HumanoidVLM: Vision-Language-Guided Impedance Control for Contact-Rich Humanoid Manipulation
作者: Yara Mahmoud, Yasheerah Yaqoot, Miguel Altamirano Cabrera, Dzmitry Tsetserukou
分类: cs.RO
发布日期: 2026-01-21
备注: This paper has been accepted for publication at LBR of HRI 2026 conference
💡 一句话要点
HumanoidVLM:基于视觉-语言引导的阻抗控制,用于人型机器人富接触操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 人型机器人 视觉-语言模型 阻抗控制 检索增强生成 富接触操作
📋 核心要点
- 现有的人型机器人控制器通常依赖于固定的、手动调整的阻抗增益和夹爪设置,难以适应多样化的对象和任务。
- HumanoidVLM通过视觉-语言模型进行语义任务推理,并使用RAG模块检索合适的阻抗参数和夹爪配置,实现自适应控制。
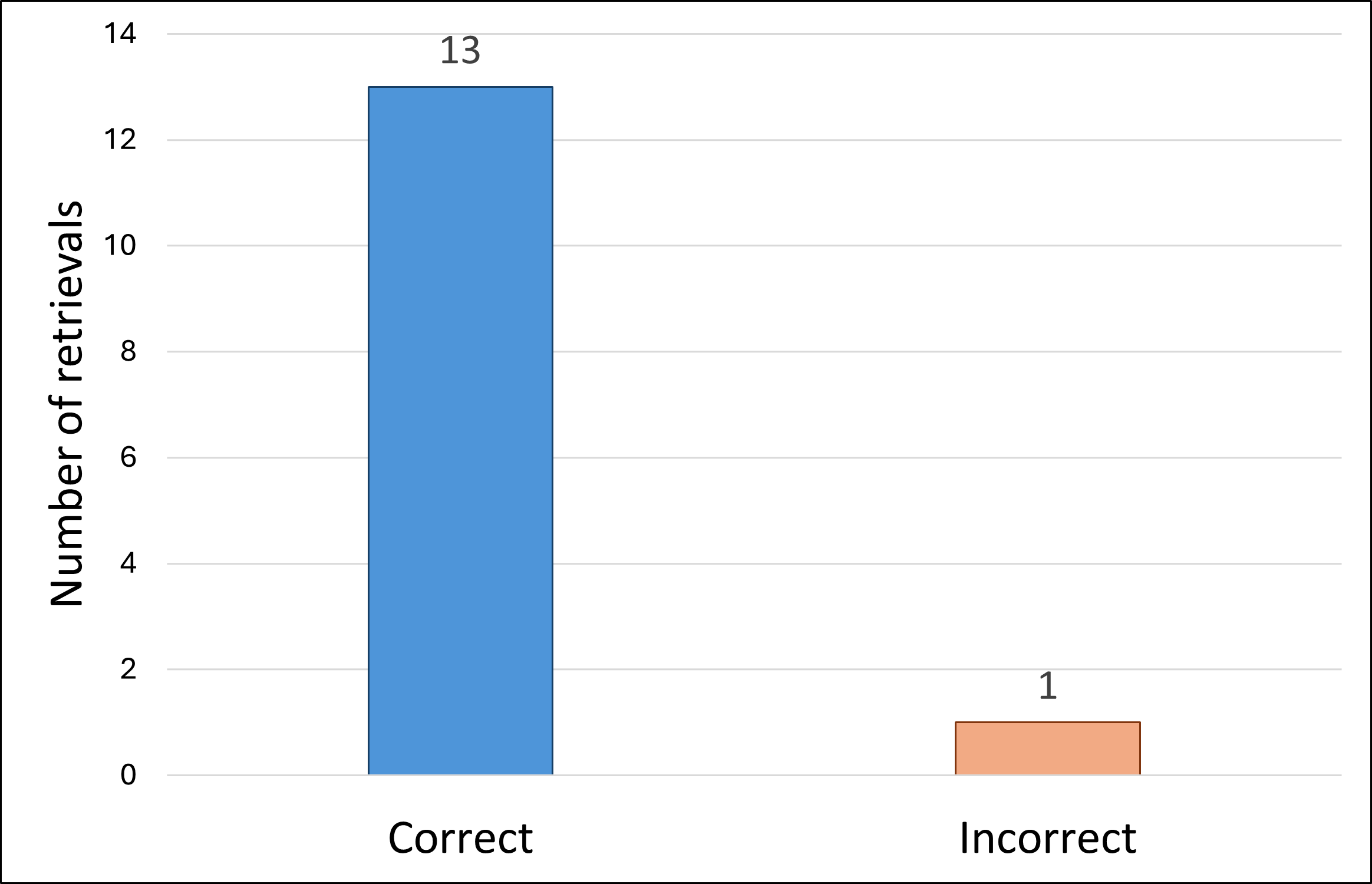
- 实验结果表明,HumanoidVLM在真实场景中实现了稳定的交互动力学,并具有较高的检索准确率和可接受的跟踪误差。
📝 摘要(中文)
本文提出了一种名为HumanoidVLM的视觉-语言驱动的检索框架,旨在使Unitree G1人型机器人能够直接从第一人称RGB图像中选择适合任务的笛卡尔阻抗参数和夹爪配置。该系统将视觉-语言模型用于语义任务推理,并结合基于FAISS的检索增强生成(RAG)模块,从两个自定义数据库中检索经过实验验证的刚度-阻尼对和特定于对象的抓取角度,并通过任务空间阻抗控制器执行这些参数,从而实现柔顺操作。在14个视觉场景中评估了HumanoidVLM,检索准确率达到93%。真实世界的实验表明,交互动力学稳定,z轴跟踪误差通常在1-3.5厘米范围内,虚拟力与任务相关的阻抗设置一致。这些结果证明了将语义感知与基于检索的控制相结合,作为实现自适应人型机器人操作的一种可解释途径的可行性。
🔬 方法详解
问题定义:现有的人型机器人操作方法在处理具有不同形状、材质和交互要求的物体时,通常需要手动调整阻抗控制器的参数和夹爪配置。这种手动调整过程耗时且缺乏泛化能力,难以适应复杂多变的操作环境。因此,如何使人型机器人能够根据视觉感知自动选择合适的控制参数,实现自适应的富接触操作,是一个亟待解决的问题。
