FARE: Fast-Slow Agentic Robotic Exploration
作者: Shuhao Liao, Xuxin Lv, Jeric Lew, Shizhe Zhang, Jingsong Liang, Peizhuo Li, Yuhong Cao, Wenjun Wu, Guillaume Sartoretti
分类: cs.RO
发布日期: 2026-01-21
💡 一句话要点
FARE:一种基于快慢Agent的机器人自主探索框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自主探索 机器人 大型语言模型 强化学习 语义推理
📋 核心要点
- 现有自主探索方法难以有效融合全局语义理解和局部环境感知,导致探索效率低下。
- FARE框架结合LLM的全局推理和RL的局部决策,实现快慢思考模式,提升探索效率和鲁棒性。
- 实验表明,FARE在模拟和真实环境中均显著提升了探索效率,验证了其有效性。
📝 摘要(中文)
本文提出了一种用于自主机器人探索的框架FARE,它集成了Agent层面的语义推理和快速局部控制。FARE采用分层自主探索框架,利用大型语言模型(LLM)进行全局推理,并结合强化学习(RL)策略进行局部决策。FARE遵循快慢思考模式,其中慢思考的LLM模块解释未知环境的简明文本描述,并综合Agent层面的探索策略,通过拓扑图将其转化为一系列全局路标点。为了提高推理效率,该模块采用基于模块化的剪枝机制,减少冗余的图结构。快思考的RL模块通过对局部观测做出反应来执行探索,同时受到LLM生成的全局路标点的引导。RL策略还受到奖励项的塑造,鼓励遵守全局路标点,从而实现连贯而鲁棒的闭环行为。这种架构将语义推理与几何决策分离,使每个模块都能在其适当的时间和空间尺度上运行。在具有挑战性的模拟环境中,结果表明,FARE在探索效率方面优于最先进的基线。此外,FARE还在硬件上进行了部署,并在复杂的大型200m×130m建筑环境中进行了验证。
🔬 方法详解
问题定义:现有自主探索方法通常难以兼顾全局语义理解和局部环境感知,导致探索策略缺乏全局一致性,探索效率低下。此外,在复杂环境中,计算资源有限,如何快速有效地进行探索决策是一个挑战。
核心思路:FARE的核心思路是将探索任务分解为全局语义推理和局部环境感知两个层次。利用大型语言模型(LLM)进行全局语义推理,生成全局探索策略;利用强化学习(RL)策略进行局部环境感知和决策,快速响应环境变化。通过快慢思考模式,实现全局规划和局部执行的有效结合。
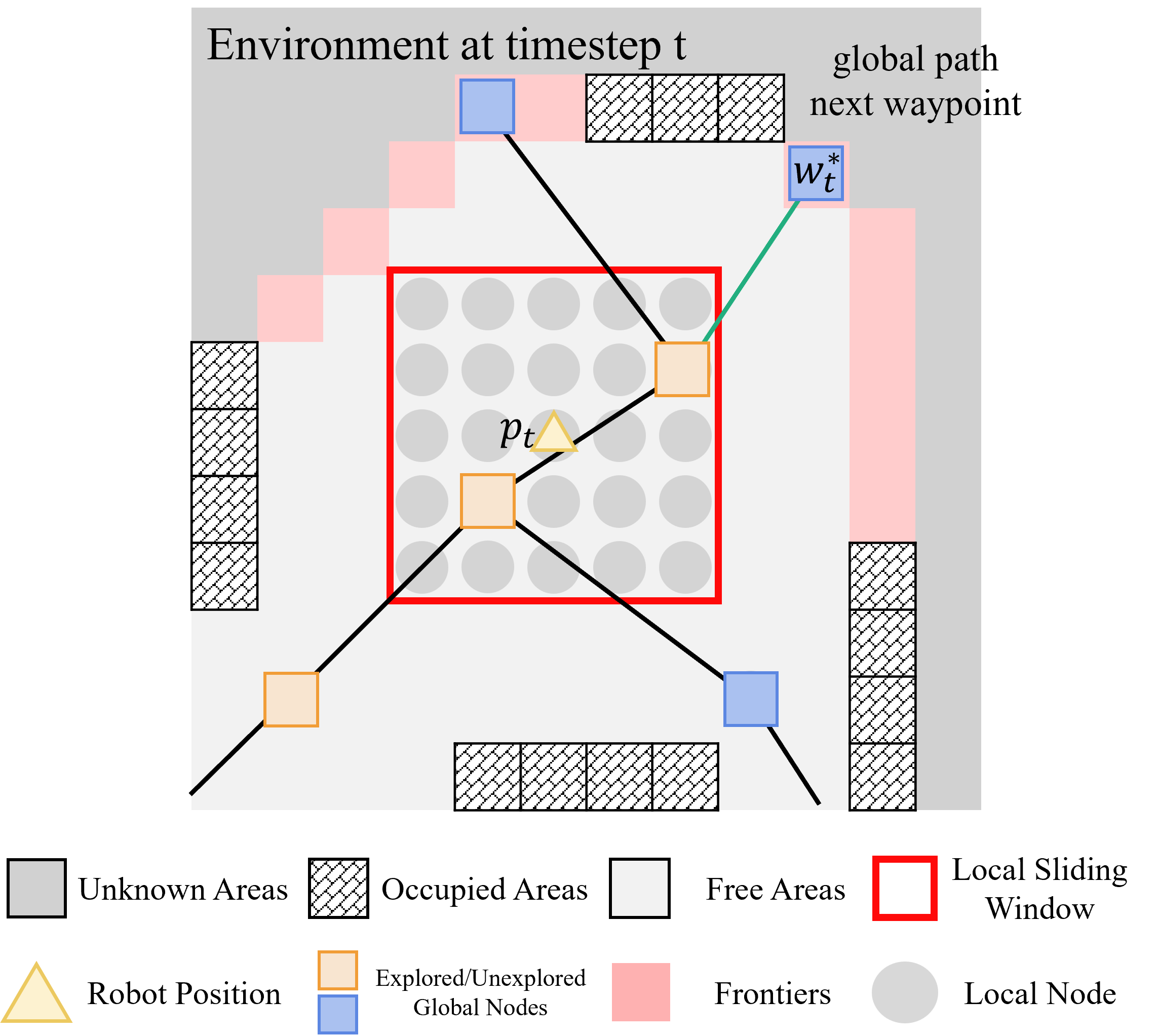
