PUMA: Perception-driven Unified Foothold Prior for Mobility Augmented Quadruped Parkour
作者: Liang Wang, Kanzhong Yao, Yang Liu, Weikai Qin, Jun Wu, Zhe Sun, Qiuguo Zhu
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-01-22
💡 一句话要点
PUMA:感知驱动的统一落脚点先验,增强四足机器人跑酷的灵活性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 四足机器人 跑酷 视觉感知 落脚点先验 端到端学习
📋 核心要点
- 现有四足机器人跑酷方法依赖预计算落脚点,限制了实时适应性和强化学习的探索能力。
- PUMA框架通过视觉感知估计落脚点先验,引导机器人主动调整姿势,实现端到端学习。
- 实验表明,PUMA在复杂地形中展现出卓越的敏捷性和鲁棒性,验证了其有效性。
📝 摘要(中文)
四足机器人的跑酷任务已成为敏捷运动的一个有前景的基准。虽然人类运动员可以有效地感知环境特征,从而选择合适的落脚点来穿越障碍物,但赋予腿式机器人类似的感知推理能力仍然是一个巨大的挑战。现有的方法通常依赖于遵循预先计算的落脚点的分层控制器,从而限制了机器人的实时适应性和强化学习的探索潜力。为了克服这些挑战,我们提出了PUMA,一个端到端学习框架,它将视觉感知和落脚点先验集成到单阶段训练过程中。这种方法利用地形特征来估计以自我为中心的极坐标落脚点先验(由相对距离和航向组成),引导机器人在跑酷任务中进行主动姿势调整。在各种离散复杂地形的模拟和真实环境中进行的大量实验表明,PUMA在具有挑战性的场景中具有卓越的敏捷性和鲁棒性。
