D-Optimality-Guided Reinforcement Learning for Efficient Open-Loop Calibration of a 3-DOF Ankle Rehabilitation Robot
作者: Qifan Hu, Branko Celler, Weidong Mu, Steven W. Su
分类: cs.RO
发布日期: 2026-01-22
💡 一句话要点
提出基于D-最优性指导的强化学习方法,高效标定3自由度踝关节康复机器人。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 康复机器人 机器人标定 D-最优性 强化学习 近端策略优化
📋 核心要点
- 多自由度康复机器人需要精确对准,但现有方法效率低,难以在约束条件下选择最优姿态。
- 利用D-最优性准则指导强化学习,选择少量信息量最大的姿态组合,提高标定效率。
- 实验表明,PPO选择的姿态组合的信息矩阵行列式比随机选择高两个数量级,且预测一致性更强。
📝 摘要(中文)
为了安全有效地进行患者训练,多自由度康复机器人的精确对准至关重要。本文提出了一种用于自设计的3自由度踝关节康复机器人的两阶段标定框架。首先,开发了一种基于Kronecker积的开环标定方法,将输入-输出对准转化为线性参数识别问题,进而通过得到的信息矩阵定义相关的实验设计目标。在此基础上,标定姿态选择被建模为一个由D-最优性准则指导的组合实验设计问题,即选择最大化信息矩阵行列式的一小组姿态。为了在约束下实现实际选择,在仿真中训练了一个近端策略优化(PPO)智能体,从50个候选姿态集合中选择4个信息量最大的姿态。在仿真和真实机器人评估中,学习到的策略始终产生比随机选择信息量大得多的姿态组合:PPO实现的信息矩阵的平均行列式据报道高出两个数量级以上,且方差减小。此外,真实世界的结果表明,仅从四个D-最优性指导的姿态中识别出的参数向量比从较大但非结构化的50个姿态集合中获得的估计值提供更强的跨episode预测一致性。因此,所提出的框架提高了标定效率,同时保持了稳健的参数估计,为多自由度康复机器人的高精度对准提供了实际指导。
