TacUMI: A Multi-Modal Universal Manipulation Interface for Contact-Rich Tasks
作者: Tailai Cheng, Kejia Chen, Lingyun Chen, Liding Zhang, Yue Zhang, Yao Ling, Mahdi Hamad, Zhenshan Bing, Fan Wu, Karan Sharma, Alois Knoll
分类: cs.RO
发布日期: 2026-01-21
💡 一句话要点
TacUMI:用于接触丰富任务的多模态通用操作界面
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 多模态学习 任务分割 机器人操作 接触丰富任务 通用操作界面
📋 核心要点
- 现有方法在处理涉及复杂物理交互的操作任务时,难以仅通过视觉和机器人自身信息准确分解任务。
- TacUMI通过集成ViTac传感器、力矩传感器和姿态跟踪器,实现多模态数据的同步采集,辅助任务分解。
- 实验表明,TacUMI在电缆安装任务中实现了超过90%的分割准确率,证明了其有效性。
📝 摘要(中文)
任务分解对于理解和学习复杂的长时程操作任务至关重要。特别是对于涉及丰富物理交互的任务,仅依赖视觉观察和机器人本体感受信息通常无法揭示潜在的事件转换。这提出了对高效收集高质量多模态数据以及鲁棒分割方法的需求,以便将演示分解为有意义的模块。在手持演示设备通用操作界面(UMI)的基础上,我们引入了TacUMI,一个多模态数据收集系统,它将ViTac传感器、力矩传感器和姿态跟踪器集成到一个紧凑的、与机器人兼容的夹爪设计中,从而能够在人类演示期间同步获取所有这些模态的数据。然后,我们提出了一个多模态分割框架,该框架利用时间模型来检测顺序操作中语义上有意义的事件边界。在具有挑战性的电缆安装任务上的评估显示,分割准确率超过90%,并且随着模态数量的增加,分割准确率显著提高,这验证了TacUMI为接触丰富任务中多模态演示的可扩展收集和分割奠定了坚实的基础。
🔬 方法详解
问题定义:现有方法在处理接触丰富的操作任务时,仅依赖视觉信息和机器人自身状态难以准确捕捉任务中的事件转换,导致任务分解效果不佳。这限制了机器人学习复杂操作任务的能力,尤其是在需要精细物理交互的场景中。
核心思路:TacUMI的核心思路是通过集成多种传感器,提供更丰富的环境感知信息,从而更准确地识别任务中的事件边界。通过同步采集视觉、触觉、力和姿态等多模态数据,TacUMI能够捕捉到传统方法难以获取的物理交互细节,从而实现更鲁棒的任务分割。
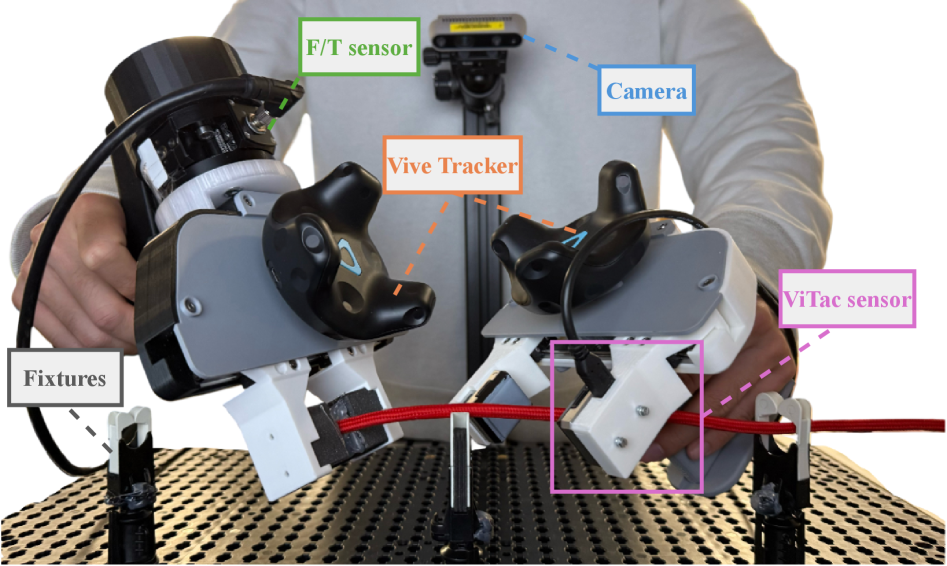
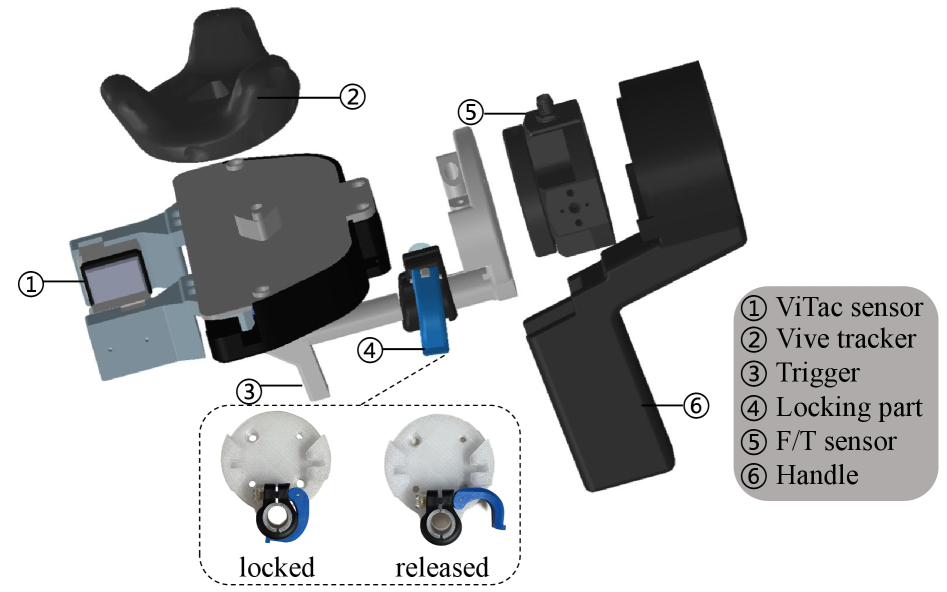
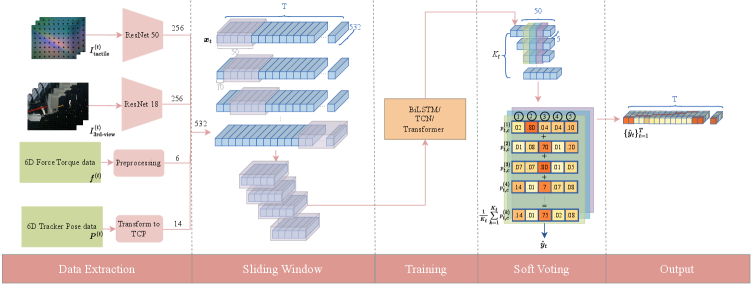
技术框架:TacUMI系统主要包含三个部分:多模态数据采集设备、多模态数据同步模块和多模态分割框架。数据采集设备是一个集成了ViTac传感器、力矩传感器和姿态跟踪器的机器人夹爪。数据同步模块负责将不同传感器的数据进行时间对齐。多模态分割框架利用时间模型(具体模型类型未知)来检测操作序列中语义上有意义的事件边界。
关键创新:TacUMI的关键创新在于其多模态数据采集设备的集成设计,以及利用多模态信息进行任务分割的框架。与传统的单模态或少模态方法相比,TacUMI能够提供更全面、更丰富的环境感知信息,从而提高任务分割的准确性和鲁棒性。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。时间模型的具体类型未知,多模态数据融合的具体方法也未知。ViTac传感器的具体型号和参数未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TacUMI在电缆安装任务中实现了超过90%的分割准确率。更重要的是,实验证明了随着模态数量的增加,分割准确率显著提高,这验证了多模态信息对于任务分割的重要性。该结果表明TacUMI能够为接触丰富任务中多模态演示的可扩展收集和分割奠定坚实的基础。
