TIDAL: Temporally Interleaved Diffusion and Action Loop for High-Frequency VLA Control
作者: Yuteng Sun, Haoran Wang, Ruofei Bai, Zhengguo Li, Jun Li, Meng Yee, Chuah, Wei Yun Yau
分类: cs.RO, cs.AI
发布日期: 2026-01-21
💡 一句话要点
TIDAL:时序交错扩散与动作循环,实现高频VLA控制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 VLA 扩散模型 机器人控制 高频控制 时序对齐 动态环境
📋 核心要点
- 现有VLA模型推理延迟高,无法适应目标动态变化的环境,导致执行失败。
- TIDAL采用双频架构,解耦语义推理和高频执行,实现更快的控制频率。
- 实验表明,TIDAL在动态拦截任务中性能提升2倍,反馈频率提升4倍。
📝 摘要(中文)
大规模视觉-语言-动作(VLA)模型具有语义泛化能力,但推理延迟高,限制了其在低频批量执行范式中的应用。这种频率不匹配导致执行盲点,使得模型在目标动态移动的环境中失效。我们提出了TIDAL(时序交错扩散与动作循环),一个解耦语义推理和高频执行的分层框架。TIDAL作为基于扩散的VLA的骨干模块,采用双频架构来重新分配计算资源。具体来说,低频宏观意图循环缓存语义嵌入,而高频微观控制循环将单步流积分与执行交错进行。这种设计使得边缘硬件上能够实现约9 Hz的控制更新(基线约为2.4 Hz),而无需增加边际开销。为了处理由此产生的延迟偏移,我们引入了一种时序未对齐的训练策略,其中策略学习使用过时的语义意图以及实时本体感受进行预测补偿。此外,我们通过结合微分运动预测器来解决静态视觉编码器对速度的不敏感性。TIDAL是架构性的,使其与系统级优化正交。实验表明,在动态拦截任务中,性能比开环基线提高了2倍。尽管静态成功率略有下降,但我们的方法使反馈频率提高了4倍,并将语义嵌入的有效范围扩展到原生动作块大小之外。在非暂停推理协议下,TIDAL保持了鲁棒性,而标准基线由于延迟而失败。
🔬 方法详解
问题定义:现有的大规模视觉-语言-动作(VLA)模型虽然具备强大的语义理解能力,但由于推理延迟较高,通常采用低频率的批量执行模式。这种低频控制方式在目标动态变化的环境中会产生“执行盲点”,即模型在执行动作期间,目标已经发生了变化,导致任务失败。因此,如何降低VLA模型的推理延迟,提高控制频率,使其能够适应动态环境是亟待解决的问题。
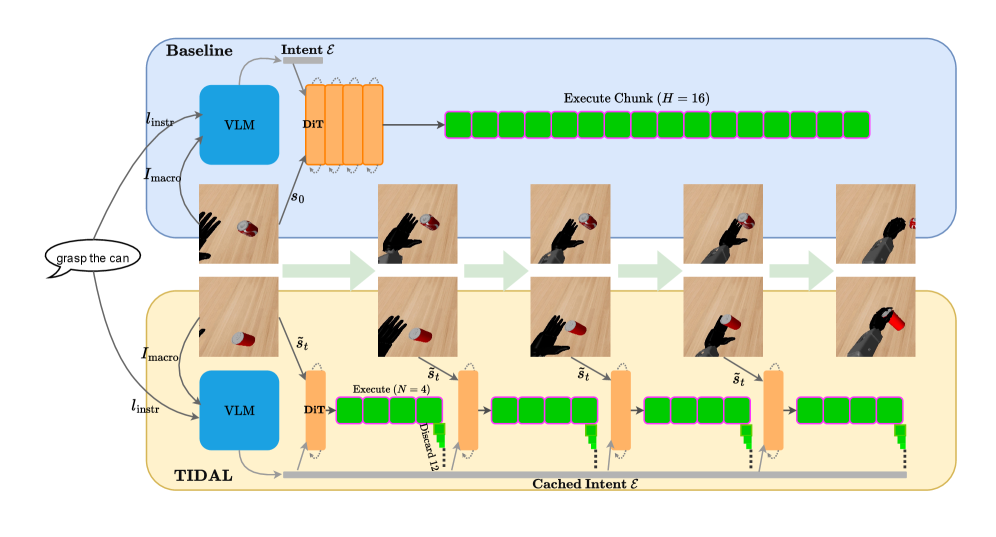
核心思路:TIDAL的核心思路是将VLA模型的控制过程分解为两个频率不同的循环:一个低频的宏观意图循环和一个高频的微观控制循环。低频循环负责进行语义推理,生成宏观的意图表示,并将其缓存。高频循环则利用缓存的意图表示,结合实时的本体感受信息,进行单步的动作规划和执行。通过这种双频架构,TIDAL能够在不增加计算开销的前提下,显著提高控制频率。
技术框架:TIDAL的整体架构包含两个主要循环:宏观意图循环和微观控制循环。宏观意图循环以较低的频率运行,负责接收视觉和语言输入,通过扩散模型进行语义推理,生成宏观的意图嵌入,并将其存储在缓存中。微观控制循环以较高的频率运行,从缓存中读取意图嵌入,并结合实时的本体感受信息(例如,机器人的关节角度、速度等),通过一个策略网络进行单步的动作规划,并将规划的动作发送给执行器。两个循环交错执行,从而实现高频率的控制。
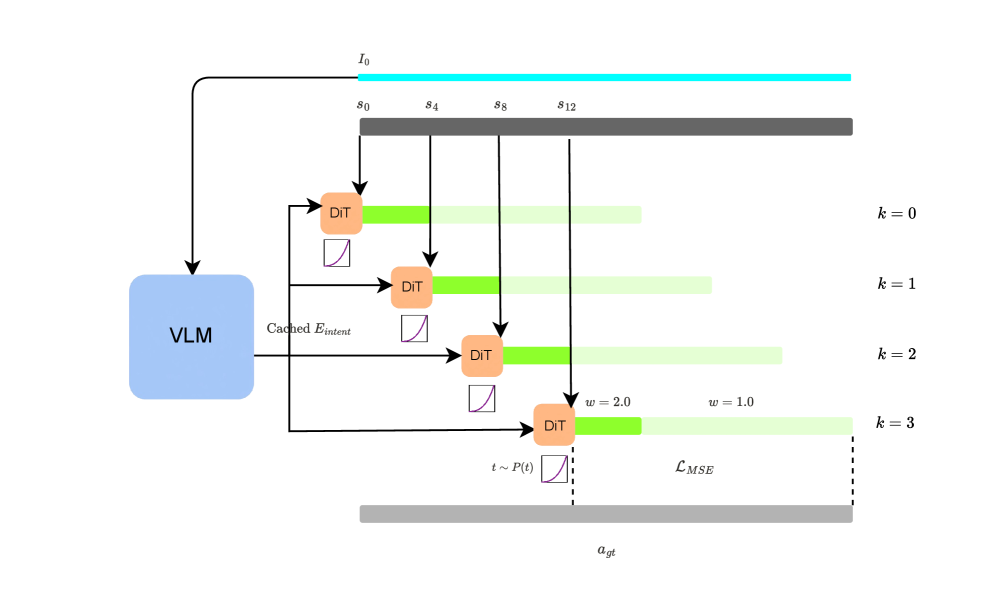
关键创新:TIDAL的关键创新在于其双频架构和时序未对齐的训练策略。双频架构实现了语义推理和高频执行的解耦,从而提高了控制频率。时序未对齐的训练策略则解决了由于延迟造成的训练和推理之间的差异。具体来说,在训练过程中,策略网络不仅接收实时的本体感受信息,还接收过时的意图嵌入,从而学习如何补偿由于延迟造成的误差。此外,论文还引入了一个微分运动预测器,用于增强模型对目标运动速度的感知能力。
关键设计:在时序未对齐的训练策略中,作者通过随机采样过去一段时间内的意图嵌入来模拟推理过程中的延迟。损失函数的设计也考虑了延迟的影响,鼓励策略网络学习预测性的补偿动作。微分运动预测器则通过计算连续帧之间的图像差异来估计目标的运动速度,并将其作为额外的输入提供给策略网络。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TIDAL在动态拦截任务中,相比于开环基线,性能提升了2倍。同时,TIDAL能够实现约9 Hz的控制频率,而基线方法仅为约2.4 Hz,反馈频率提升了4倍。即使在非暂停推理协议下,TIDAL仍然保持了鲁棒性,而标准基线由于延迟而失效。这些结果表明,TIDAL能够有效提高VLA模型在动态环境中的控制性能。