🔬 方法详解
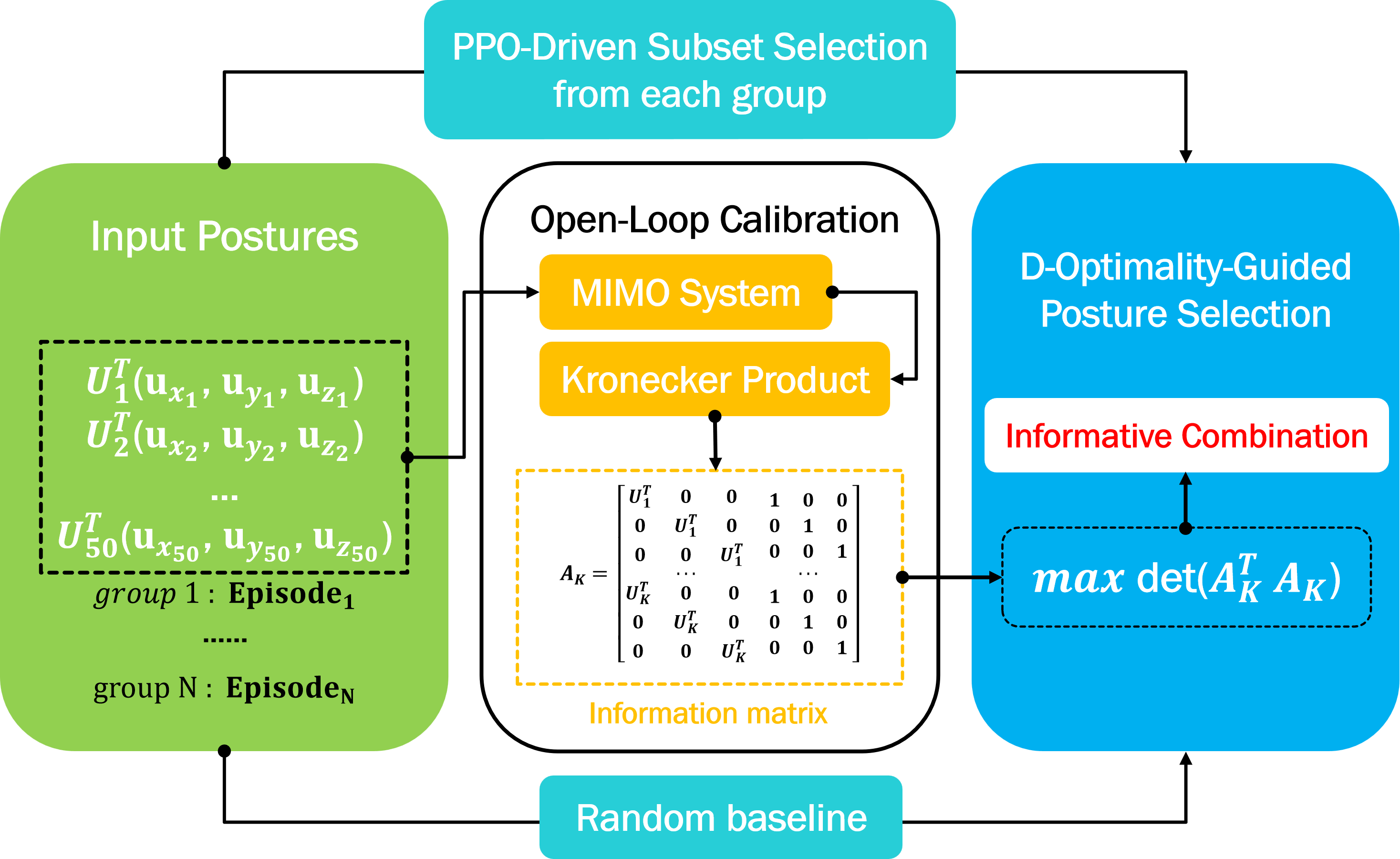
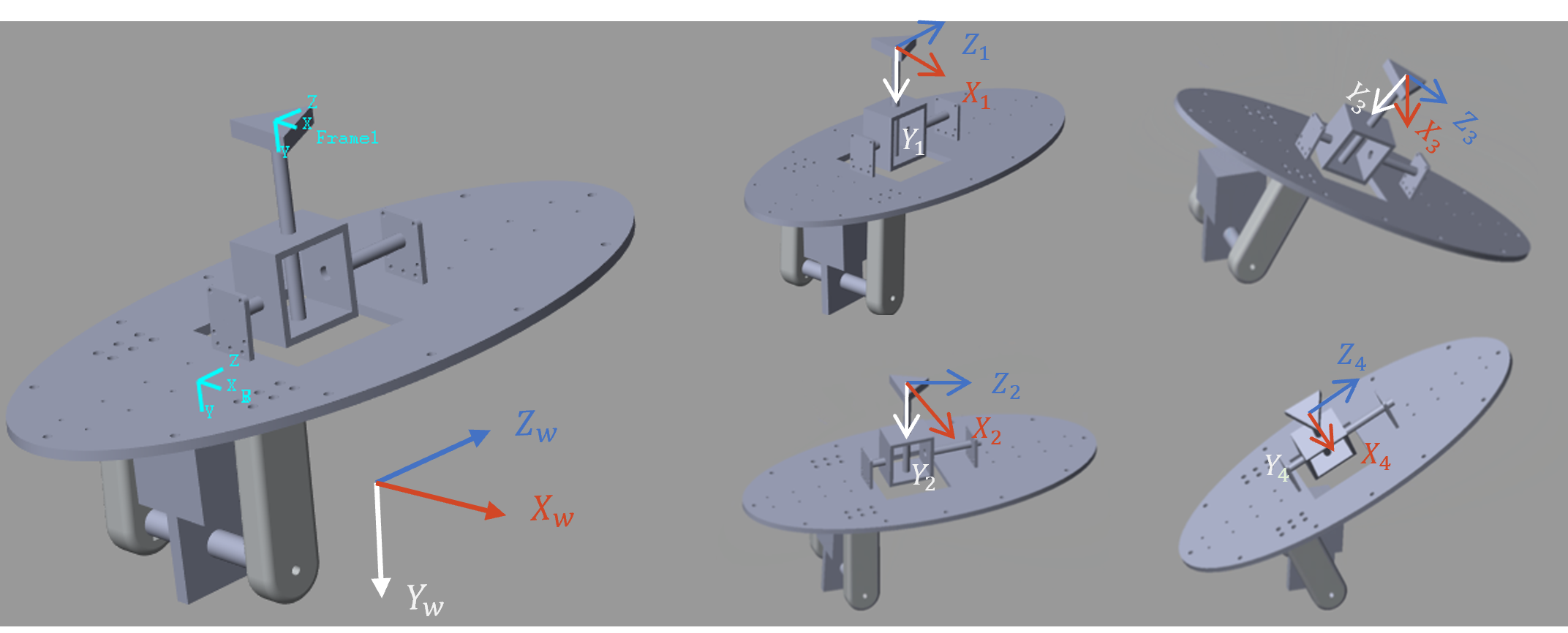
问题定义:论文旨在解决3自由度踝关节康复机器人的高效精确标定问题。现有标定方法通常需要大量的实验数据,效率低下,并且难以在实际约束条件下选择最优的姿态组合,导致标定精度受限。
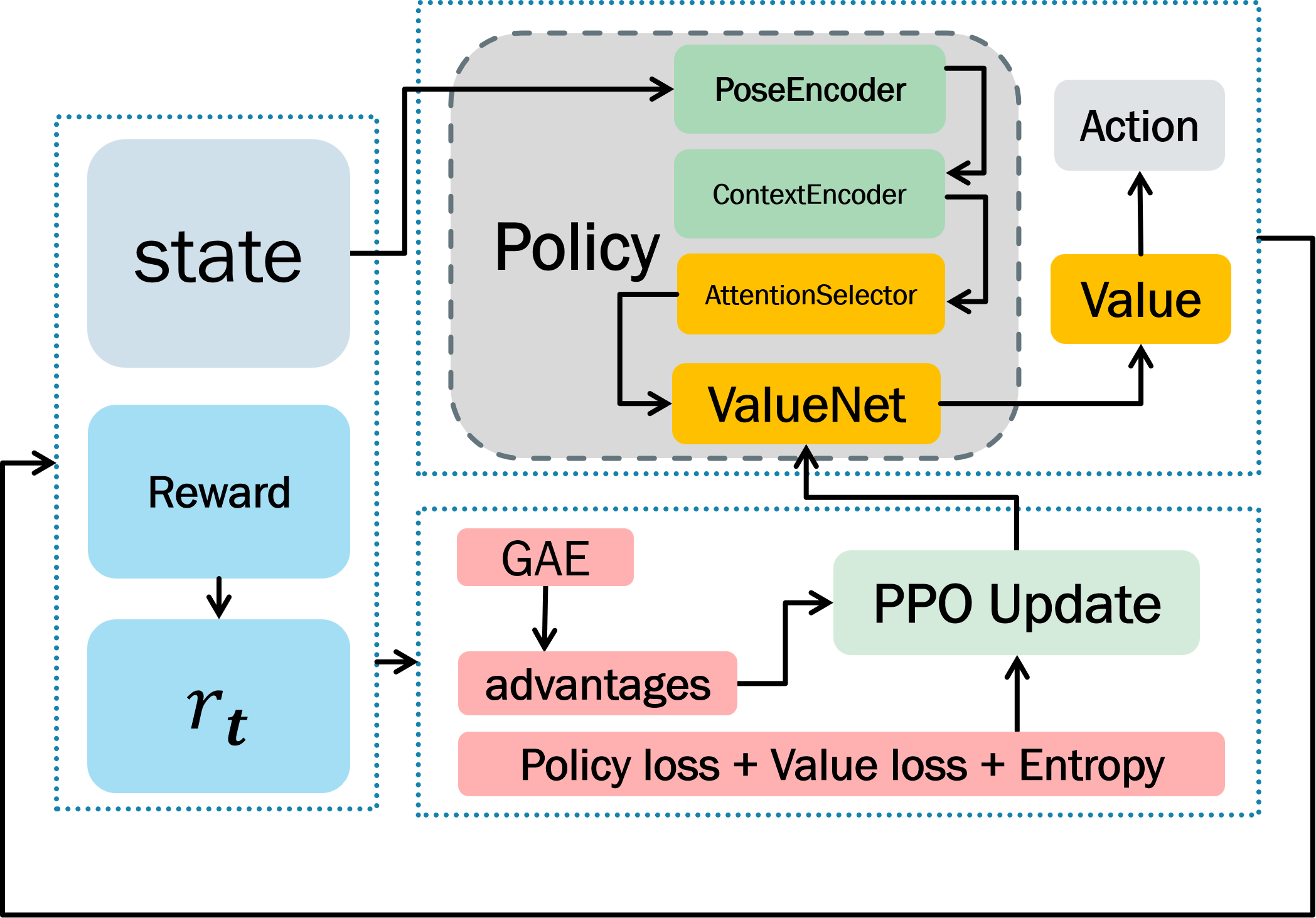
核心思路:论文的核心思路是将标定问题转化为一个实验设计问题,利用D-最优性准则来指导姿态的选择。D-最优性准则旨在最大化信息矩阵的行列式,从而选择信息量最大的姿态组合,以提高参数估计的精度和效率。同时,利用强化学习方法解决在约束条件下选择最优姿态组合的难题。
技术框架:该框架包含两个主要阶段:1) 基于Kronecker积的开环标定方法,将输入-输出对准问题转化为线性参数识别问题,并定义信息矩阵。2) 基于D-最优性准则和强化学习的姿态选择方法,训练PPO智能体从候选姿态集合中选择最优的姿态组合。整体流程是先通过理论分析建立标定模型,然后利用强化学习智能体进行姿态选择,最后利用选定的姿态数据进行参数估计。
关键创新:最重要的技术创新点在于将D-最优性准则与强化学习相结合,用于解决康复机器人的标定姿态选择问题。与传统的随机选择或启发式选择方法相比,该方法能够更有效地选择信息量最大的姿态组合,从而提高标定效率和精度。
关键设计:PPO智能体的奖励函数设计是关键。奖励函数的设计目标是最大化所选姿态组合的信息矩阵的行列式,同时考虑实际约束条件。具体来说,奖励函数可以设置为信息矩阵行列式的对数,并加入一些惩罚项,例如对超出关节活动范围的姿态进行惩罚。此外,候选姿态集合的选取也会影响最终的标定效果,需要根据机器人的结构和运动范围进行合理设计。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过PPO选择的4个姿态组合,其信息矩阵的平均行列式比随机选择的姿态组合高出两个数量级以上,且方差更小。