🎯 应用场景
TacUMI的应用场景广泛,包括工业自动化、医疗机器人、家庭服务机器人等领域。例如,在工业自动化中,TacUMI可以用于机器人进行精密装配、打磨抛光等任务;在医疗机器人中,可以辅助医生进行微创手术;在家庭服务机器人中,可以帮助机器人完成复杂的家务操作。TacUMI的出现为机器人学习复杂操作任务提供了新的解决方案,有望推动机器人技术的进一步发展。
📄 摘要(原文)
Task decomposition is critical for understanding and learning complex long-horizon manipulation tasks. Especially for tasks involving rich physical interactions, relying solely on visual observations and robot proprioceptive information often fails to reveal the underlying event transitions. This raises the requirement for efficient collection of high-quality multi-modal data as well as robust segmentation method to decompose demonstrations into meaningful modules. Building on the idea of the handheld demonstration device Universal Manipulation Interface (UMI), we introduce TacUMI, a multi-modal data collection system that integrates additionally ViTac sensors, force-torque sensor, and pose tracker into a compact, robot-compatible gripper design, which enables synchronized acquisition of all these modalities during human demonstrations. We then propose a multi-modal segmentation framework that leverages temporal models to detect semantically meaningful event boundaries in sequential manipulations. Evaluation on a challenging cable mounting task shows more than 90 percent segmentation accuracy and highlights a remarkable improvement with more modalities, which validates that TacUMI establishes a practical foundation for both scalable collection and segmentation of multi-modal demonstrations in contact-rich tasks.