Vision-Language Models on the Edge for Real-Time Robotic Perception
作者: Sarat Ahmad, Maryam Hafeez, Syed Ali Raza Zaidi
分类: cs.RO, cs.AI
发布日期: 2026-01-21
💡 一句话要点
边缘计算赋能人形机器人:实时视觉-语言模型部署与性能优化
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 边缘计算 机器人感知 实时性 6G 多模态推理 人形机器人
📋 核心要点
- 现有视觉-语言模型在机器人上的部署受限于延迟、资源和隐私,难以满足实时性需求。
- 利用6G边缘计算,将视觉-语言模型部署在靠近机器人侧的ORAN/MEC基础设施上,降低延迟。
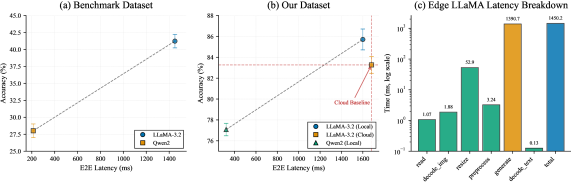
- 实验表明,边缘部署的LLaMA-3.2-11B-Vision-Instruct模型延迟降低5%,Qwen2-VL-2B-Instruct模型延迟降低超过50%。
📝 摘要(中文)
视觉-语言模型(VLMs)为机器人感知和交互提供了多模态推理能力,但由于延迟、有限的板载资源以及云卸载带来的隐私风险,它们在实际系统中的部署仍然受到限制。6G中的边缘智能,特别是开放式无线接入网(ORAN)和多接入边缘计算(MEC),通过将计算更靠近数据源,为解决这些挑战提供了一条途径。本文研究了在ORAN/MEC基础设施上部署VLMs,使用宇树G1人形机器人作为具身测试平台。我们设计了一个基于WebRTC的流水线,将多模态数据流传输到边缘节点,并在实时条件下评估了部署在边缘与云端的LLaMA-3.2-11B-Vision-Instruct。结果表明,边缘部署在保持接近云端精度的同时,将端到端延迟降低了5%。我们进一步评估了Qwen2-VL-2B-Instruct,这是一种针对资源受限环境优化的紧凑模型,它实现了亚秒级的响应速度,延迟降低了一半以上,但牺牲了精度。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLMs)在机器人实时感知和交互应用中面临的延迟高、资源需求大以及隐私风险等问题。现有方法通常依赖于云端计算,导致较高的网络延迟,无法满足实时性要求。同时,将所有数据上传到云端也存在隐私泄露的风险。此外,机器人自身的计算资源有限,难以直接运行大型VLMs。
核心思路:论文的核心思路是将VLMs部署在靠近机器人侧的边缘计算节点上,利用6G网络提供的低延迟和高带宽特性,实现实时多模态数据处理。通过边缘计算,可以显著降低网络延迟,提高响应速度,同时保护用户隐私。此外,论文还探索了轻量级VLMs在资源受限环境下的应用,以进一步降低计算成本。
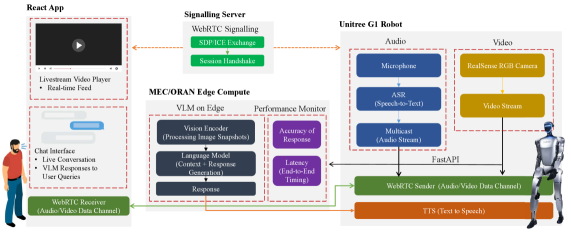
技术框架:论文构建了一个基于WebRTC的多模态数据流传输流水线,将机器人采集的视觉和语言数据实时传输到边缘计算节点。在边缘节点上部署VLMs进行推理,并将结果返回给机器人。整体框架包括以下几个主要模块:1) 数据采集模块:负责从机器人获取视觉和语言数据;2) 数据传输模块:使用WebRTC协议将数据流传输到边缘节点;3) 边缘计算模块:部署VLMs进行推理;4) 结果反馈模块:将推理结果返回给机器人。
关键创新:论文的关键创新在于将VLMs与6G边缘计算相结合,为机器人实时感知和交互提供了一种新的解决方案。通过边缘部署,可以显著降低延迟,提高响应速度,同时保护用户隐私。此外,论文还探索了轻量级VLMs在资源受限环境下的应用,为机器人应用提供了更多的选择。
关键设计:论文使用了LLaMA-3.2-11B-Vision-Instruct和Qwen2-VL-2B-Instruct两种VLMs。LLaMA-3.2-11B-Vision-Instruct是一个大型模型,具有较高的精度,但计算成本较高。Qwen2-VL-2B-Instruct是一个轻量级模型,针对资源受限环境进行了优化,具有较低的计算成本,但精度相对较低。论文评估了这两种模型在边缘计算环境下的性能,并分析了精度和延迟之间的权衡。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在边缘部署LLaMA-3.2-11B-Vision-Instruct模型,端到端延迟降低了5%,同时保持了接近云端的精度。而使用Qwen2-VL-2B-Instruct模型,延迟降低超过50%,实现了亚秒级的响应速度,但精度有所下降。这些结果验证了边缘计算在降低延迟方面的有效性,并为选择合适的VLMs提供了参考。
🎯 应用场景
该研究成果可应用于多种机器人应用场景,例如智能巡检机器人、智能客服机器人、智能制造机器人等。通过边缘计算赋能,这些机器人可以实现更快速、更准确的感知和交互,从而提高工作效率和服务质量。此外,该研究还可以促进6G边缘计算技术在机器人领域的应用,推动机器人智能化发展。
📄 摘要(原文)
Vision-Language Models (VLMs) enable multimodal reasoning for robotic perception and interaction, but their deployment in real-world systems remains constrained by latency, limited onboard resources, and privacy risks of cloud offloading. Edge intelligence within 6G, particularly Open RAN and Multi-access Edge Computing (MEC), offers a pathway to address these challenges by bringing computation closer to the data source. This work investigates the deployment of VLMs on ORAN/MEC infrastructure using the Unitree G1 humanoid robot as an embodied testbed. We design a WebRTC-based pipeline that streams multimodal data to an edge node and evaluate LLaMA-3.2-11B-Vision-Instruct deployed at the edge versus in the cloud under real-time conditions. Our results show that edge deployment preserves near-cloud accuracy while reducing end-to-end latency by 5\%. We further evaluate Qwen2-VL-2B-Instruct, a compact model optimized for resource-constrained environments, which achieves sub-second responsiveness, cutting latency by more than half but at the cost of accuracy.