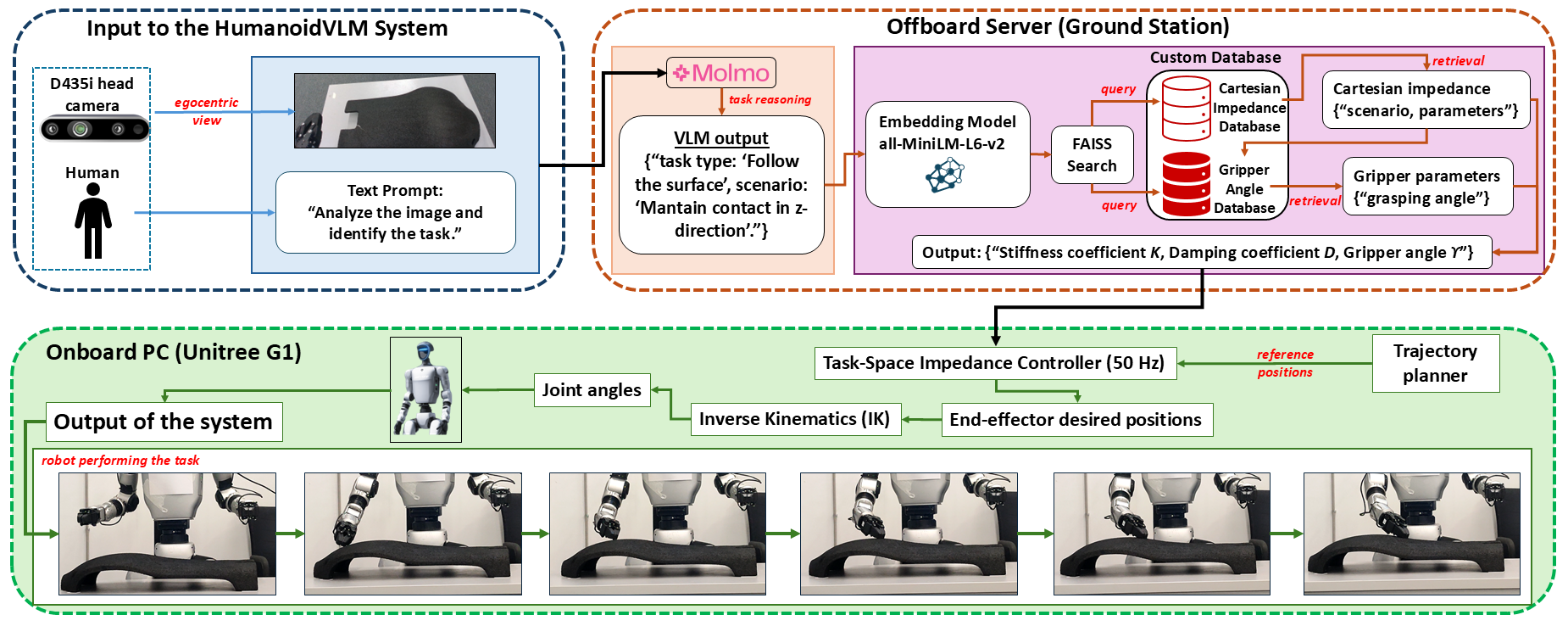
核心思路:HumanoidVLM的核心思路是将视觉-语言模型用于语义任务理解,并结合检索增强生成(RAG)模块,从预先构建的数据库中检索与当前任务相关的阻抗参数和夹爪配置。通过将语义感知与检索到的控制参数相结合,机器人可以根据不同的任务需求调整其交互行为,从而实现自适应的富接触操作。
技术框架:HumanoidVLM的整体框架包括以下几个主要模块:1) 视觉-语言模型:用于从第一人称RGB图像中提取语义信息,并推断当前的任务类型。2) 检索增强生成(RAG)模块:包含两个自定义数据库,分别存储了经过实验验证的刚度-阻尼对和特定于对象的抓取角度。RAG模块根据视觉-语言模型的输出,从数据库中检索最相关的控制参数。3) 任务空间阻抗控制器:根据检索到的阻抗参数和夹爪配置,控制人型机器人的运动和力。
关键创新:HumanoidVLM的关键创新在于将视觉-语言模型与检索增强生成相结合,实现了一种可解释的自适应人型机器人操作方法。与传统的基于学习的方法相比,HumanoidVLM具有更好的可解释性和泛化能力,并且不需要大量的训练数据。此外,通过将控制参数存储在数据库中,可以方便地添加新的对象和任务,从而扩展系统的功能。
关键设计:在视觉-语言模型方面,论文使用了预训练的CLIP模型,并对其进行了微调,以适应人型机器人的操作任务。在RAG模块方面,论文使用了FAISS库进行快速相似性搜索,并设计了一种基于余弦相似度的检索策略。在任务空间阻抗控制器方面,论文使用了标准的阻抗控制算法,并根据检索到的刚度-阻尼参数进行调整。
🖼️ 关键图片

📊 实验亮点
HumanoidVLM在14个视觉场景中实现了93%的检索准确率。真实世界的实验表明,该系统能够实现稳定的交互动力学,z轴跟踪误差通常在1-3.5厘米范围内,虚拟力与任务相关的阻抗设置一致。这些结果表明,HumanoidVLM能够有效地将语义感知与检索到的控制参数相结合,实现自适应的人型机器人操作。
🎯 应用场景
HumanoidVLM具有广泛的应用前景,例如在家庭服务、工业自动化和医疗保健等领域。它可以使人型机器人能够安全、高效地与各种物体进行交互,完成诸如物品整理、装配和辅助康复等任务。此外,该研究为开发更智能、更灵活的人型机器人提供了一种新的思路。
📄 摘要(原文)
Humanoid robots must adapt their contact behavior to diverse objects and tasks, yet most controllers rely on fixed, hand-tuned impedance gains and gripper settings. This paper introduces HumanoidVLM, a vision-language driven retrieval framework that enables the Unitree G1 humanoid to select task-appropriate Cartesian impedance parameters and gripper configurations directly from an egocentric RGB image. The system couples a vision-language model for semantic task inference with a FAISS-based Retrieval-Augmented Generation (RAG) module that retrieves experimentally validated stiffness-damping pairs and object-specific grasp angles from two custom databases, and executes them through a task-space impedance controller for compliant manipulation. We evaluate HumanoidVLM on 14 visual scenarios and achieve a retrieval accuracy of 93%. Real-world experiments show stable interaction dynamics, with z-axis tracking errors typically within 1-3.5 cm and virtual forces consistent with task-dependent impedance settings. These results demonstrate the feasibility of linking semantic perception with retrieval-based control as an interpretable path toward adaptive humanoid manipulation.