Spatially Generalizable Mobile Manipulation via Adaptive Experience Selection and Dynamic Imagination
作者: Ping Zhong, Liangbai Liu, Bolei Chen, Tao Wu, Jiazhi Xia, Chaoxu Mu, Jianxin Wang
分类: cs.RO
发布日期: 2026-01-21
💡 一句话要点
提出自适应经验选择与动态想象,提升移动操作的空间泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 移动操作 空间泛化 自适应经验选择 动态想象 循环状态空间模型 模型预测控制 机器人学习
📋 核心要点
- 现有移动操作方法样本效率低,冗余数据利用不足,且空间泛化能力差,难以适应新的空间布局。
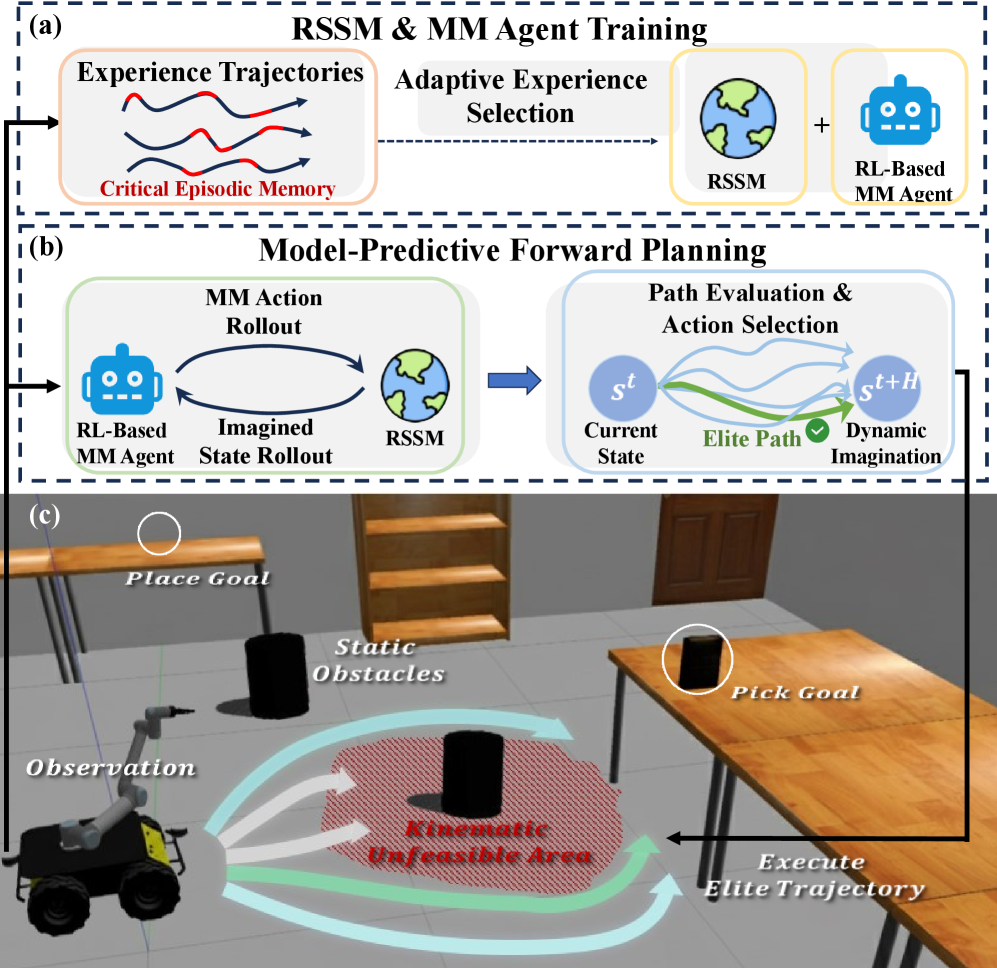
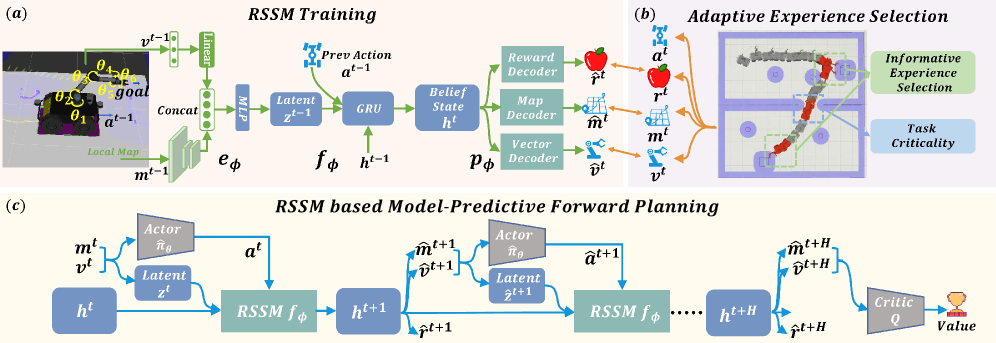
- 提出自适应经验选择(AES)和基于模型的动态想象,使智能体关注关键经验,并利用循环状态空间模型(RSSM)进行预测规划。
- 实验结果表明,该方法显著优于现有移动操作策略,并在真实世界实验中验证了可行性和实用性。
📝 摘要(中文)
移动操作(MM)涉及跨异构技能的多阶段组合的长期决策,例如导航和拾取物体。现有的MM方法面临两个关键限制:(i)样本效率低,因为长期MM交互中产生的冗余数据未被有效利用;(ii)空间泛化能力差,因为在特定任务上训练的策略难以迁移到新的空间布局,而无需额外的训练。本文通过自适应经验选择(AES)和基于模型的动态想象来解决这些挑战。AES使MM智能体更加关注影响任务成功的长轨迹中的关键经验片段,从而改进技能链学习并减轻技能遗忘。基于AES,引入循环状态空间模型(RSSM),通过捕获移动底座和机械臂之间的耦合动力学并想象未来操作的动力学,用于基于模型的预测前向规划(MPFP)。基于RSSM的MPFP可以加强当前任务的MM技能学习,同时实现对新空间布局的有效泛化。不同实验配置的对比研究表明,我们的方法明显优于现有的MM策略。真实世界的实验进一步验证了我们方法的可行性和实用性。
🔬 方法详解
问题定义:论文旨在解决移动操作任务中样本效率低和空间泛化能力差的问题。现有方法在长期交互中产生大量冗余数据,未能有效利用,导致样本效率低下。此外,针对特定空间布局训练的策略难以泛化到新的空间布局,需要额外的训练。
核心思路:论文的核心思路是通过自适应经验选择(AES)关注关键经验片段,并利用基于循环状态空间模型(RSSM)的动态想象进行模型预测前向规划(MPFP)。AES能够提高技能链学习效率,减轻技能遗忘;RSSM-based MPFP能够捕获移动底座和机械臂之间的耦合动力学,并想象未来操作的动力学,从而提高空间泛化能力。
技术框架:整体框架包含两个主要部分:自适应经验选择(AES)和基于RSSM的动态想象。AES模块负责从长期交互轨迹中选择关键经验片段,用于训练RSSM。RSSM模块用于学习移动底座和机械臂的耦合动力学模型,并进行模型预测前向规划(MPFP),从而指导智能体的行为。
关键创新:论文的关键创新在于结合了自适应经验选择和基于模型的动态想象。AES能够提高样本效率,而基于RSSM的动态想象能够提高空间泛化能力。这种结合使得智能体能够在新的空间布局中快速适应并完成任务。
关键设计:AES通过某种奖励或价值函数来评估经验片段的重要性,并选择高价值的片段进行学习。RSSM采用循环神经网络结构,能够捕获时间序列数据的动态特性。MPFP使用RSSM预测未来状态,并选择能够最大化预期奖励的动作序列。具体的损失函数和网络结构等细节在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
