Probing Prompt Design for Socially Compliant Robot Navigation with Vision Language Models
作者: Ling Xiao, Toshihiko Yamasaki
分类: cs.RO
发布日期: 2026-01-21
💡 一句话要点
针对社交机器人导航,提出基于认知理论的提示工程方法,提升小VLM的社交合规性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交机器人导航 视觉语言模型 提示工程 认知理论 社交合规性
📋 核心要点
- 现有社交机器人导航基准测试缺乏对社交合规行为的原则性提示设计,尤其是在资源受限的小型VLM上。
- 受认知理论启发,论文从系统指导和动机框架两方面设计提示,引导VLM做出更符合社会规范的导航决策。
- 实验表明,精心设计的提示能显著提升小VLM的动作准确性,甚至优于直接微调,表明提示主要作用于决策层面。
📝 摘要(中文)
本文研究了语言模型在社交机器人导航中的应用,着重关注了针对社交合规行为的提示工程设计。现有基准测试在很大程度上忽略了对社交合规行为的原则性提示设计,这在实践中尤为重要,因为许多系统依赖于小型视觉语言模型(VLM)以提高效率。与大型语言模型相比,小型VLM的决策能力较弱,因此有效的提示设计对于准确导航至关重要。受人类学习和动机认知理论的启发,本文从两个维度研究提示设计:系统指导(以动作为中心、以推理为导向以及感知-推理提示)和动机框架,其中模型与人类、其他AI系统或其过去的自我竞争。在两个社交合规导航数据集上的实验表明,对于非微调的GPT-4o,与人类竞争可实现最佳性能,而与其他AI系统竞争则表现最差。对于微调模型,与模型过去的自我竞争产生最强的结果,其次是与人类竞争,性能进一步受到提示设计、模型选择和数据集特征之间耦合效应的影响。不恰当的系统提示设计会显著降低性能,甚至低于直接微调。直接微调可显著提高语义级别的指标,如感知、预测和推理,但在动作准确性方面的提升有限。相比之下,本文的系统提示在动作准确性方面产生了不成比例的更大改进,表明所提出的提示设计主要充当决策级别的约束,而不是表征增强。
🔬 方法详解
问题定义:论文旨在解决社交机器人导航中,小型视觉语言模型(VLM)由于决策能力较弱,难以实现社交合规行为的问题。现有方法通常忽略了针对社交合规行为的提示工程设计,导致VLM在复杂社交场景下的导航性能不佳。直接微调虽然可以提升语义理解能力,但对动作准确性的提升有限。
核心思路:论文的核心思路是借鉴人类学习和动机的认知理论,设计有效的提示,引导VLM做出更符合社会规范的导航决策。通过系统指导和动机框架两个维度,为VLM提供更清晰的行动指令和更强的行动动机,从而提升其在社交场景下的导航性能。
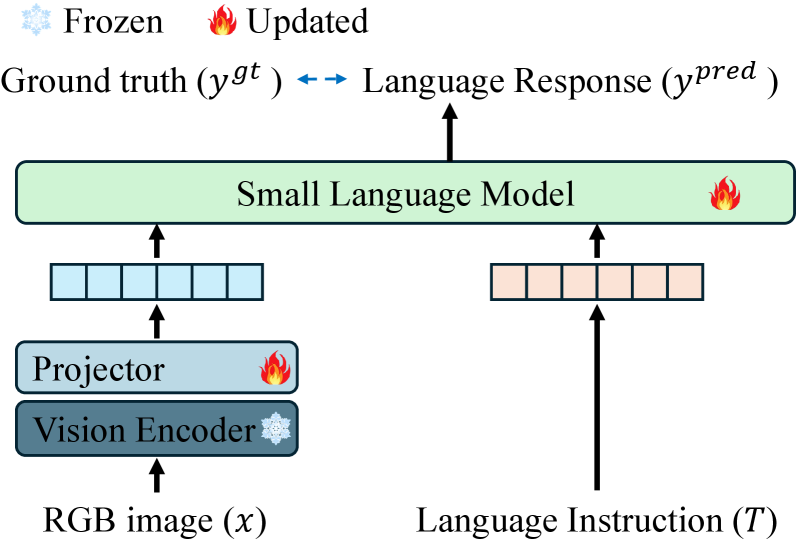
技术框架:论文的技术框架主要包括以下几个部分:1)系统指导:设计三种不同类型的系统提示,包括以动作为中心、以推理为导向以及感知-推理提示,引导VLM从不同角度理解导航任务。2)动机框架:设计三种不同的动机框架,让VLM与人类、其他AI系统或其过去的自我竞争,激发VLM的行动动机。3)实验评估:在两个社交合规导航数据集上,评估不同提示设计和动机框架对VLM导航性能的影响。
关键创新:论文最重要的技术创新点在于,提出了基于认知理论的提示工程方法,用于提升小型VLM在社交机器人导航中的社交合规性。与现有方法相比,该方法更注重利用提示来引导VLM的决策过程,而不是仅仅依赖于数据驱动的微调。这种方法能够更有效地提升VLM的动作准确性,使其在复杂社交场景下表现更好。
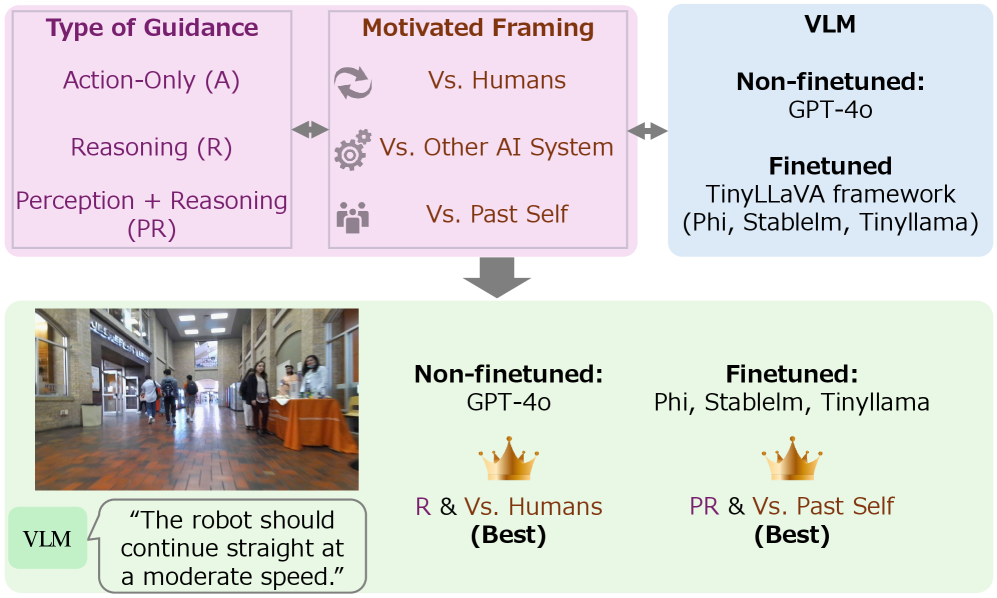
关键设计:在系统指导方面,论文设计了三种不同类型的提示:1)以动作为中心:直接给出行动指令,例如“向左转”、“向前走”。2)以推理为导向:引导VLM进行推理,例如“考虑到行人安全,你应该怎么走?”。3)感知-推理提示:结合感知信息和推理,例如“你看到前方有行人,应该如何避让?”。在动机框架方面,论文设计了三种竞争模式:1)与人类竞争:VLM的目标是超越人类的导航表现。2)与其他AI系统竞争:VLM的目标是超越其他AI系统的导航表现。3)与过去的自我竞争:VLM的目标是超越其过去的导航表现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,对于非微调的GPT-4o,与人类竞争的提示设计表现最佳。对于微调模型,与模型过去的自我竞争效果最好。更重要的是,论文发现,精心设计的系统提示能够显著提升动作准确性,甚至超过直接微调的效果,表明提示设计主要作用于决策层面,而非表征增强。
