V-CAGE: Context-Aware Generation and Verification for Scalable Long-Horizon Embodied Tasks
作者: Yaru Liu, Ao-bo Wang, Nanyang Ye
分类: cs.RO, cs.AI
发布日期: 2026-01-21
💡 一句话要点
V-CAGE:上下文感知生成与验证,用于可扩展的长时程具身任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting)
关键词: 具身智能 长时程任务 合成数据 视觉语言模型 场景生成
📋 核心要点
- 现有方法生成的场景物理上不合理,语言驱动的程序经常在不满足任务语义的情况下“成功”,高层指令难以转化为可执行的动作序列。
- V-CAGE通过上下文感知的场景生成、分层指令分解和基于VLM的验证循环,生成物理和语义上更合理的数据集。
- 实验表明,使用V-CAGE生成的数据集训练的策略,在成功率和泛化能力上都优于使用未经验证的数据集训练的策略。
📝 摘要(中文)
本文提出V-CAGE,一个闭环框架,用于大规模生成鲁棒且语义对齐的操纵数据集,以解决从合成数据中学习长时程具身行为的挑战。该框架包含:1) 上下文感知的实例化机制,通过动态维护禁用的空间区域图,防止物体穿透,确保在杂乱环境中可达且无冲突的配置;2) 分层指令分解模块,将高层目标分解为可组合的动作原语,促进连贯的长时程规划;3) 基于视觉语言模型(VLM)的验证循环,作为视觉评论家,在每个子任务后执行严格的拒绝采样,过滤掉代码执行但未能实现视觉目标的“静默失败”。实验表明,与未经验证的基线相比,V-CAGE生成的数据集具有更高的物理和语义保真度,显著提高了下游策略的成功率和泛化能力。
🔬 方法详解
问题定义:论文旨在解决长时程具身任务中,从合成数据学习策略时面临的挑战,包括场景物理不合理、语义对齐不足以及高层指令难以转化为低层动作序列的问题。现有方法生成的合成数据往往存在物体穿透、不可达等物理缺陷,且难以保证程序执行结果与高层指令的语义一致性,导致训练出的策略泛化能力差。
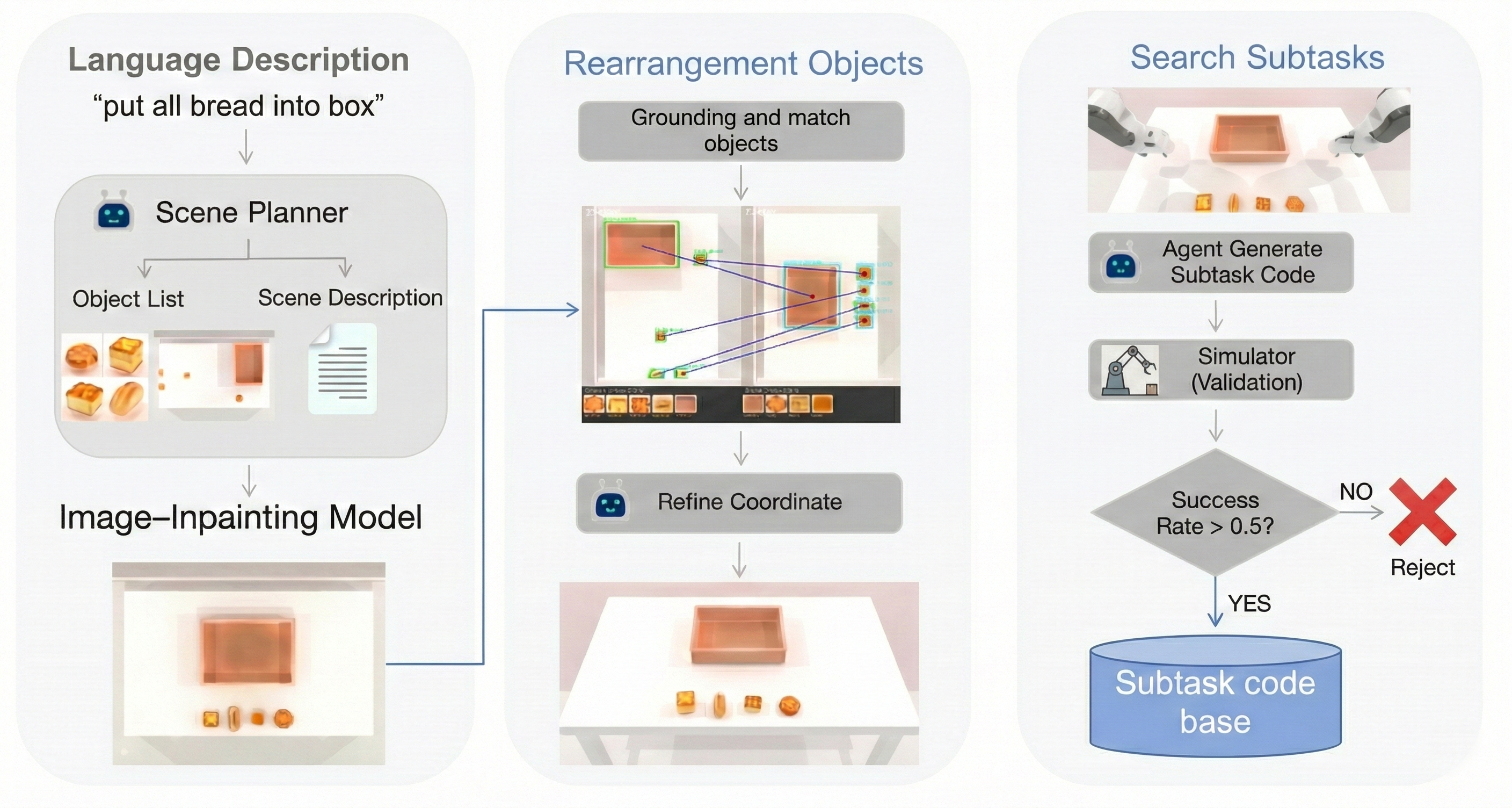
核心思路:论文的核心思路是通过闭环的生成与验证流程,生成高质量的合成数据。具体而言,首先通过上下文感知的实例化机制保证场景的物理合理性,然后通过分层指令分解将高层指令转化为可执行的动作序列,最后通过VLM验证循环确保动作序列的执行结果与高层指令的语义一致。
技术框架:V-CAGE框架包含三个主要模块:1) 上下文感知实例化模块,负责生成物理合理的场景;2) 分层指令分解模块,负责将高层指令分解为可执行的动作序列;3) 基于VLM的验证循环,负责验证动作序列的执行结果是否与高层指令的语义一致。整个流程是一个闭环,如果验证失败,则重新生成动作序列或场景。
关键创新:论文的关键创新在于将VLM引入到数据集生成流程中,作为视觉评论家,对生成的场景和动作序列进行语义验证。这种方法能够有效地过滤掉“静默失败”,即代码执行但未能实现视觉目标的场景,从而提高数据集的质量。
关键设计:上下文感知实例化模块通过动态维护一个禁用的空间区域图,防止物体穿透。分层指令分解模块将高层目标分解为一系列动作原语。VLM验证循环使用VLM判断动作序列的执行结果是否与高层指令的语义一致,并根据判断结果进行拒绝采样。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用V-CAGE生成的数据集训练的策略,在长时程具身任务上的成功率显著高于使用未经验证的数据集训练的策略。具体而言,V-CAGE能够将成功率提高10%-20%,并且在泛化能力方面也有显著提升。
🎯 应用场景