🎯 应用场景
TIDAL具有广泛的应用前景,例如:机器人动态抓取、自动驾驶、无人机编队控制等。该研究能够提升VLA模型在动态环境中的适应性和控制精度,使其能够更好地应用于现实世界的复杂任务中。未来,TIDAL有望成为VLA模型在机器人控制领域的重要组成部分。
📄 摘要(原文)
Large-scale Vision-Language-Action (VLA) models offer semantic generalization but suffer from high inference latency, limiting them to low-frequency batch-and-execute paradigm. This frequency mismatch creates an execution blind spot, causing failures in dynamic environments where targets move during the open-loop execution window. We propose TIDAL (Temporally Interleaved Diffusion and Action Loop), a hierarchical framework that decouples semantic reasoning from high-frequency actuation. TIDAL operates as a backbone-agnostic module for diffusion-based VLAs, using a dual-frequency architecture to redistribute the computational budget. Specifically, a low-frequency macro-intent loop caches semantic embeddings, while a high-frequency micro-control loop interleaves single-step flow integration with execution. This design enables approximately 9 Hz control updates on edge hardware (vs. approximately 2.4 Hz baselines) without increasing marginal overhead. To handle the resulting latency shift, we introduce a temporally misaligned training strategy where the policy learns predictive compensation using stale semantic intent alongside real-time proprioception. Additionally, we address the insensitivity of static vision encoders to velocity by incorporating a differential motion predictor. TIDAL is architectural, making it orthogonal to system-level optimizations. Experiments show a 2x performance gain over open-loop baselines in dynamic interception tasks. Despite a marginal regression in static success rates, our approach yields a 4x increase in feedback frequency and extends the effective horizon of semantic embeddings beyond the native action chunk size. Under non-paused inference protocols, TIDAL remains robust where standard baselines fail due to latency.