🔬 方法详解
问题定义:现有四足机器人跑酷方法主要依赖于预先计算的落脚点,并通过分层控制器执行。这种方法的痛点在于,机器人难以实时适应环境变化,并且限制了强化学习算法的探索能力,尤其是在复杂和动态的环境中。因此,如何使四足机器人能够像人类运动员一样,通过感知环境特征来选择合适的落脚点,是一个亟待解决的问题。
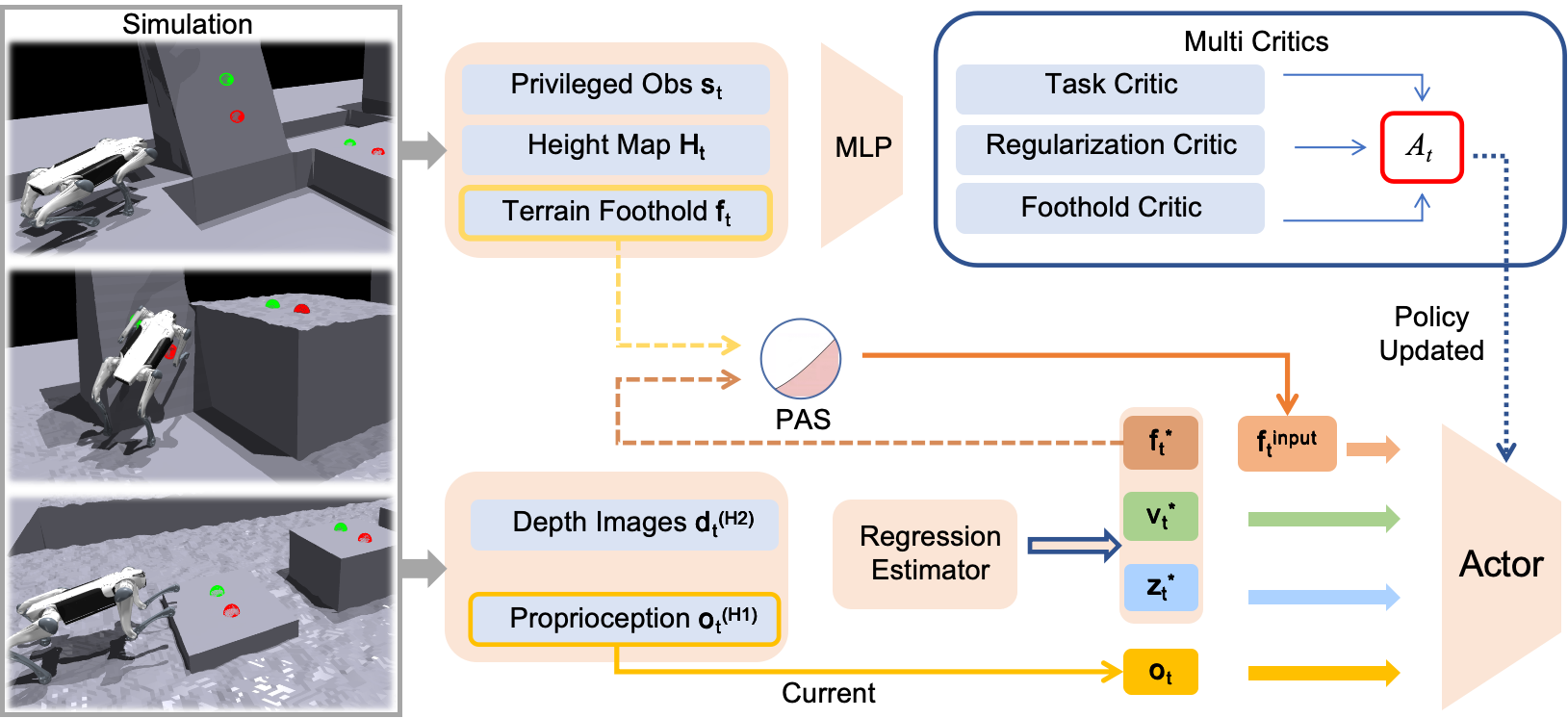
核心思路:PUMA的核心思路是将视觉感知和落脚点先验知识集成到一个端到端的学习框架中。通过视觉感知模块提取地形特征,并利用这些特征来估计以机器人为中心的极坐标落脚点先验,包括相对距离和航向。这些落脚点先验可以引导机器人在跑酷任务中进行主动的姿势调整,从而提高其适应性和灵活性。
技术框架:PUMA的整体框架是一个端到端的学习系统,主要包含以下几个模块:1) 视觉感知模块:用于提取地形特征;2) 落脚点先验估计模块:利用地形特征估计以自我为中心的极坐标落脚点先验;3) 运动控制模块:根据落脚点先验,控制机器人进行姿势调整和运动规划。整个系统通过单阶段训练过程进行优化,实现视觉感知、落脚点选择和运动控制的协同。
关键创新:PUMA最重要的创新点在于将视觉感知和落脚点先验集成到一个统一的端到端学习框架中。与现有方法相比,PUMA无需预先计算落脚点,而是通过视觉感知实时估计落脚点先验,从而提高了机器人的适应性和灵活性。此外,PUMA采用单阶段训练方式,避免了分层控制器的复杂性,简化了训练过程。