🎯 应用场景
该研究成果可应用于各种社交机器人导航场景,例如商场导购机器人、医院引导机器人、养老院陪伴机器人等。通过精心设计的提示,可以使这些机器人更好地理解人类意图,遵守社会规范,从而提升用户体验和安全性。未来,该方法还可以扩展到其他需要社交智能的机器人应用中。
📄 摘要(原文)
Language models are increasingly used for social robot navigation, yet existing benchmarks largely overlook principled prompt design for socially compliant behavior. This limitation is particularly relevant in practice, as many systems rely on small vision language models (VLMs) for efficiency. Compared to large language models, small VLMs exhibit weaker decision-making capabilities, making effective prompt design critical for accurate navigation. Inspired by cognitive theories of human learning and motivation, we study prompt design along two dimensions: system guidance (action-focused, reasoning-oriented, and perception-reasoning prompts) and motivational framing, where models compete against humans, other AI systems, or their past selves. Experiments on two socially compliant navigation datasets reveal three key findings. First, for non-finetuned GPT-4o, competition against humans achieves the best performance, while competition against other AI systems performs worst. For finetuned models, competition against the model's past self yields the strongest results, followed by competition against humans, with performance further influenced by coupling effects among prompt design, model choice, and dataset characteristics. Second, inappropriate system prompt design can significantly degrade performance, even compared to direct finetuning. Third, while direct finetuning substantially improves semantic-level metrics such as perception, prediction, and reasoning, it yields limited gains in action accuracy. In contrast, our system prompts produce a disproportionately larger improvement in action accuracy, indicating that the proposed prompt design primarily acts as a decision-level constraint rather than a representational enhancement.