真实机器人实验表明,使用D-最优性指导的姿态进行标定,能够获得更强的跨episode预测一致性,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种多自由度康复机器人的标定,提高标定效率和精度,从而提升康复训练的效果和安全性。此外,该方法也可推广到其他需要精确标定的机器人系统,例如工业机器人、医疗机器人等,具有广泛的应用前景。
📄 摘要(原文)
Accurate alignment of multi-degree-of-freedom rehabilitation robots is essential for safe and effective patient training. This paper proposes a two-stage calibration framework for a self-designed three-degree-of-freedom (3-DOF) ankle rehabilitation robot. First, a Kronecker-product-based open-loop calibration method is developed to cast the input-output alignment into a linear parameter identification problem, which in turn defines the associated experimental design objective through the resulting information matrix. Building on this formulation, calibration posture selection is posed as a combinatorial design-of-experiments problem guided by a D-optimality criterion, i.e., selecting a small subset of postures that maximises the determinant of the information matrix. To enable practical selection under constraints, a Proximal Policy Optimization (PPO) agent is trained in simulation to choose 4 informative postures from a candidate set of 50. Across simulation and real-robot evaluations, the learned policy consistently yields substantially more informative posture combinations than random selection: the mean determinant of the information matrix achieved by PPO is reported to be more than two orders of magnitude higher with reduced variance. In addition, real-world results indicate that a parameter vector identified from only four D-optimality-guided postures provides stronger cross-episode prediction consistency than estimates obtained from a larger but unstructured set of 50 postures. The proposed framework therefore improves calibration efficiency while maintaining robust parameter estimation, offering practical guidance for high-precision alignment of multi-DOF rehabilitation robots.