关键设计:PUMA的关键设计包括:1) 使用深度神经网络作为视觉感知模块,提取地形特征;2) 将落脚点先验表示为以机器人为中心的极坐标形式,方便进行运动规划;3) 设计合适的损失函数,鼓励机器人选择合适的落脚点,并进行稳定的姿势调整;4) 通过强化学习算法优化整个端到端系统,提高机器人在复杂环境中的表现。
🖼️ 关键图片
📊 实验亮点
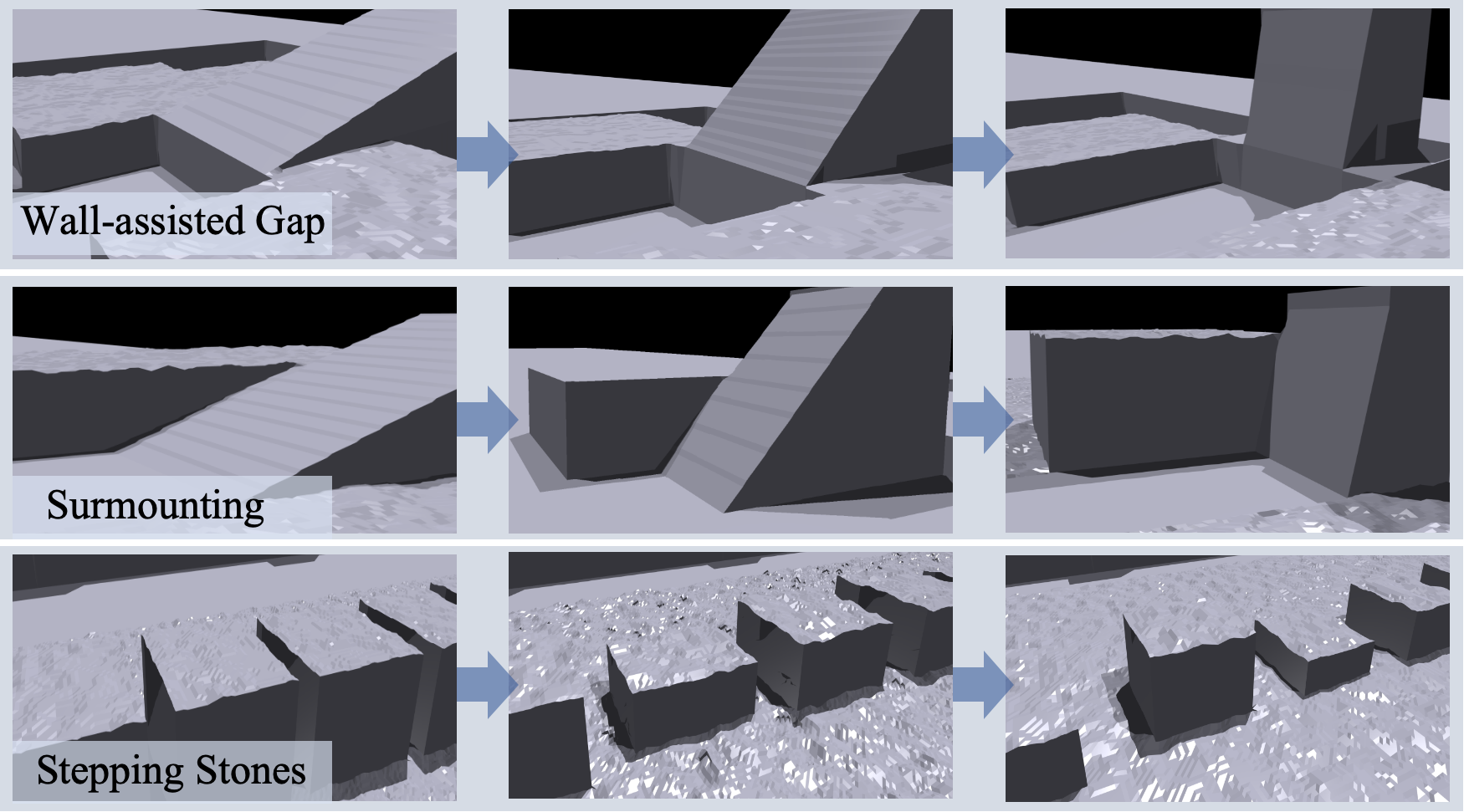
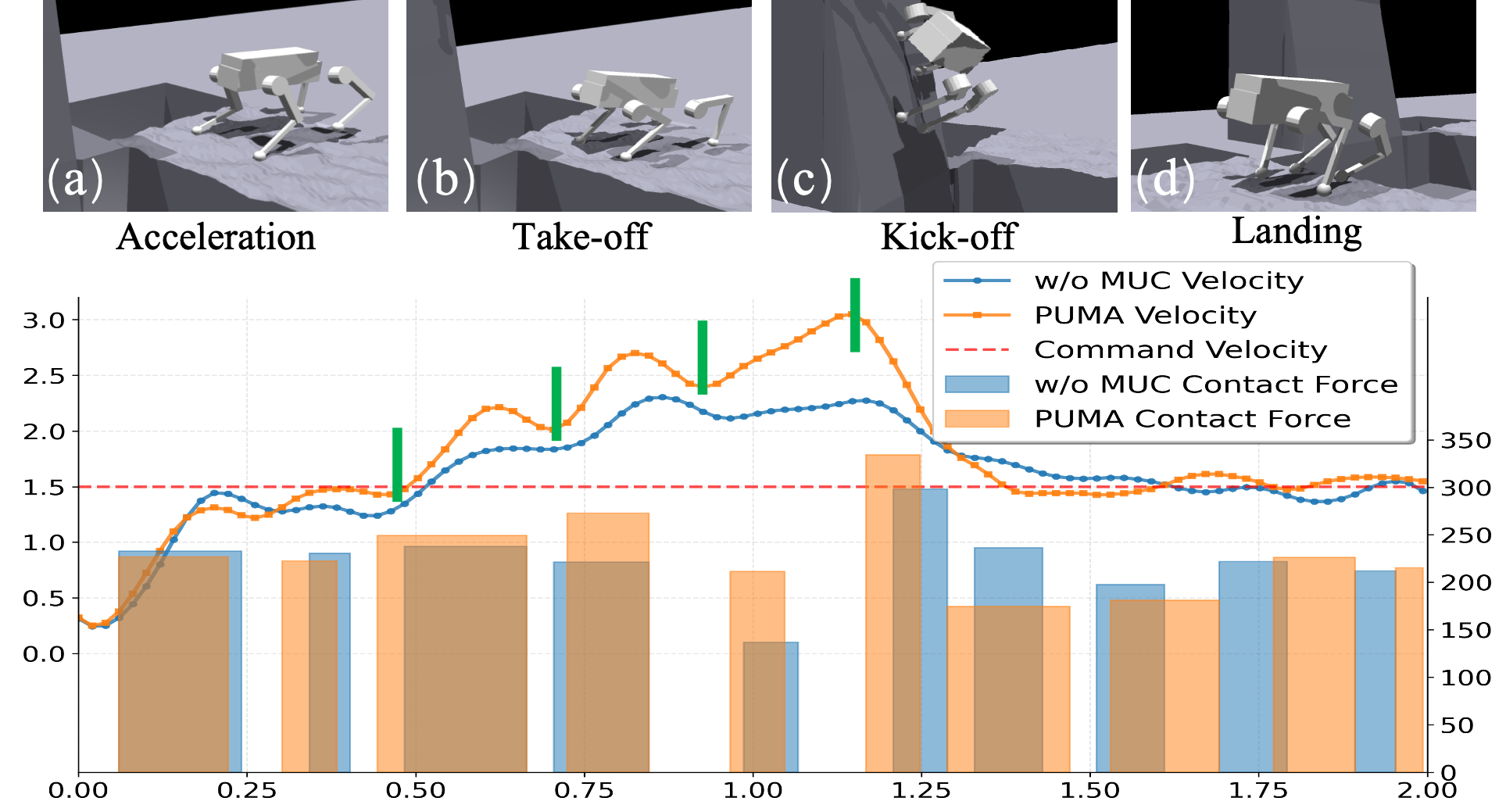
PUMA在模拟和真实环境中进行了大量实验,结果表明其在各种离散复杂地形中具有卓越的敏捷性和鲁棒性。相较于传统方法,PUMA能够更好地适应环境变化,并实现更灵活的运动控制。具体性能数据未知,但论文强调了PUMA在复杂场景下的显著优势。
🎯 应用场景
PUMA技术可应用于搜救、勘探、物流等领域,尤其是在复杂地形或灾害环境中。通过赋予四足机器人更强的环境感知和运动适应能力,可以使其在人类难以到达的区域执行任务,提高工作效率和安全性。未来,该技术有望进一步发展,实现更智能、更自主的四足机器人。
📄 摘要(原文)
Parkour tasks for quadrupeds have emerged as a promising benchmark for agile locomotion. While human athletes can effectively perceive environmental characteristics to select appropriate footholds for obstacle traversal, endowing legged robots with similar perceptual reasoning remains a significant challenge. Existing methods often rely on hierarchical controllers that follow pre-computed footholds, thereby constraining the robot's real-time adaptability and the exploratory potential of reinforcement learning. To overcome these challenges, we present PUMA, an end-to-end learning framework that integrates visual perception and foothold priors into a single-stage training process. This approach leverages terrain features to estimate egocentric polar foothold priors, composed of relative distance and heading, guiding the robot in active posture adaptation for parkour tasks. Extensive experiments conducted in simulation and real-world environments across various discrete complex terrains, demonstrate PUMA's exceptional agility and robustness in challenging scenarios.