技术框架:FARE框架包含两个主要模块:慢思考的LLM模块和快思考的RL模块。LLM模块接收环境的文本描述,生成全局探索策略,并将其转化为一系列全局路标点。RL模块接收局部环境观测和LLM生成的路标点,通过强化学习策略控制机器人运动,完成探索任务。框架还包含一个拓扑图,用于表示环境结构和路标点之间的关系。
关键创新:FARE的关键创新在于将大型语言模型(LLM)引入到机器人自主探索任务中,利用LLM的语义理解能力进行全局推理和规划。此外,FARE还提出了基于模块化的剪枝机制,用于减少LLM推理的计算量,提高推理效率。快慢思考模式的结合,使得FARE能够兼顾全局规划和局部执行,提高探索效率和鲁棒性。
关键设计:LLM模块使用预训练的LLM模型,并针对探索任务进行微调。RL模块使用深度强化学习算法,例如PPO或DDPG,训练机器人控制策略。奖励函数的设计至关重要,除了鼓励机器人探索未知区域外,还需要鼓励机器人遵循LLM生成的全局路标点。拓扑图的构建和维护也需要仔细设计,以保证全局规划的有效性。
🖼️ 关键图片
📊 实验亮点
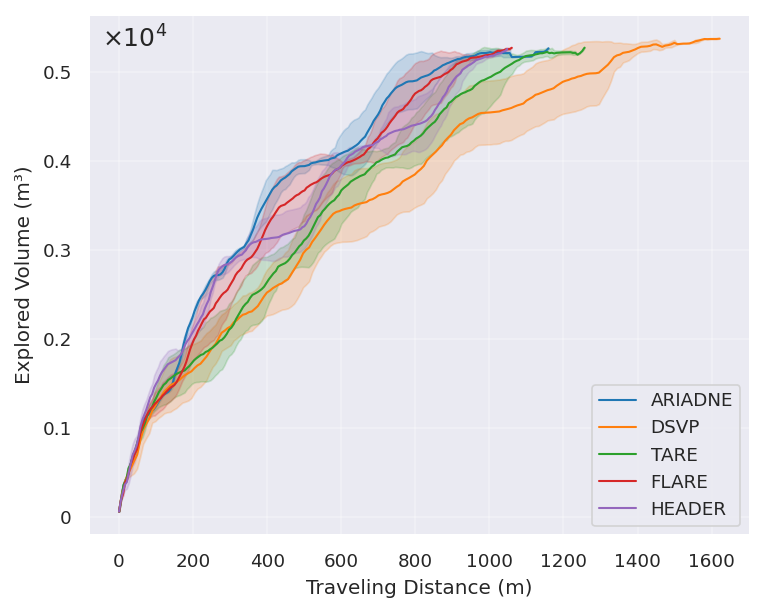
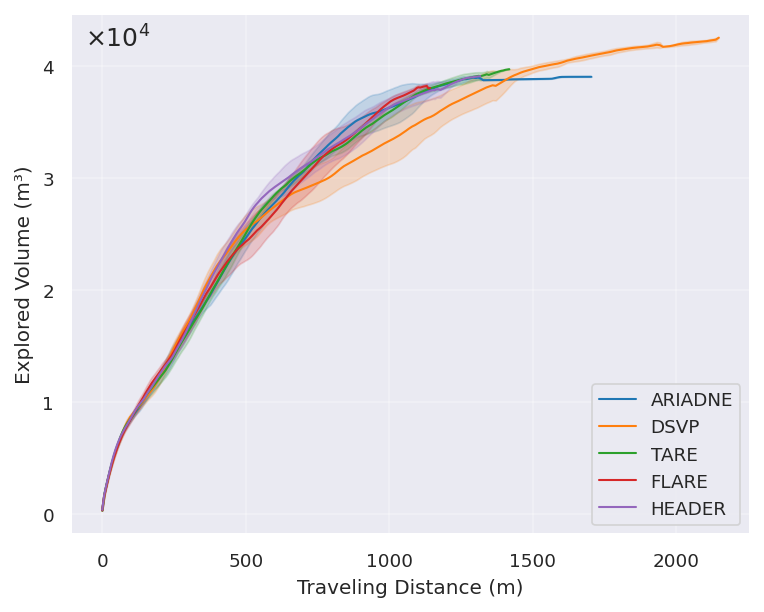
FARE在模拟环境中取得了显著的性能提升,探索效率优于最先进的基线方法。此外,FARE还在真实的200m×130m大型建筑环境中进行了验证,证明了其在实际应用中的可行性。实验结果表明,FARE能够有效地利用LLM进行全局规划,并结合RL进行局部执行,实现高效的自主探索。
🎯 应用场景
FARE框架可应用于各种自主机器人探索场景,例如室内环境清洁、仓库巡检、灾难救援等。该研究的实际价值在于提高了机器人自主探索的效率和鲁棒性,降低了人工干预的需求。未来,FARE可以进一步扩展到更复杂的环境和任务中,例如室外环境探索、多机器人协同探索等。
📄 摘要(原文)
This work advances autonomous robot exploration by integrating agent-level semantic reasoning with fast local control. We introduce FARE, a hierarchical autonomous exploration framework that integrates a large language model (LLM) for global reasoning with a reinforcement learning (RL) policy for local decision making. FARE follows a fast-slow thinking paradigm. The slow-thinking LLM module interprets a concise textual description of the unknown environment and synthesizes an agent-level exploration strategy, which is then grounded into a sequence of global waypoints through a topological graph. To further improve reasoning efficiency, this module employs a modularity-based pruning mechanism that reduces redundant graph structures. The fast-thinking RL module executes exploration by reacting to local observations while being guided by the LLM-generated global waypoints. The RL policy is additionally shaped by a reward term that encourages adherence to the global waypoints, enabling coherent and robust closed-loop behavior. This architecture decouples semantic reasoning from geometric decision, allowing each module to operate in its appropriate temporal and spatial scale. In challenging simulated environments, our results show that FARE achieves substantial improvements in exploration efficiency over state-of-the-art baselines. We further deploy FARE on hardware and validate it in complex, large scale $200m\times130m$ building environment.