Active Cross-Modal Visuo-Tactile Perception of Deformable Linear Objects
作者: Raffaele Mazza, Ciro Natale, Pietro Falco
分类: cs.RO
发布日期: 2026-01-20
💡 一句话要点
提出基于主动跨模态视觉-触觉融合的柔性线性物体三维重建方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 柔性线性物体 三维重建 跨模态感知 视觉触觉融合 主动探索 机器人操作 基础模型
📋 核心要点
- 现有方法在复杂环境下对柔性线缆的三维重建精度不足,易受视觉遮挡和光照变化影响。
- 该方法融合视觉和触觉信息,利用基础模型进行视觉感知,并结合触觉探索解决遮挡问题。
- 实验表明,该方法能准确重建被严重遮挡的线缆,验证了跨模态感知在柔性物体操作中的潜力。
📝 摘要(中文)
本文提出了一种新颖的跨模态视觉-触觉感知框架,用于柔性线性物体(DLOs)的三维形状重建,特别关注于视觉遮挡严重的线缆。与主要依赖视觉的现有方法不同,这些方法在光照变化、背景杂乱或部分可见的情况下性能会下降。本文提出的方法集成了基于基础模型的视觉感知与自适应触觉探索。视觉流程利用SAM进行实例分割,Florence进行语义细化,然后进行骨骼化、端点检测和点云提取。被遮挡的线缆段被自主识别,并通过触觉传感器进行探索,触觉传感器提供局部点云,并通过欧几里得聚类和拓扑保持融合与视觉数据合并。由端点引导的点排序驱动的B样条插值产生线缆形状的平滑和完整重建。使用配备RGB-D相机和触觉垫的机器人机械臂进行的实验验证表明,所提出的框架能够准确地重建简单和高度弯曲的单个或多个线缆配置,即使大部分被遮挡。这些结果突出了基础模型增强的跨模态感知在推进柔性物体机器人操作方面的潜力。
🔬 方法详解
问题定义:论文旨在解决柔性线性物体(DLOs),特别是线缆在存在严重视觉遮挡情况下的三维形状重建问题。现有方法主要依赖视觉信息,但在光照变化、背景杂乱或部分遮挡的情况下,性能会显著下降,难以保证重建精度和完整性。
核心思路:论文的核心思路是融合视觉和触觉信息,利用视觉感知快速获取可见部分的形状信息,并利用触觉探索来补充被遮挡部分的形状信息。通过主动的触觉探索,可以克服视觉遮挡带来的问题,从而实现更完整和准确的三维重建。
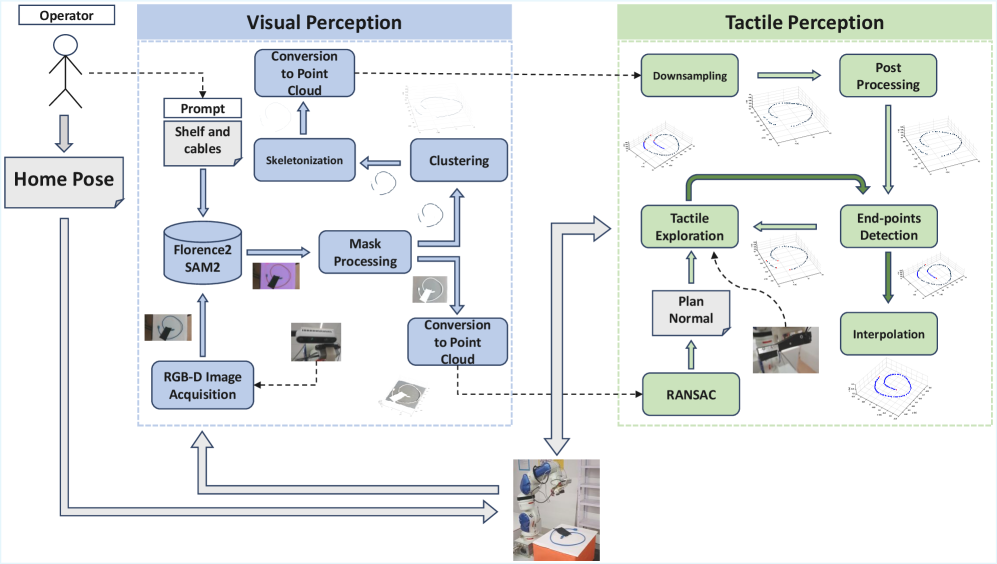
技术框架:整体框架包含视觉感知和触觉探索两个主要模块。视觉感知模块首先利用SAM进行线缆的实例分割,然后使用Florence进行语义细化,接着进行骨骼化、端点检测和点云提取。对于视觉遮挡的部分,系统会自主地控制机器人进行触觉探索,触觉传感器获取局部点云,并通过欧几里得聚类和拓扑保持融合算法与视觉数据进行融合。最后,使用B样条插值,并由端点引导点排序,生成平滑且完整的线缆形状重建。
关键创新:该方法最重要的创新点在于主动跨模态感知策略,即根据视觉感知的结果,自主地规划触觉探索的路径,从而有效地解决视觉遮挡问题。此外,利用基础模型(SAM和Florence)进行视觉感知,提高了在复杂环境下的分割和语义理解能力。与传统方法相比,该方法不再完全依赖视觉信息,而是通过视觉和触觉的协同作用,实现了更鲁棒和准确的重建。
关键设计:在触觉探索方面,采用了自适应的探索策略,根据视觉感知的结果动态调整触觉探索的范围和力度。在数据融合方面,使用了欧几里得聚类和拓扑保持融合算法,保证了融合后的点云的拓扑结构与原始数据一致。B样条插值使用端点引导的点排序,确保了重建后的线缆形状与实际形状一致。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够准确重建被严重遮挡的单个或多个线缆,验证了其在复杂环境下的鲁棒性。即使在大部分线缆被遮挡的情况下,该方法仍然能够有效地重建线缆的形状,证明了跨模态感知的优势。具体的性能数据和与其他基线的对比结果(如有)未知。
🎯 应用场景
该研究成果可应用于自动化线缆布线、机器人辅助手术、柔性物体操作等领域。在自动化线缆布线中,机器人可以利用该方法识别和操作复杂的线缆,提高布线效率和准确性。在机器人辅助手术中,医生可以通过触觉反馈更精确地操作柔性导管,提高手术安全性。该研究为机器人操作柔性物体提供了新的思路,具有重要的实际应用价值。
📄 摘要(原文)
This paper presents a novel cross-modal visuo-tactile perception framework for the 3D shape reconstruction of deformable linear objects (DLOs), with a specific focus on cables subject to severe visual occlusions. Unlike existing methods relying predominantly on vision, whose performance degrades under varying illumination, background clutter, or partial visibility, the proposed approach integrates foundation-model-based visual perception with adaptive tactile exploration. The visual pipeline exploits SAM for instance segmentation and Florence for semantic refinement, followed by skeletonization, endpoint detection, and point-cloud extraction. Occluded cable segments are autonomously identified and explored with a tactile sensor, which provides local point clouds that are merged with the visual data through Euclidean clustering and topology-preserving fusion. A B-spline interpolation driven by endpoint-guided point sorting yields a smooth and complete reconstruction of the cable shape. Experimental validation using a robotic manipulator equipped with an RGB-D camera and a tactile pad demonstrates that the proposed framework accurately reconstructs both simple and highly curved single or multiple cable configurations, even when large portions are occluded. These results highlight the potential of foundation-model-enhanced cross-modal perception for advancing robotic manipulation of deformable objects.