V-CAGE框架可应用于机器人操纵、自动驾驶等领域,通过生成高质量的合成数据,降低训练具身智能体的成本,提高智能体的泛化能力。该研究有助于推动具身智能技术的发展,使其能够更好地服务于现实世界的应用。
📄 摘要(原文)
Learning long-horizon embodied behaviors from synthetic data remains challenging because generated scenes are often physically implausible, language-driven programs frequently "succeed" without satisfying task semantics, and high-level instructions require grounding into executable action sequences. To address these limitations, we introduce V-CAGE, a closed-loop framework for generating robust, semantically aligned manipulation datasets at scale. First, we propose a context-aware instantiation mechanism that enforces geometric consistency during scene synthesis. By dynamically maintaining a map of prohibited spatial areas as objects are placed, our system prevents interpenetration and ensures reachable, conflict-free configurations in cluttered environments. Second, to bridge the gap between abstract intent and low-level control, we employ a hierarchical instruction decomposition module. This decomposes high-level goals (e.g., "get ready for work") into compositional action primitives, facilitating coherent long-horizon planning. Crucially, we enforce semantic correctness through a VLM-based verification loop. Acting as a visual critic, the VLM performs rigorous rejection sampling after each subtask, filtering out "silent failures" where code executes but fails to achieve the visual goal. Experiments demonstrate that V-CAGE yields datasets with superior physical and semantic fidelity, significantly boosting the success rate and generalization of downstream policies compared to non-verified baselines.