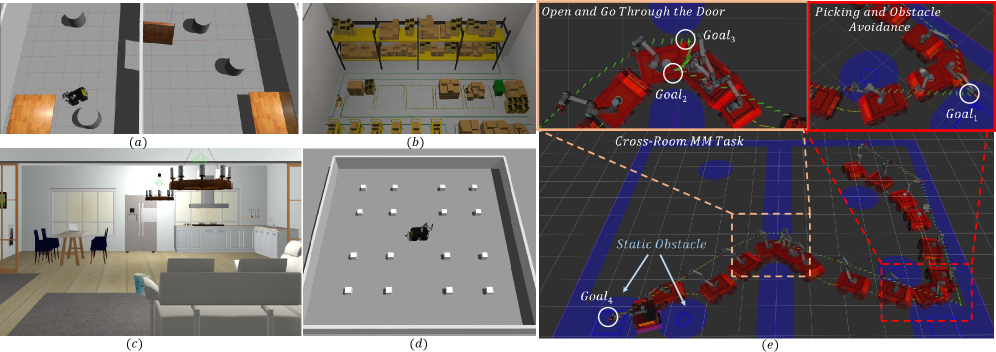
实验结果表明,该方法在不同实验配置下均显著优于现有移动操作策略。具体的性能数据和提升幅度在论文中有详细描述(未知)。此外,真实世界的实验验证了该方法的可行性和实用性,表明其具有实际应用潜力。
🎯 应用场景
该研究成果可应用于各种需要移动操作的场景,例如家庭服务机器人、仓库自动化、医疗辅助机器人等。通过提高移动操作的样本效率和空间泛化能力,可以降低部署成本,提高机器人的适应性和鲁棒性,从而更好地服务于人类。
📄 摘要(原文)
Mobile Manipulation (MM) involves long-horizon decision-making over multi-stage compositions of heterogeneous skills, such as navigation and picking up objects. Despite recent progress, existing MM methods still face two key limitations: (i) low sample efficiency, due to ineffective use of redundant data generated during long-term MM interactions; and (ii) poor spatial generalization, as policies trained on specific tasks struggle to transfer to new spatial layouts without additional training. In this paper, we address these challenges through Adaptive Experience Selection (AES) and model-based dynamic imagination. In particular, AES makes MM agents pay more attention to critical experience fragments in long trajectories that affect task success, improving skill chain learning and mitigating skill forgetting. Based on AES, a Recurrent State-Space Model (RSSM) is introduced for Model-Predictive Forward Planning (MPFP) by capturing the coupled dynamics between the mobile base and the manipulator and imagining the dynamics of future manipulations. RSSM-based MPFP can reinforce MM skill learning on the current task while enabling effective generalization to new spatial layouts. Comparative studies across different experimental configurations demonstrate that our method significantly outperforms existing MM policies. Real-world experiments further validate the feasibility and practicality of our method.