基于接触的具身推理。具体来说,模型首先预测手部哪些链接与物体的哪些表面接触,将这些接触信息作为中间表示。这种表示方式能够显式地建模手与物体的物理交互,从而更好地理解任务语义和物理约束。通过预测接触点,模型可以更好地规划手部姿态,生成更稳定、更符合任务需求的抓取。
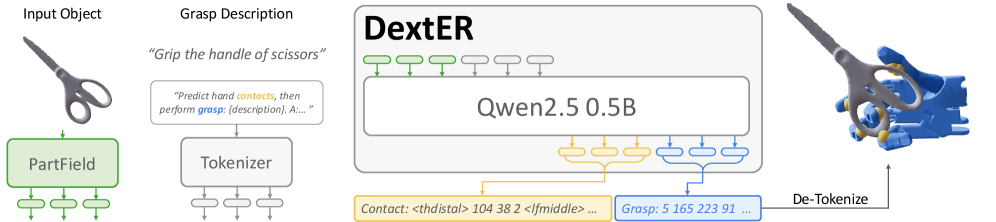
技术框架:DextER的整体框架是一个自回归生成模型,包含两个主要阶段:接触令牌生成和抓取令牌生成。首先,模型接收语言指令和物体3D模型作为输入,自回归地生成一系列接触令牌,每个令牌指定一个手部链接和一个物体表面点。然后,模型基于生成的接触令牌,自回归地生成一系列抓取令牌,每个令牌编码手部的一个关节角度或位置。这两个阶段通过Transformer架构实现,允许模型捕捉长程依赖关系。
关键创新:DextER最重要的创新点在于引入了基于接触的具身推理作为中间表示。与直接预测抓取参数的方法不同,DextER首先预测手部与物体的接触点,然后基于这些接触点生成抓取姿态。这种方法能够显式地建模手与物体的物理交互,从而更好地理解任务语义和物理约束。此外,DextER还支持通过指定部分接触点进行可控生成,从而实现对抓取合成的精细控制。
关键设计:DextER使用Transformer架构来实现接触令牌和抓取令牌的自回归生成。模型使用交叉注意力机制来融合语言指令和物体3D模型的信息。损失函数包括接触预测损失和抓取参数预测损失。接触预测损失采用交叉熵损失,抓取参数预测损失采用均方误差损失。为了提高生成的多样性,模型采用采样策略,例如top-k采样或nucleus采样。
🖼️ 关键图片

📊 实验亮点
DextER在DexGYS数据集上取得了显著的性能提升。具体来说,DextER的抓取成功率达到了67.14%,相比于现有最佳方法提升了3.83个百分点。此外,DextER在意图对齐方面也取得了显著的提升,达到了96.4%。实验结果表明,DextER能够更好地理解任务语义和物理约束,生成更稳定、更符合任务需求的抓取。
🎯 应用场景
DextER的研究成果可应用于机器人操作、自动化装配、虚拟现实等领域。例如,在机器人操作中,DextER可以帮助机器人理解人类的语言指令,并生成合适的抓取姿态来完成任务。在自动化装配中,DextER可以用于生成针对不同零件的抓取方案,提高装配效率。在虚拟现实中,DextER可以用于生成逼真的手部交互动画,提升用户体验。
📄 摘要(原文)
Language-driven dexterous grasp generation requires the models to understand task semantics, 3D geometry, and complex hand-object interactions. While vision-language models have been applied to this problem, existing approaches directly map observations to grasp parameters without intermediate reasoning about physical interactions. We present DextER, Dexterous Grasp Generation with Embodied Reasoning, which introduces contact-based embodied reasoning for multi-finger manipulation. Our key insight is that predicting which hand links contact where on the object surface provides an embodiment-aware intermediate representation bridging task semantics with physical constraints. DextER autoregressively generates embodied contact tokens specifying which finger links contact where on the object surface, followed by grasp tokens encoding the hand configuration. On DexGYS, DextER achieves 67.14% success rate, outperforming state-of-the-art by 3.83%p with 96.4% improvement in intention alignment. We also demonstrate steerable generation through partial contact specification, providing fine-grained control over grasp synthesis.